 English
EnglishStockage dans le cloud
Le stockage dans le cloud est un modèle de stockage de données informatiques dans lequel les données numériques sont stockées dans un regroupement logique. On distingue trois catégories de stockage :
Stockage par blocs
Les données sont stockées dans des blocs sur un ou plusieurs disques attachés localement. Ce type de stockage est utilisé pour les bases de données, les ERP, etc. Les données sont découpées en blocs pour faciliter la gestion des données.
Stockage de fichiers
Les données sont stockées sous forme de fichiers dans des dossiers appartenant à une arborescence à travers un partage réseau (NAS).
Stockage d'objets
Les données sont stockées en tant qu'objet identifié par une clé et un fichier plat. On accède à ces données via une API en ciblant une clé.
Les services de stockage dans le cloud proposés par Amazon sont :
- Amazon RDS : service de base de données relationnelles (Amazon Elastic Block Store)
- Amazon Glacier : service de stockage froid pour les archives (Amazon S3)
- Amazon CloudFront : déplace les objets au plus près des utilisateurs (Amazon S3)
Amazon Elastic Block Store
Amazon Elastic Block Store (EBS) est un stockage en mode bloc directement attaché au serveur. Ce service offre une latence extrêmement faible requise pour les charges de travail à hautes performances. Les caractéristiques d'EBS sont :
- Les données sont découpées en blocs de taille fixe (4 Ko)
- Une table d'allocation est nécessaire pour localiser les données
- La lecture et l'écriture se font au niveau des blocs
- Utilisation des protocoles : HDD SAS, ISCSI, FC, FCoE
- Données persistantes, consistantes, accessibles à faible latence : volumes EBS
- Données répliquées dans une seule zone de disponibilité
- Sauvegarde sous forme de snapshot ou instantanés à un temps donné
- Chiffrement en temps réel (AES-256)
- Taille évolutive de manière dynamique
- Un volume par instance, mais plusieurs volumes pour une instance
Les avantages d'EBS sont :
- Performances pour n'importe quelle charge de travail, répond à presque tous les besoins
- Les volumes EBS sont 20 fois plus fiables que les lecteurs de disque classiques (durabilité)
- L'évolution de nos disques est presque illimitée
- Facilité d'utilisation via le Web CLI
- Paiement à l'usage : on paie notre provision, si on prend 16 To ce sont nos ressources. C'est donc ce que l'on paiera
- Élasticité : on prend 500 Go, puis on veut étendre l'élasticité de ce volume
- Sécurisé : on peut chiffrer les données, à travers les couches...
- 5 Go/s
- Indépendant d'une instance, peut être détaché et attaché à une autre instance à chaud
Les cas d'utilisation d'EBS sont :
- Continuité de l'activité
- Applications d'entreprise
- Base de données NoSQL
- Moteurs d'analyse Big Data
- Base de données relationnelles
- Systèmes de fichiers et flux
Amazon Elastic File System
Le stockage de fichiers dans le cloud est une méthode de stockage des données qui permet aux serveurs et aux applications d'accéder aux données via des systèmes de fichiers partagés. Les données sont stockées sous forme de fichiers dans un système de stockage hiérarchique (avec une arborescence). Ces données sont accessibles au moyen d'un accès partagé aux données. De nombreuses instances peuvent simultanément accéder au volume EFS et appliquer des actions CRUD sur des fichiers en même temps. On utilise le protocole NTSv4, qui permet de présenter les fichiers aux utilisateurs.
Avantages
- Stockage de fichiers partagés compatible POSIX : norme qui permet d'attribuer des accès aux utilisateurs, aux groupes, aux régions, etc. Cela s'applique au niveau du fichier et du dossier.
- Performances évolutives : jusqu'à 500 000 IOPS.
- Service entièrement géré : on a juste à profiter du service, le reste est géré par AWS.
- Sécurité et conformité.
- Consommation à la demande : cela se fait en fonction de la quantité de données fournies.
- Modes MAX IO (jusqu'à 500 000 IOPS, pour des applications ayant besoin de la bande passante maximale) et General.
- Migration possible avec EFS File Sync, permettant de paralléliser les copies et d'optimiser les données.
- Pas de frais pour l'accès aux données et aux requêtes.
- Débit allant jusqu'à 10 Go/s.
Cas d'utilisation
- Stockage de conteneurs : on peut provisionner l'utilisation en fonction de l'utilisation, ce qui rend l'utilisation de Kubernetes.
- Médias et divertissements.
- Analyse et machine learning : big data, analyse sur de grosses quantités de données.
- Sauvegardes de bases de données.
- Services Web et gestion de contenu.
- Passer aux systèmes de fichiers gérés.
⚠️ Attention : EFS n'est pas supporté pour Amazon Windows, utilisez EFSX. Le client NFS pour Linux est requis pour monter la cible EFS !
Amazon Simple Storage Service
Le stockage d'objet est idéal pour créer des applications modernes de bout en bout qui exigent une mise à l'échelle et de la flexibilité. S3 permet d'importer des magasins de données existants à des fins d'analyse, mais aussi pour la sauvegarde ou l'archivage. On utilise une structure plate non hiérarchique, avec la capacité d'utiliser des compartiments et des clés en guise d'arborescence. Toutefois, dans la structure réelle des données, elles sont toutes au même niveau. Cette manière de faire est très efficace pour les applications "Cloud Native", qui sont des applications de type DevOps ou en d'autres mots, des applications qui sont découplées (microservices). Dans cette hiérarchie, l'ensemble des compartiments est bien sûr sécurisé avec des gestions d'accès. Il existe des classes de stockage avancées :
- S3 standard : permet d'accéder rapidement à la donnée.
- S3 IA : permet de déposer des données moins fréquemment consultées.
- Glacier : qui est un archivage, dont les données ne sont jamais accédées. On peut donc créer des cycles de vie intelligents, qui gèreront l'accès à des ressources. Ainsi, si une donnée n'est pas accédée pendant un certain temps, cela veut dire que l'on peut archiver cette donnée.
Dans S3, il n'y a pas de région, c'est un service dit global. Pour autant, il est compris dans un compartiment que l'on nomme.
Concernant le dépôt des données, il est important de migrer ces données. Dans certains temps pour récupérer des données ou uploader des données, nous devons attendre longtemps. Pour accélérer ce temps d'attente, nous pouvons utiliser un Snowball, qui est un serveur sécurisé militaire. Ce serveur est envoyé chez vous, vous récupérez les données que vous renvoyez ensuite à AWS avec vos copies de données que mettra AWS sur votre S3. Pour accéder à nos données, cela se fait via une clé valeur, où la taille maximum d'un objet est de 5 To.
Avantages
- Performance, scalabilité et disponibilité.
- Durabilité de 99,999999 % grâce à la réplication dans 6 zones de disponibilité.
- Tiering intelligent et access points : on peut déplacer la donnée vers des stockages de moins en moins chers.
- Capacités de sécurité (chiffrement des données avec SSE), de conformité et d'audit.
- Gérer facilement vos données et vos contrôles d'accès.
- Services de requêtes sur place pour l'analyse : S3 permet à des outils de directement venir se connecter et d'appliquer des traitements sur les objets.
- Service de stockage dans le cloud le plus pris en charge.
- Pas de limite de stockage.
- Les données sont consistantes : quand je copie une donnée, on est sûr qu'elle est dans la bonne version, mais il peut y avoir un delta de temps en cas de mise à jour.
- S3 Transfer accélère les vitesses de transfert.
- S3 Inventory et Balise : permettent de rechercher facilement des objets.
Cas d'utilisation
- Lacs de données et analyse de Big Data.
- Données d'application natives cloud : si on veut que des utilisateurs déposent des images, par exemple.
- Stockage hybride dans le cloud : on utilise un service qui travaille avec S3, dont le besoin est d'accélérer le traitement par une - synchronisation entre les services.
- Sauvegarde et restauration.
- Reprise en cas de sinistre.
- Archivage.
Un point important est que le versioning permet de stocker plusieurs versions d'un objet, mais cela n'est pas toujours rentable. En effet, on est facturé sur le volume total occupé, plusieurs versions de plusieurs objets lourds peuvent coûter cher.
Il est important de noter que pour accéder à S3, il est nécessaire de disposer d'une clé d'accès et d'un identifiant d'utilisateur. En outre, pour protéger les données stockées dans S3, il est recommandé d'utiliser le chiffrement SSE (Server-Side Encryption) d'AWS. Cela permet de protéger les données à la fois lorsqu'elles sont stockées et lorsqu'elles sont en transit.
Amazon S3 est un service de stockage d'objet très performant, scalable et disponible dans le monde entier. Il offre des avantages tels que la durabilité, la sécurité, la conformité et l'audit, ainsi que des capacités de requêtes sur place pour l'analyse des données. Il est utilisé dans de nombreux cas d'utilisation tels que les lacs de données, les analyses de Big Data, les données d'application natives cloud, la sauvegarde et la restauration, la reprise en cas de sinistre et l'archivage.
Stockage de Bases de données dans AWS (RDS / DynamoDb)
Il existe deux grands services :
- RDS : Relational Database Service (bases de données relationnelles)
- DynamoDB : NoSQL
La grande différence est représentée par le schéma :
- Avec un schéma SQL, on utilise un langage de requête structuré. La structure et le type de données sont rigides, on ne peut pas les modifier et sont fixés à l'avance.
- Avec du NoSQL, on stocke des structures de fichiers représentant nos données.
DMS
Les gros avantages de RDS :
- Tarification à l'usage : on peut mettre en place une base de données en quelques clics.
- Modèle de gestion partagé : AWS gère toutes les tâches chronophages et complexes.
- Support des principaux acteurs de l'industrie (Aurora, PostgreSQL, MySQL, MariaDB, Oracle, SQL Server).
- Permet de conserver l'usage des outils habituels.
- Accélère les performances et la continuité de service.
- Permet aux clients de se concentrer sur leurs métiers.
- Réplication et sauvegarde.
- Permet de réaliser des exports de base de données.
- Haute disponibilité : on a une bascule applicative en cas d'indisponibilité.
- Réplicas en lecture : une croissance imprévue en lecture n'est pas un souci.
- Chiffrement avec les clés KMS ou CloudHSM.
- Gestion des accès avec IAM, alors que les accès aux instances se font via des groupes de sécurité de base dédiés.
À retenir que nous avons plusieurs services.

💡 Amazon Redshift est 65% moins cher et vachement poussé par AWS à être utilisé
DynamoDB
Les bases de données clé-valeur sont optimisées pour des modèles d'accès communs, généralement pour stocker et récupérer de grands volumes de données. Ces bases de données garantissent des temps de réponse rapides, même lors du traitement de volumes extrêmement importants de demandes simultanées. Depuis 2009, les bases de données NoSQL sont très demandées et utilisées, notamment dans les jeux vidéo, ce qui amène des performances d'écriture et de chargement énormes.
💡 Si l'on entend parler de bases de données serverless, on parlera de DynamoDB pour des traitements importants.
Amazon Elasticache (in memory)
Les bases de données en mémoire sont utilisées pour les applications qui nécessitent un accès en temps réel aux données. En stockant les données directement en mémoire, ces bases de données fournissent une latence en microsecondes aux applications pour lesquelles la latence en millisecondes n'est pas suffisante. Il existe deux types :
- Elasticache for Redis
- Elasticache for Memcached
💡 Si l'on parle de microsecondes ou de latences inférieures à la milliseconde, on parle d'Elasticache en mémoire.
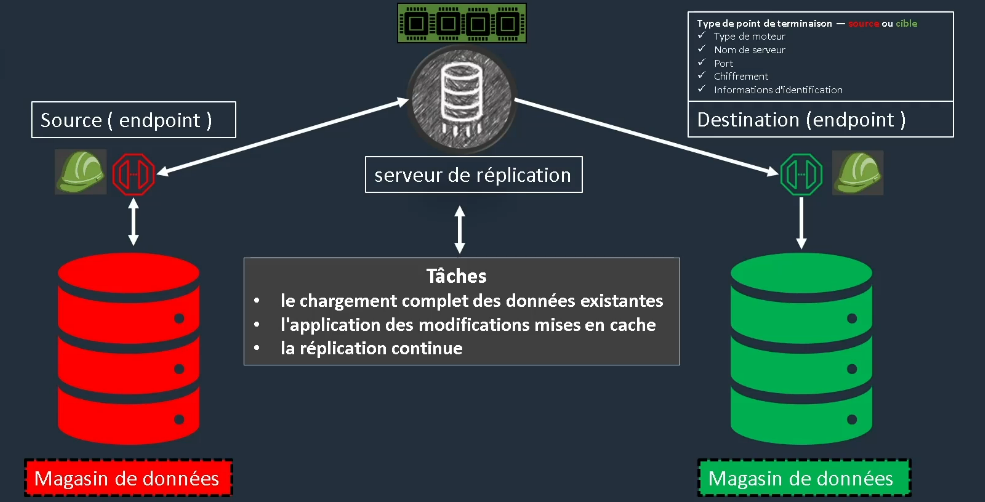
Database Migration Service (DMS)
Il n'y a rien de vraiment magique dans DMS. On va avoir un serveur de réplication, entouré de deux endpoints. Chaque endpoint comprend :
- Le type de moteur
- Le nom du serveur
- Le port
- Le chiffrement
- Les informations d'identification
Migration de base de données avec DMS
L'objectif de DMS est de migrer une base de données vers le cloud. Pour cela, on commence avec une base de données de part et d'autre, puis on fait une mise en symétrie pour que les deux bases soient identiques. On réplique donc la base de données en production dans le cloud et cela permet de migrer.
Il faudra fournir un rôle dans l'IAM pour les utilisateurs qui réaliseront cette migration. Une fois que cela est fait, le processus d'inscription établira un lien vers le premier data store pour le répliquer vers un deuxième data center sur une instance dédiée. Il y a dès lors 3 tâches distinctes :
- Le chargement complet des données existantes
- L'application des modifications mises en cache
- La réplication continue
CloudFront
CloudFront est un service qui permet de fournir du contenu aux utilisateurs finaux avec une latence plus faible en exploitant un réseau mondial de 216 points de présence, déployé dans 84 villes de 42 pays, ce qui augmente la disponibilité. Il offre une protection contre les attaques des couches réseau et application en augmentant la surface pour permettre aux utilisateurs d'échanger avec différents edges. La sécurité est également assurée par le chiffrement SSL/TLS et HTTPS, ainsi qu'un contrôle d'accès avec des URLs et des cookies signés. En termes de sécurité, CloudFront couvre l'ensemble des besoins de conformité, ce qui rend le service encore plus attractif.
Il est possible d'activer la redondance pour les origines, ce qui permet d'optimiser la continuité de service. Autrement dit, quand une ressource ne fonctionne plus, on aura la possibilité d'utiliser un autre edge.
Étant un service qui se met à l'échelle, il propose des outils pour fournir la disponibilité de larges ressources telles que :
- Grandes bibliothèques
- Ressources multimédias
- Streaming
Vous ne payez que ce que vous consommez ! Il existe également d'autres outils tels que :
- Des APIs complètes
- Des outils DevOps
Storage Gateway
Storage Gateway est un service hybride qui permet de connecter vos environnements sur site existants au cloud AWS pour augmenter les performances. Il stocke les données en local, mais les réplique rapidement. Il propose :
- Une passerelle de fichiers, qui propose une interface de fichier permettant de stocker des fichiers en tant qu'objets dans S3.
- Une passerelle de bande présentant à notre application de sauvegarde existante une bibliothèque de bandes virtuelles (VTL).
- Une passerelle de volume qui affiche les volumes de stockage par bloc de vos applications à l'aide du protocole iSCSI. On fera des snapshots des volumes, mais aussi des réplications de ces volumes.
Services Analytics
EMR
EMR est une plateforme leader de Big Data dans le cloud dédiée au traitement de grandes quantités de données à l'aide d'outils open source basés sur la technologie Hadoop :
- Apache Spark
- Apache Hive
- Apache HBase
- Apache Flink
- Apache Hudi
- Presto
On peut alors provisionner un cluster Hadoop pour travailler ensemble sur toutes ces tâches de machine learning, d'indexation de données, etc. La plateforme est très économique, car elle provisionne uniquement en fonction des tâches.
Kinesis
Kinesis facilite la collecte, le traitement et l'analyse de données en streaming en temps réel, afin d'obtenir rapidement des informations stratégiques et de réagir rapidement. Kinesis va réaliser des flux et créer des canaux en simultané. On peut via des APIs avoir accès à des données et dire que les requêtes sont des entrées streamées dans un flux Kinesis.
Le service peut alors recevoir des centaines de milliers de données, et il sera possible de les sélectionner pour ne conserver que les données qui nous intéressent. On fait donc du Big Data en temps réel.
Athena
Athena est un service de requête interactif qui facilite l'analyse des données dans Amazon S3 à l'aide de la syntaxe SQL standard. Athena fonctionne sans serveur, il n'existe aucune infrastructure à gérer et vous ne payez que pour les requêtes que vous exécutez. C'est un service serverless, qui est totalement géré et sécurisé par l'IAM ! L'objectif est d'aller chercher dans nos données et de payer uniquement pour nos requêtes.





