 English
EnglishRecurrent Neural Networks
To understand this, we need to understand our brain:
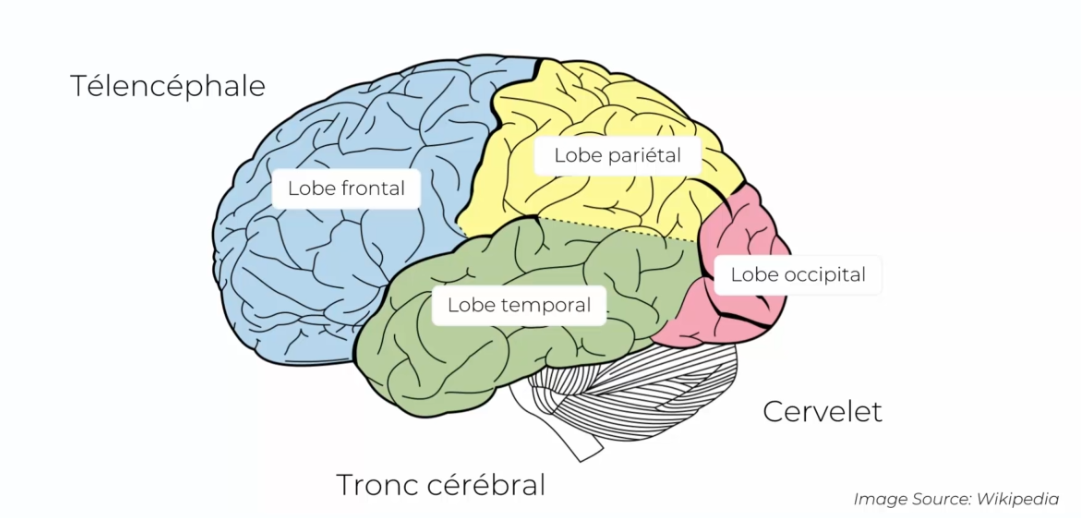
Our brain, or at least the Telencephalon part, is composed of 4 parts:
- Frontal lobe
- Parietal lobe (sensation perception)
- Temporal lobe
- Occipital lobe
When we create a neural network, we have a notion of weights that are attached to each synapse to optimize our predictions. We can see these weights as a long-term memory, the brain doesn't forget with time: you learn to ride a bike, your attempts remain engraved in your memory. This implies that this part represents our Temporal lobe. So we find it in all neural networks, but more particularly in the ANN whose specialty it is.
When using convolutional neural networks, this network made it possible to recognize images. We then talk about our human vision which is directly interpreted by the Occipital lobe.
Our recurrent neural network corresponds to our short-term memory. This neural network knows very well what has happened recently and will use it to predict what will happen later, it represents the Frontal lobe.
OK, but how does it work?
Let's start with a normal neural network:
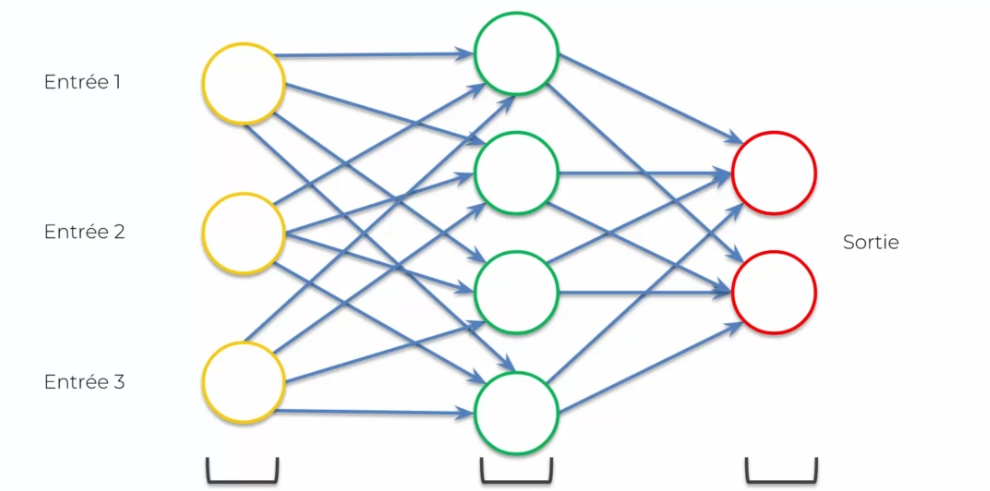
We're going to first flatten it:
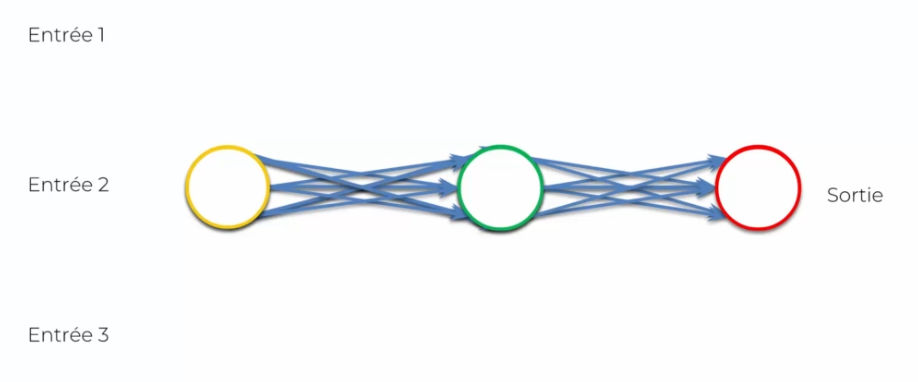
We might think that we've lost information, but in reality everything is still there, nothing has changed. In fact, this is just a different visualization, but we can still simplify it to see this network differently:
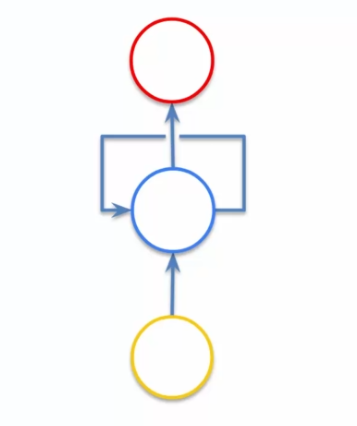
Our hidden network in the middle creates a time loop. Basically, the hidden network outputs the information, but reuses this information immediately after. It's a bit abstract, so let's look at it from a different perspective:
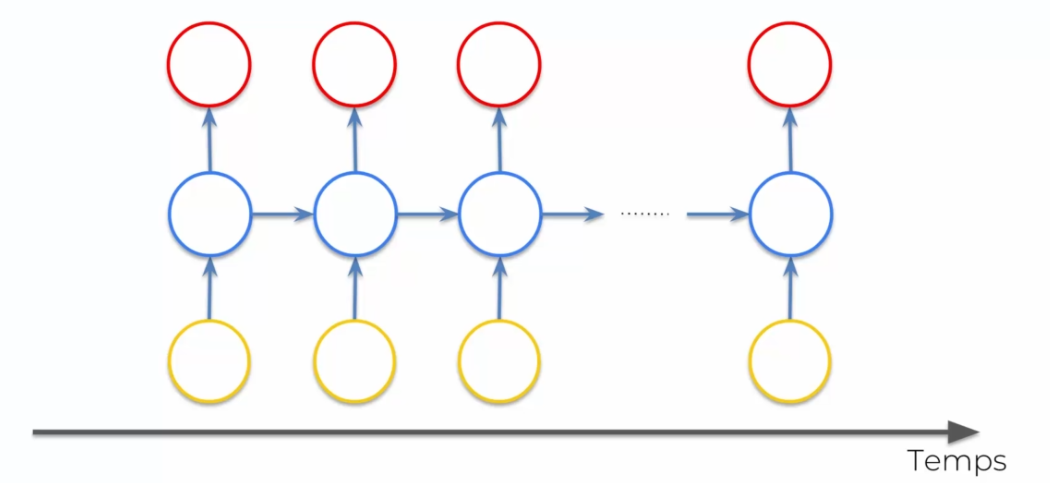
The principle here is that information is constantly reused over time, even after it has been processed. We can have:
- One-to-many: one input to several outputs. Example: we try to describe an image and if the image corresponds to a cat or a dog. The role of the RNN will be to create a correct sentence, not to analyze the image.
- Many-to-one: several inputs to one output. Example: the analysis of a text which allows to bring out whether this text is negative or positive. Here, it needs to understand the sentence to give an analysis.
- Many-to-many: several inputs to several outputs. Example: Google Translate, where we have several words to translate and grammatical rules to follow, gender agreement for example...
Vanishing gradient
When using the gradient algorithm, we tried to minimize the cost. What happened in an RNN was that we calculated the cost function and used backpropagation to apply the gradient afterwards (see). In this case, it's different, we do backpropagation in multiple directions, so we have neurons that update on a lot of steps backward: 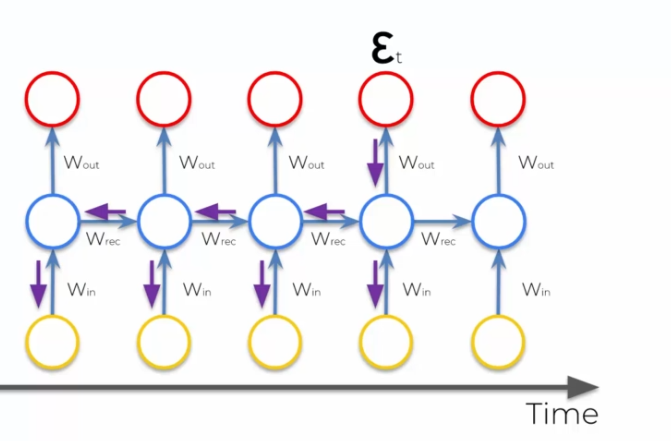
So we have a multiplication of our gradient that is high at the beginning, which we then multiply by small values (values between 0 and 1), which will make it smaller and smaller. This poses a problem, because the gradient that is there to update becomes increasingly useless for distant networks, as they will not be sufficiently trained.
So we will have half of the network trained and the other half using as output the untrained part, which creates bad information. We have a domino effect that is created, and huge error rates.
Long Short-Term Memory
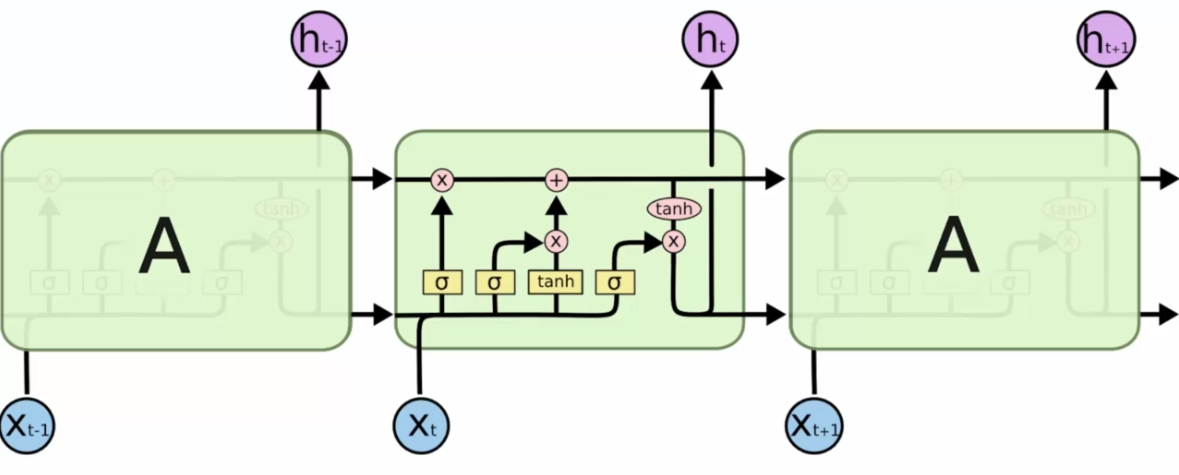
- Arrows are vector transfers
- When two arrows cross, we have a concatenation
- When two arrows separate, we have a copy
- The pink circles correspond to a valve system, as in electricity, we can choose to open or close them
- The yellow rectangles are hidden layers
How it works
We have two inputs, these two inputs enter a hidden network, here sigmoid, which will determine whether we open the valve or not. We decide whether or not to interrupt the path of memory:
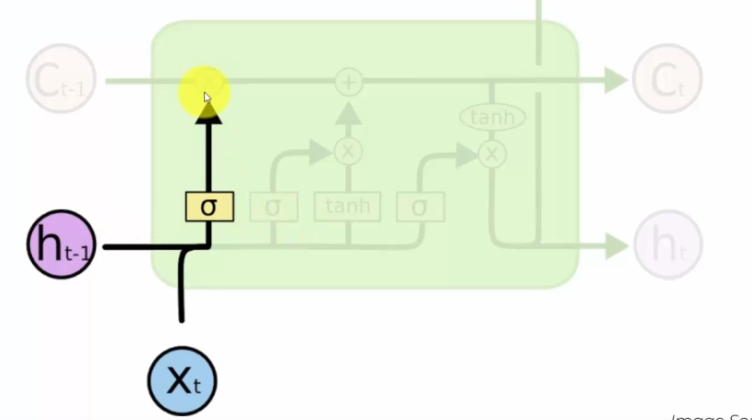
Xt is the new incoming information in our neuron. Thus Ht-1 represents the output of the previous neuron. Here we talk about the forget valve, in other words, we consider that the passing information, if the valve is open, can be forgotten.
The next step is to determine which values will be passed through the hyperbolic tangent and to know whether or not we open the valve (sigmoid). This makes it possible to add information to the memory:
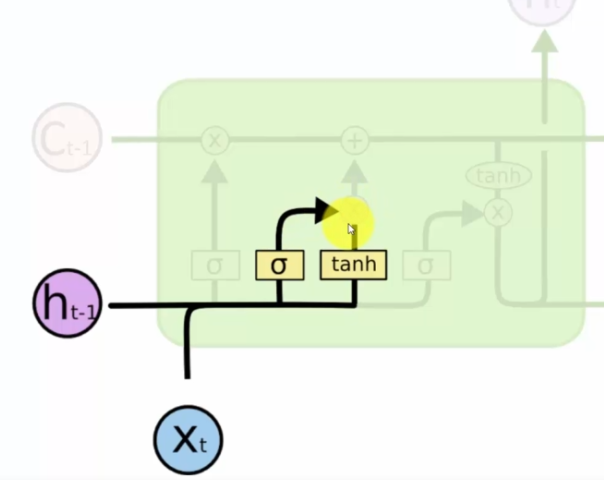
We then talk about the memory valve, which if open will be added to the value of Ct-1, which corresponds to the past memory from neuron to neuron.
We then determine which part of the memory will go into the output:
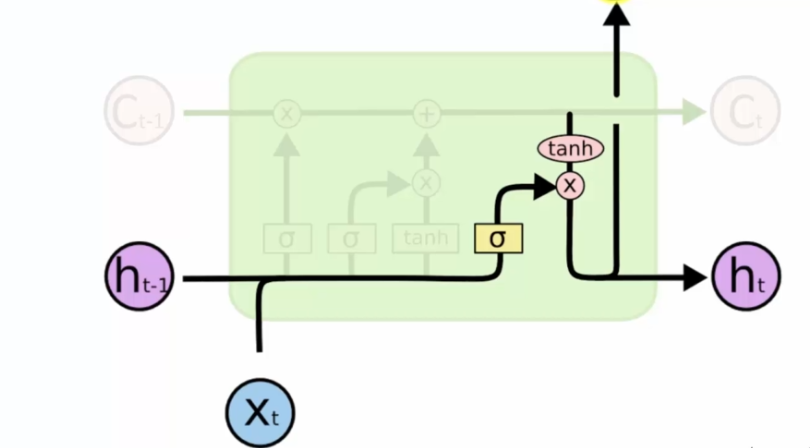
We are therefore in a crucial system that will determine the output or not:
- Towards memory
- Towards the output, in this case the value is communicated to the next neuron by Ht
Thus, we have several conditions that allow the neural network to interpret text. Each neuron becomes responsible for a part of the interpretation:
- A neuron to identify URLs
- A neuron to identify special words
- A neuron to identify the tone of a word (aggressive, friendly, etc.)
In short, a whole series of neurons that specialize in learning and interpreting text. That is why in our case, the notion of memory is very important. Indeed, it will allow the neuron to remember, line by line, the different previous steps.
Here we have the prediction of a neuron on characters:
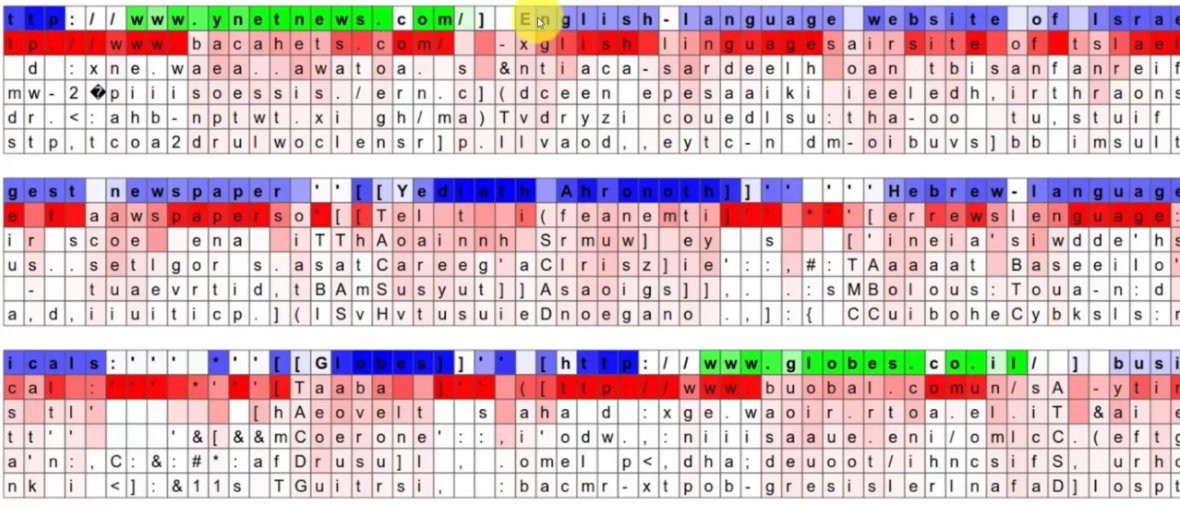
It starts with the first line of the text:
- In green, we have good predictions and therefore let the output pass (the value is close to 1)
- In blue, we have bad predictions and therefore do not let the information pass to the output (the value is close to -1)
- In white, it has no prediction
It continues on the second line:
- We clearly see that this neuron specializes in reading URLs.
- We say that: on the second line, when the character is red, the neuron is "almost sure" of its prediction. Certainty is marked by a more significant red.
Variations of LSTMs
Variation number 1
It happens that we add lines in our neurons: 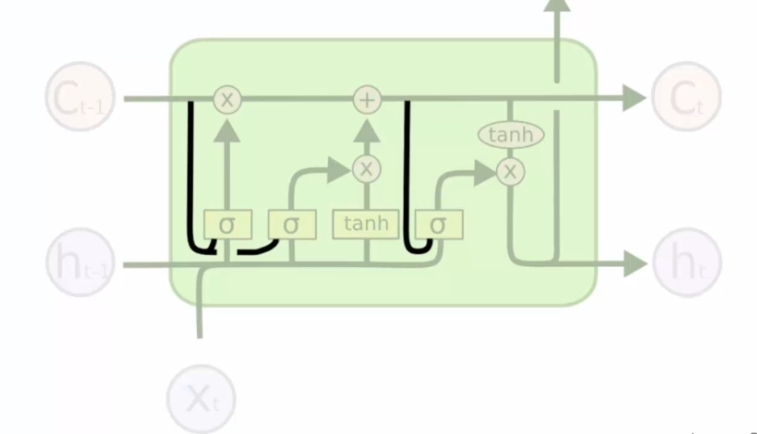
This allows us to take memory (Ct-1) into account to influence decisions. Memory in this case has a say.
Variation number 2
We connect the forget valve (the one at the top left, X) with memory:
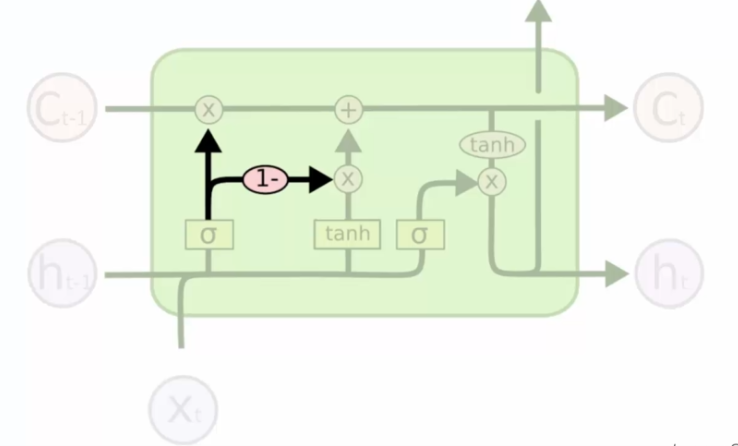
Previously we had the possibility to cut memory to the left and right and add information to memory. Now instead of that, we have a decision for both valves at the same time. The decision is not the same:
- We open memory, this closes the forget valve
- We open the forget valve, we close the memory valve
Variation number 3
We remove the memory line (Ct+1), instead we put the output information of the previous network (Ht-1):
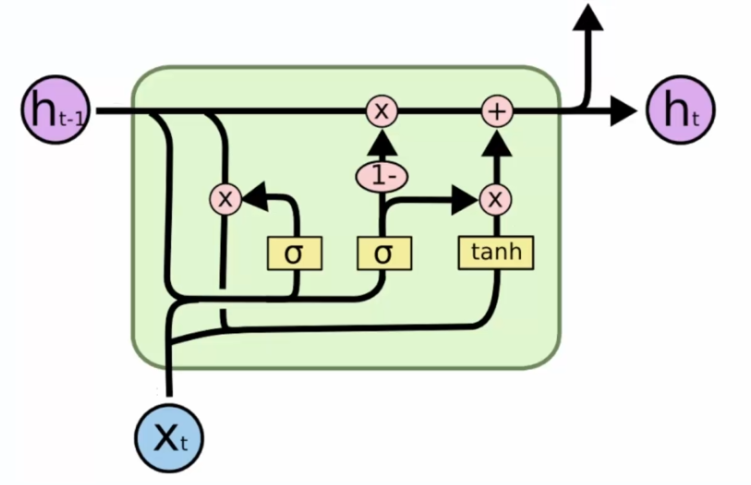
Therefore, we have only one value that comes from the previous memory, there are fewer things to control.
Neural Network Evaluation
For regression, we evaluate the model's performance using RMSE (Root Mean Squared Error). The RMSE is calculated by taking the square root of the average of the differences squared between the predictions and the actual values. The RMSE is by default a good measure of performance. To apply it, we can use the following code:
import math
from sklearn.metrics import mean_squared_error
rmse = math.sqrt(mean_squared_error(real_stock_price, predicted_stock_price))
Improvement
- Get more data: we trained the model on 5 years of data, but we could try with 10 years of data.
- Increase the number of timesteps: we chose 60 in the videos, which corresponds to about 3 months in the past. We could increase this number, for example to 120 (6 months).
- Add other indicators: do you know of other companies whose stock could be correlated with Google's? We could add these stocks to the training data.
- Add more LSTM layers: we already have 4 layers, but perhaps with even more layers, we could get better results.
- Add more neurons in each LSTM layer: we used 50 neurons to capture a certain complexity in the data, but is it enough? We could try with more neurons.





