 English
EnglishIntroduction
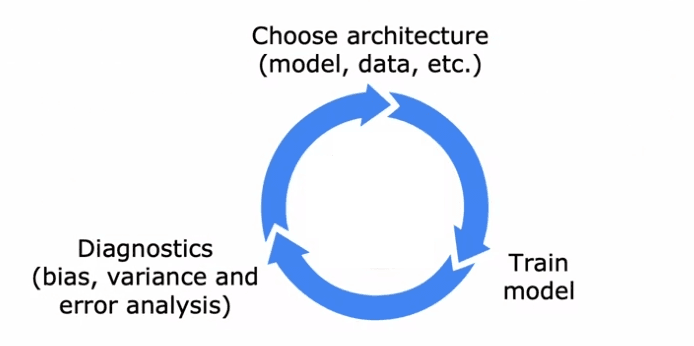
Le développement d'un système d'apprentissage machine peut être un processus complexe et itératif. Il implique le choix de l'architecture globale du système, la décision sur les données et les hyperparamètres à utiliser, et la mise en œuvre et la formation d'un modèle. Cependant, la première itération d'un modèle ne fonctionne souvent pas aussi bien que désiré. Pour améliorer les performances, il est nécessaire d'utiliser des diagnostics tels que l'analyse du biais et de la variance de l'algorithme et la conduite d'une analyse d'erreur. Sur la base des insights de ces diagnostics, des décisions peuvent être prises sur la façon d'ajuster l'architecture, telles que l'augmentation de la taille du réseau neuronal ou le changement du paramètre de régularisation. Ce processus est alors répété jusqu'à ce que les performances souhaitées soient atteintes.
Un exemple de ce processus peut être vu dans le développement d'un classificateur de courrier indésirable. Les courriers indésirables contiennent souvent des mots mal orthographiés et des tentatives de vente de produits, alors que les courriels légitimes n'en font pas. Une façon de construire un classificateur pour ce problème est de former un algorithme d'apprentissage supervisé en utilisant le texte du courriel comme caractéristiques d'entrée et l'étiquette de spam ou de non-spam en sortie. Les caractéristiques du courriel peuvent être construites de différentes façons, telles que l'utilisation des 10 000 mots les plus fréquents en anglais comme indicateurs binaires de leur apparition ou non dans le courriel, ou en comptant le nombre de fois où un mot donné apparaît.
Une fois le modèle initial formé, il existe de nombreuses façons potentielles d'améliorer sa performance. Par exemple, on peut collecter plus de données, développer des fonctionnalités plus sophistiquées ou créer des algorithmes pour détecter les fautes d'orthographe. Cependant, il peut être difficile de déterminer lesquelles de ces idées sont les plus prometteuses. En analysant le biais et la variance de l'algorithme et en effectuant une analyse d'erreur, il est possible de déterminer les zones du modèle qui ont le plus besoin d'amélioration et de prendre des décisions plus éclairées sur la façon de procéder. Cela peut grandement accélérer le processus de développement et améliorer la performance globale du modèle.
L'analyse d'erreurs
Diagnostiquer les performances d'un algorithme d'apprentissage est crucial pour l'améliorer. Il y a deux concepts importants dans ce contexte : le biais et la variance et l'analyse des erreurs. Dans cet article, nous plongerons dans ce que signifient ces deux concepts et comment ils peuvent vous aider à choisir quoi faire pour améliorer les performances de votre algorithme d'apprentissage.
Le biais et la variance sont des concepts importants pour comprendre les performances d'un algorithme d'apprentissage. Le biais fait référence à l'erreur introduite par la simplification de données du monde réel avec un modèle plus simple. La variance fait référence à la quantité d'erreur introduite par la complexité du modèle. Un biais élevé et une faible variance indiquent un sous-ajustement, tandis qu'une variance élevée et un faible biais indiquent un sur-ajustement.
L'analyse des erreurs, d'un autre côté, est le processus de vérification manuelle des exemples mal classifiés par l'algorithme. Cela vous aide à comprendre où l'algorithme se trompe. Pour effectuer une analyse des erreurs, prenez un ensemble d'exemples mal classifiés de l'ensemble de validation croisée et essayez de les regrouper en thèmes ou propriétés communs. Par exemple, si de nombreux exemples mal classifiés sont des e-mails de spam pharmaceutiques, comptez combien il y en a et essayez de trouver des traits communs. Ce processus peut révéler des domaines où votre algorithme d'apprentissage est faible et où des améliorations peuvent être apportées.
Adding data
Data Augmentation for Machine Learning Applications
Machine learning algorithms are often limited by the amount of data they can use for training. This is why data augmentation techniques can come in handy to increase the size of the training set and help improve the performance of these algorithms. In this article, we'll explore some tips for adding data to your machine learning application, including data augmentation techniques.
Adding Data
One of the most straightforward ways to add data is simply to get more examples of everything. However, this approach can be slow and expensive. A more efficient alternative is to focus on adding more data of the types where error analysis has indicated it might help. For example, if you're training a machine learning algorithm to recognize pharmaceutical spam and it's struggling with that task, you might focus on adding more examples of pharmaceutical spam rather than just trying to get more data of all types.
Data Augmentation
Data augmentation is a technique for creating new examples from existing training data, which can significantly increase the size of your training set. This technique is often used for images and audio data.
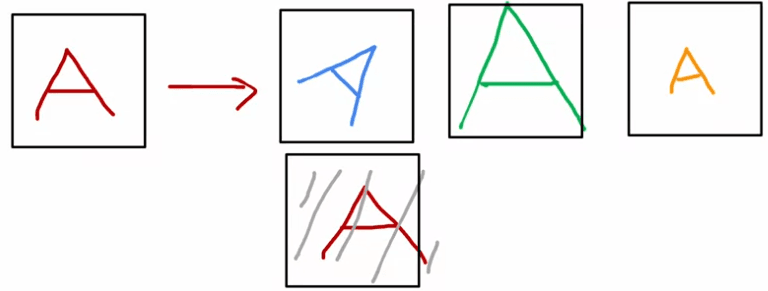
For example, if you're training an optical character recognition algorithm to recognize letters from A to Z, you might use data augmentation to create new training examples from a single image of the letter A. This could include rotating the image, enlarging or shrinking it, changing its contrast, or even taking its mirror image. By doing this, you're telling the algorithm that the letter A is still the letter A, even when it's rotated or distorted in other ways.
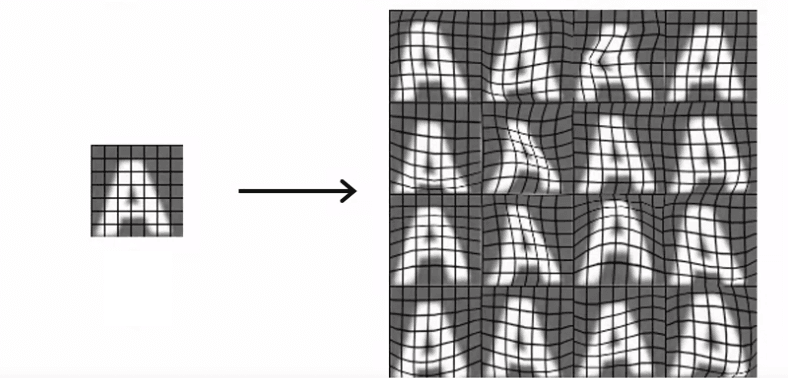
A more advanced example of data augmentation would be to introduce random warping to a letter A using a grid placed on top of the letter. This process of distorting the image can turn one training example into many, allowing the algorithm to learn more robustly what the letter A looks like.
Data augmentation can also be applied to speech recognition. For example, you might use noisy background audio to create new examples from an original audio clip of someone asking for the weather. By doing this, you're telling the algorithm that the speech should still be recognizable even with background noise.
Data augmentation is a valuable technique for increasing the size of your training set and helping your machine learning algorithms perform better. Whether you're working on image or audio recognition, data augmentation can help you get more out of your existing training data.
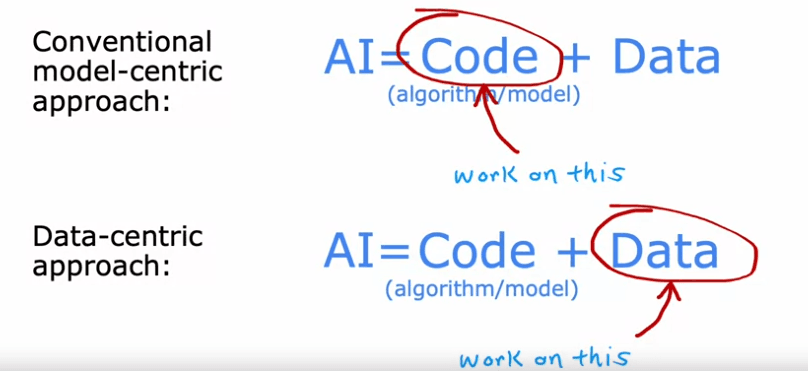
Transfer learning
Transfer learning is a valuable technique in machine learning that allows you to leverage data from one task to improve performance on another task. It is particularly useful when you don't have a large amount of data for your specific task. In this article, we will explore how transfer learning works and how you can implement it in your own applications.
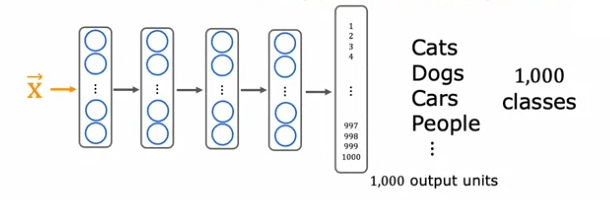
Let's start by looking at a concrete example: recognizing handwritten digits from zero to nine. If you don't have a lot of labeled data for this task, you can still use transfer learning to improve your model's performance. For instance, you can start by training a neural network on a large dataset of a million images of cats, dogs, cars, people, etc., with 1000 different classes. By doing this, you learn the parameters for the first layer of the neural network (W^1, b^1), the second layer (W^2, b^2), and so on, until the output layer (W^5, b^5).
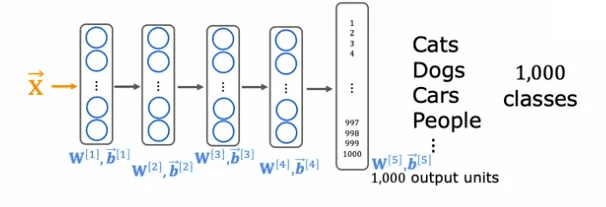
To apply transfer learning, you make a copy of this neural network and modify it to only recognize the digits zero to nine by removing the last layer and replacing it with a smaller output layer of 10 units instead of 1000. The new parameters (W^5, b^5) must be trained from scratch, while the parameters from the previous layers can be used as a starting point.
There are two options for training the new network:
- Train only the output layer's parameters (W^5, b^5). You use the parameters from the first four layers as is and use optimization algorithms like Stochastic Gradient Descent or Adam to only update W^5, b^5.
- Train all the parameters in the network (W^1, b^1 to W^5, b^5). You initialize the first four layers' parameters with the values from the original network and then fine-tune them using gradient descent.
The first step of training the large dataset is called supervised pre-training, while the second step of fine-tuning the parameters to suit your specific task is called fine tuning. If you have a small dataset, using a pre-trained model can significantly improve performance. Moreover, you don't have to train the model yourself, as many researchers have already trained neural networks on large datasets and posted them online for free use. All you have to do is download a pre-trained model, replace the output layer with your own, and fine-tune it to suit your task.
In conclusion, transfer learning is a powerful technique that can help you achieve good performance even with limited data. By leveraging the work of others in the machine learning community, you can quickly train a high-quality model for your specific task.
Full cycle of a machine learning cycle
- Scoping the project: Decide the project focus and goals. In this example, speech recognition for voice search on mobile phones is the project.
- Data Collection: Determine the data required to train the machine learning system, and gather audio and transcripts of the labels.
- Training the Model: Train the speech recognition system, perform error analysis, and iteratively improve the model through collecting more data or augmenting existing data.
- Deployment: Deploy the high-performing machine learning model in a production environment, making it available to users.
- Maintenance: Monitor the performance of the deployed system and maintain it in case the performance worsens.
- Improving the Model: If the performance is not as desired, go back to training the model or collecting more data from the production deployment.
Then we deploy it on production :
- Inference Server: Implement the trained machine learning model in an inference server to make predictions.
- API Call: Mobile app makes an API call to the inference server, passing the audio clip and receiving the text transcripts of what was said.
- Software Engineering: Depending on the scale of the application, software engineering may be needed to ensure the inference server can make reliable and efficient predictions and handle the number of users.
- Logging Data: Log the input and prediction data, assuming user privacy and consent allow it. The data is useful for system monitoring and improvement
Fairness, bias and ethics
Machine learning is a rapidly growing field that has the potential to impact billions of people. As with any technology, it is important to consider the ethical implications of its use and to ensure that the systems we build are fair, unbiased, and free from harm.
Unfortunately, the history of machine learning is filled with examples of systems that have exhibited unacceptable levels of bias and discrimination. For example, there have been instances of hiring algorithms that discriminate against women and face recognition systems that match dark-skinned individuals to criminal mug shots more often than lighter-skinned individuals. It is crucial that we, as a community, take steps to prevent the deployment of such biased systems.
In addition to the issues of bias and fairness, there have also been negative use cases of machine learning algorithms. For example, there have been deepfake videos created without consent or disclosure, and social media algorithms that have spread toxic or incendiary speech. Some individuals have even used machine learning to commit fraud or to build harmful products.
Given the potential impact of machine learning on society, it is important to approach the development of these systems with a strong sense of ethics. This includes assembling a diverse team that can bring different perspectives to the table, researching industry standards and guidelines, and conducting a thorough audit of the system prior to deployment.
While ethics is a complex and multifaceted subject, it is still possible to take steps to ensure that our work is more fair, less biased, and more ethical. It is up to each of us to take this responsibility seriously and to make a positive impact with the systems we build.





