 Français
FrançaisIntroduction
Dans un système distribué tel qu'un paysage de microservices coopérants, il est important de pouvoir suivre et visualiser le parcours des demandes et des messages lors du traitement d'un appel externe. Pour cela, Spring Cloud Sleuth propose une fonctionnalité qui permet de marquer les demandes et les messages d'un même flux de traitement avec un ID de corrélation commun. Cette fonctionnalité peut également décorer les enregistrements de logs avec des ID de corrélation pour faciliter le suivi des enregistrements provenant de différents microservices.
Zipkin est un système distribué de traçage auquel Spring Cloud Sleuth peut envoyer des données de traçage pour le stockage et la visualisation. Les informations de traçage distribuées dans Spring Cloud Sleuth et Zipkin sont basées sur Google Dapper, qui définit un arbre de trace et des étendues identifiées par un TraceId et un SpanId.
En 2010, Google a publié l'article sur Dapper, qu'il utilise en interne depuis 2005. En 2016, le projet OpenTracing a rejoint la CNCF, fournissant des API indépendantes du fournisseur et des bibliothèques spécifiques au langage pour instrumenter le traçage distribué. En 2019, le projet OpenTracing a fusionné avec le projet OpenCensus pour former un nouveau projet CNCF, OpenTelemetry, qui fournit un ensemble de bibliothèques pour collecter des métriques et des traces distribuées.
Spring Cloud Inspector permet d'envoyer des requêtes à Zipkin de manière synchrone via HTTP ou de manière asynchrone en utilisant RabbitMQ ou Kafka. Pour éviter de créer des dépendances d'exécution sur le serveur Zipkin depuis les microservices, il est recommandé d'envoyer les informations à Zipkin de manière asynchrone en utilisant RabbitMQ ou Kafka. Le schéma suivant illustre cette approche :
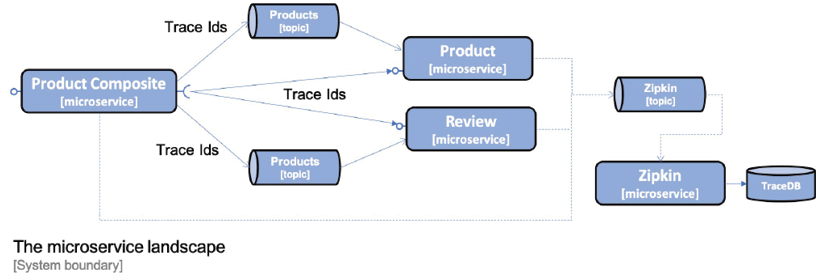
Ce qui suit est une capture d'écran du ZipkinUI, qui visualise l'arborescence de trace qui a été créée à la suite du traitement de la création d'un produit agrégé :
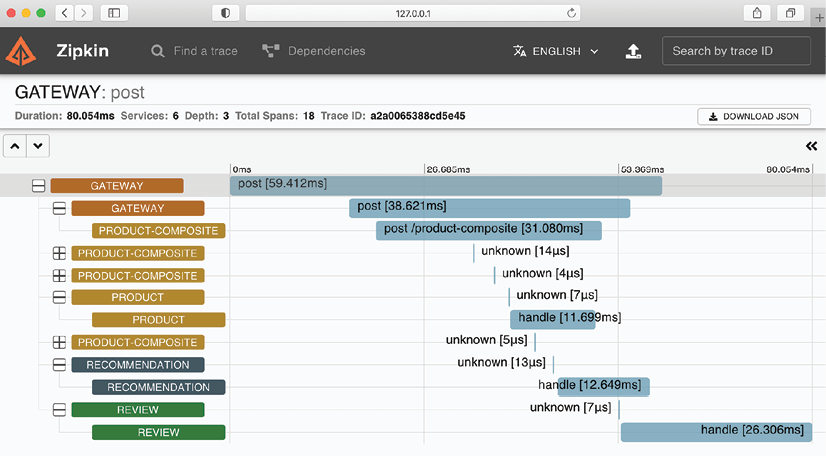
La capture d'écran montre qu'une requête POST est envoyée au service product-composite via la passerelle. Le service répond en publiant des événements de création sur les sujets des produits, des recommandations et des critiques, qui sont consommés par les trois microservices principaux en parallèle et de manière asynchrone. Les événements sont stockés dans la base de données de chaque microservice. Les inconnus représentent l'interaction avec le courtier de messages, soit en publiant soit en consommant un événement.
Traçage distribué avec Spring Cloud Sleuth et Zipkin
Avec l'introduction de Spring Cloud Sleuth et Zipkin, nous avons vu un exemple de traçage distribué pour le traitement d'une requête HTTP synchrone externe, qui inclut la transmission asynchrone d'événements entre les microservices impliqués.
Application
Pour activer le traçage distribué à l'aide de Spring Cloud Sleuth et Zipkin, voici les étapes à suivre :
- Ajouter des dépendances pour intégrer Spring Cloud Sleuth et la possibilité d'envoyer des informations de trace à Zipkin dans les fichiers de construction.
- Ajouter des dépendances pour RabbitMQ et Kafka dans les projets qui ne les ont pas utilisés auparavant, c'est-à-dire les projets Spring Cloud authorization-server, eureka-server et gateway.
- Configurer les microservices pour envoyer des informations de trace à Zipkin à l'aide de RabbitMQ ou de Kafka.
- Ajouter un serveur Zipkin aux fichiers Docker Compose.
- Ajouter le profil Springkafka dans docker-compose-kafka.yml pour les projets Spring Cloud authorization-server, eureka-server et gateway.
- Utiliser une image Docker publiée par le projet Zipkin pour exécuter le serveur Zipkin en tant que conteneur Docker.
Pour utiliser Spring Cloud Sleuth et envoyer des informations de suivi à Zipkin, il est nécessaire d'ajouter des dépendances dans le fichier de construction Gradle, build.gradle.
implementation 'org.springframework.cloud:spring-cloud-starter-sleuth'
implementation 'org.springframework.cloud:spring-cloud-sleuth-zipkin'
Pour les projets Gradle qui n'ont jamais utilisé RabbitMQ et Kafka auparavant, les dépendances suivantes doivent être ajoutées :
implementation 'org.springframework.cloud:spring-cloud-starter-stream-rabbit'
implementation 'org.springframework.cloud:spring-cloud-starter-stream-kafka'
La configuration pour utiliser Spring Cloud Sleuth et Zipkin doit être ajoutée au fichier de configuration commun, config-repo/application.yml. Dans le profil par défaut, il est spécifié que les informations de trace seront envoyées à Zipkin en utilisant RabbitMQ :
implementation 'org.springframework.cloud:spring-cloud-starter-stream-rabbit'
implementation 'org.springframework.cloud:spring-cloud-starter-stream-kafka'
Il est nécessaire d'ajouter la configuration pour utiliser Spring Cloud Sleuth et Zipkin au fichier de configuration commun, config-repo/application.yml. Dans le profil par défaut, il est précisé que les données de traçage seront transmises à Zipkin en utilisant RabbitMQ.
spring.zipkin.sender.type: rabbit
Dans le profil par défaut, Spring Cloud Sleuth n'envoie que 10 % des traces à Zipkin par défaut. Pour garantir que toutes les traces soient envoyées à Zipkin, la propriété suivante doit être ajoutée :
spring.sleuth.sampler.probability: 1.0
Lors de l'envoi de traces à Zipkin via Kafka, le profil Spring Kafka doit être utilisé. Dans ce profil, nous remplaçons le paramètre du profil par défaut pour que les informations de traçage soient envoyées à Zipkin en utilisant Kafka :
---
spring.config.activate.on-profile: kafka
spring.zipkin.sender.type: kafka
Enfin, le service de passerelle nécessite un paramètre dans le fichier de configuration config-repo/gateway.yml pour permettre à Sleuth de suivre les ID de traçage de manière appropriée :
spring.sleuth.reactor.instrumentation-type: decorate-on-last
Ajout de Zipkin aux fichiers Docker Compose
Comme indiqué précédemment, le serveur Zipkin est ajouté aux fichiers Docker-Compose à l'aide de l'image Docker existante openzipkin/zipkin, publiée par le projet Zipkin. Dans les fichiers docker-compose.yml et docker-compose-partitions.yml où RabbitMQ est utilisé, la définition du serveur Zipkin est la suivante :
zipkin:
image: openzipkin/zipkin:2.23.2
mem_limit: 1024m
environment:
- RABBIT_ADDRESSES=rabbitmq
- STORAGE_TYPE=mem
ports:
- 9411:9411
depends_on:
rabbitmq:
condition: service_healthy
La configuration du serveur Zipkin dans docker-compose-kafka.yml est la suivante :
- L'image Docker utilisée est openzipkin/zipkin version 2.23.2.
- La variable d'environnement RABBIT_ADDRESSES est définie à "rabbitmq" pour indiquer que Zipkin recevra les informations de suivi via RabbitMQ et se connectera à RabbitMQ en utilisant le nom d'hôte "rabbitmq".
- La variable d'environnement STORAGE_TYPE est définie à "mem" pour spécifier que toutes les informations de trace seront conservées en mémoire.
- La limite de mémoire est augmentée à 1 024 Mo pour Zipkin, par rapport aux 512 Mo pour les autres conteneurs, car Zipkin consommera plus de mémoire que les autres conteneurs en raison de la conservation de toutes les informations de trace en mémoire.
- Zipkin expose le port HTTP 9411 pour permettre aux navigateurs Web d'accéder à son interface utilisateur Web.
- Docker attendra que le service RabbitMQ signale qu'il est sain avant de démarrer le serveur Zipkin.
Il est acceptable de stocker les informations de trace en mémoire dans Zipkin pour les activités de développement et de test, mais dans un environnement de production, il est recommandé de configurer Zipkin pour stocker les informations de trace dans une base de données telle qu'Apache Cassandra, Elasticsearch ou MySQL.
zipkin:
image: openzipkin/zipkin:2.23.2
mem_limit: 1024m
environment:
- STORAGE_TYPE=mem
- KAFKA_BOOTSTRAP_SERVERS=kafka:9092
ports:
- 9411:9411
depends_on:
- kafka
Le code source suivant est une configuration pour utiliser Zipkin avec Kafka dans le contexte de Spring Cloud :
- La configuration pour utiliser Zipkin avec Kafka est similaire à celle pour utiliser Zipkin avec RabbitMQ.
- La principale différence réside dans l'utilisation de la variable d'environnement KAFKA_BOOTSTRAP_SERVERS=kafka:9092 pour spécifier que Zipkin utilisera Kafka pour recevoir les informations de trace, et se connectera à Kafka en utilisant le nom d'hôte "kafka" et le port 9092.
- Docker attendra que le service Kafka soit lancé avant de démarrer le serveur Zipkin.
- Dans docker-compose-kafka.yml, le profil Spring kafka est ajouté aux services Spring Cloud eureka, gateway et auth-server.
environment:
- SPRING_PROFILES_ACTIVE=docker,kafka
Pour tester le traçage distribué, nous allons suivre les étapes suivantes :
- Créer, démarrer et vérifier le paysage système avec RabbitMQ en tant que gestionnaire de files d'attente.
- Envoyer une demande d'API réussie et vérifier les informations de trace dans Zipkin qui y sont liées.
- Envoyer une demande d'API infructueuse et vérifier les informations d'erreur dans Zipkin.
- Envoyer une demande d'API réussie qui déclenche un traitement asynchrone et vérifier comment ses informations de trace sont représentées dans Zipkin.
- Découvrir comment surveiller les informations de trace transmises à Zipkin dans RabbitMQ.
- Changer le gestionnaire de files d'attente pour Kafka et répéter les étapes précédentes.
Démarrage du système avec RabbitMQ en tant que gestionnaire de files d'attente
./gradlew build && docker-compose build
Pour pouvoir appeler l'API, vous devez d'abord obtenir un jeton d'accès en exécutant les commandes suivantes :
unset ACCESS_TOKEN
ACCESS_TOKEN=$(curl -k https://writer:secret@localhost:8443/oauth2/token -d grant_type=client_credentials -s | jq -r .access_token)
echo $ACCESS_TOKEN
Envoi d'une demande d'API réussie
Maintenant que nous avons obtenu un jeton d'accès, nous sommes prêts à envoyer une requête normale à l'API. Veuillez exécuter la commande sivante :
curl -H "Authorization: Bearer $ACCESS_TOKEN" -k https://localhost:8443/product-composite/1 -w "%{http_code}\n" -o /dev/null -s
Après avoir envoyé une demande d'API réussie, nous pouvons lancer l'interface utilisateur Zipkin pour voir les informations de suivi qui ont été envoyées à Zipkin en suivant ces étapes :
- Ouvrez l'URL suivante dans votre navigateur Web : http://localhost:9411/zipkin/.
- Pour trouver les informations de trace pour notre requête, recherchez les traces qui sont passées par le service gateway. Pour cela, cliquez sur le grand signe plus (+) et sélectionnez "serviceName", puis "gateway".
- Cliquez sur le bouton "EXÉCUTER LA REQUÊTE".
- Cliquez sur l'en-tête "Heure de début" pour voir les résultats classés par ordre chronologique inverse (une flèche vers le bas doit être visible à gauche de l'en-tête "Heure de début").
Vous devriez voir les informations de trace pour votre demande d'API réussie. Le code d'état HTTP de la demande devrait être 200.
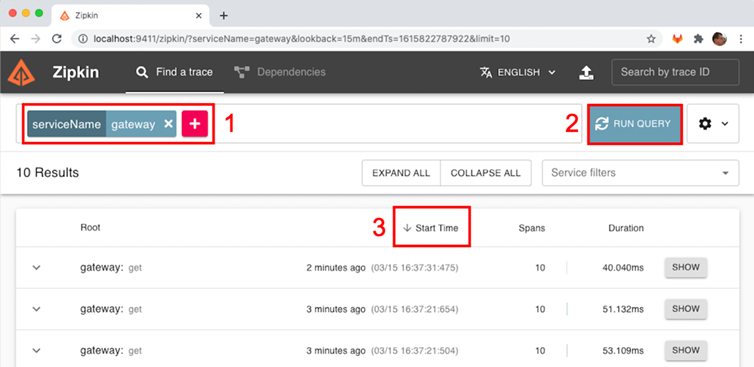
- Les informations de traçage de notre requête API précédente sont les premières de la liste. Veuillez cliquer sur le bouton AFFICHER pour voir les détails de la trace :
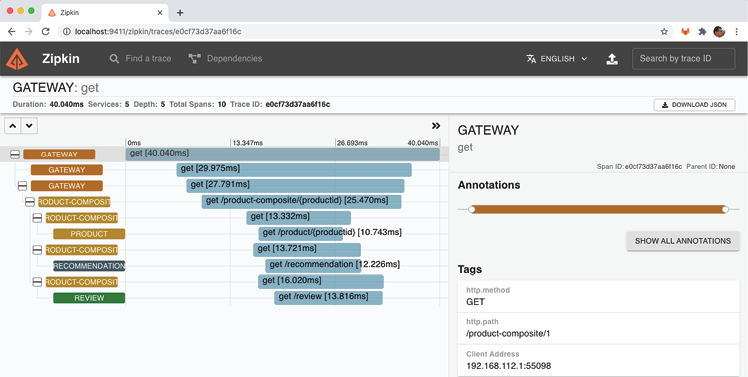
Dans la vue détaillée des informations de trace, nous pouvons observer les éléments suivants :
- La demande a été reçue par le service gateway.
- Le service gateway a délégué le traitement de la demande au service product-composite.
- Le service product-composite a envoyé trois requêtes parallèles aux services principaux : product, recommendation et review.
- Une fois que le service product-composite a reçu la réponse des trois services principaux, il a créé une réponse composite et l'a renvoyée à l'appelant via le service gateway.
- Dans la vue détaillée à droite, nous pouvons voir le chemin HTTP de la demande réelle que nous avons envoyée : "/product-composite/1".
Envoi d'une requête API infructueuse
Pour voir comment les informations de trace sont représentées pour une demande d'API infructueuse, nous allons effectuer les étapes suivantes :
- Envoyer une requête API pour un ID de produit qui n'existe pas, par exemple l'ID 12345, et vérifier qu'elle renvoie le code d'état HTTP pour "Not Found", soit 404 :
curl -H "Authorization: Bearer $ACCESS_TOKEN" -k https://localhost:8443/product-composite/12345 -w "%{http_code}\n" -o /dev/null -s
- Dans l'interface utilisateur Zipkin, revenez à la page de recherche (utilisez le bouton de retour dans le navigateur Web) et cliquez à nouveau sur le bouton "EXÉCUTER LA REQUÊTE". Pour voir les résultats classés par ordre chronologique inverse, cliquez sur l'en-tête "Heure de début". Vous devriez voir la demande ayant échoué en haut de la liste renvoyée. Notez que sa barre de durée est rouge, indiquant qu'une erreur s'est produite. Cliquez sur son bouton "AFFICHER" pour voir les détails.
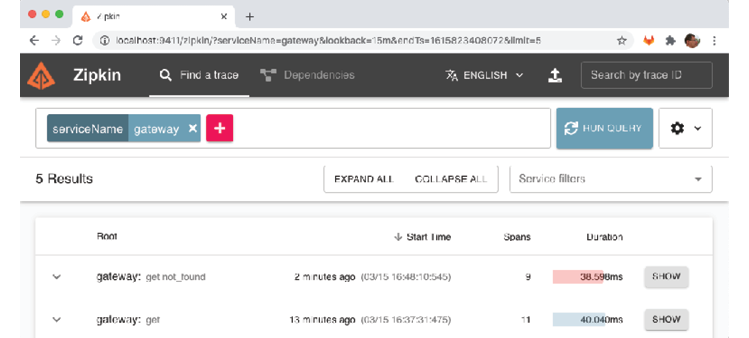
- Vous verrez ici le chemin de la requête qui a causé l'erreur, "/product-composite/12345", ainsi que le code d'erreur : 404 (Not Found). La couleur rouge de la barre indique que c'est la demande au service product qui a provoqué l'erreur. Ces informations sont très utiles pour déterminer la cause première d'une panne !
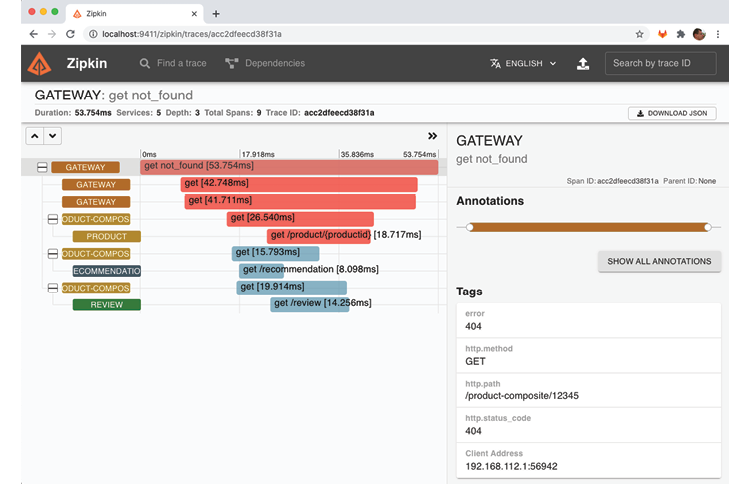
Lorsqu'une demande d'API infructueuse est effectuée, nous pouvons voir les informations de trace correspondantes dans l'interface utilisateur Zipkin. Le chemin de la requête qui a causé l'erreur est affiché, dans ce cas "/product-composite/12345", ainsi que le code d'erreur : 404 (Not Found). La couleur rouge de la barre indique que c'est la demande au service product qui a provoqué l'erreur. Ces informations sont très utiles lors de l'analyse de la cause première d'une panne !
Envoi d'une requête API qui déclenche un traitement asynchrone
Le troisième type de demande que nous pouvons observer dans l'interface utilisateur Zipkin est une demande où certaines parties de son traitement sont effectuées de manière asynchrone. Nous allons effectuer une demande de suppression où le processus de suppression dans les services principaux est effectué de manière asynchrone. Voici les étapes à suivre :
- Exécutez la commande suivante pour supprimer le produit ayant un ID de 12345, et vérifiez qu'elle renvoie le code d'état HTTP 200 en cas de succès :
curl -X DELETE -H "Authorization: Bearer $ACCESS_TOKEN" -k https://localhost:8443/product-composite/12345 -w "%{http_code}\n" -o /dev/null -s
Cela déclenchera un traitement asynchrone dans les services principaux. 2. Ouvrez l'interface utilisateur Zipkin et exécutez une recherche pour le service product-composite en suivant les étapes décrites précédemment. Vous devriez voir la demande de suppression dans la liste. 3. Cliquez sur le bouton "AFFICHER" pour voir les détails de la demande. Vous devriez voir que la demande a déclenché des événements de suppression dans les services principaux, qui ont été envoyés à l'agent de messages. 4. Cliquez sur l'événement "product.delete", puis sur "Recherche de traces correspondantes". Vous devriez voir les informations de trace pour l'événement de suppression du service product. Les barres bleues indiquent que le traitement a été effectué de manière asynchrone. 5. Répétez les étapes 3 et 4 pour les événements de suppression envoyés aux services de recommendation et de review. Vous devriez voir les informations de trace pour ces événements et les barres bleues indiquant que le traitement a été effectué de manière asynchrone.
Pour voir les résultats triés par ordre chronologique décroissant dans l'interface utilisateur de Zipkin, retournez à la page de recherche en utilisant le bouton de retour dans le navigateur Web. Ensuite, cliquez sur le bouton "RUN QUERY". Pour trier les résultats par ordre de la date et de l'heure de début, cliquez sur l'en-tête "Heure de début". Vous pouvez vous attendre à obtenir un résultat similaire à la capture d'écran ci-dessous :
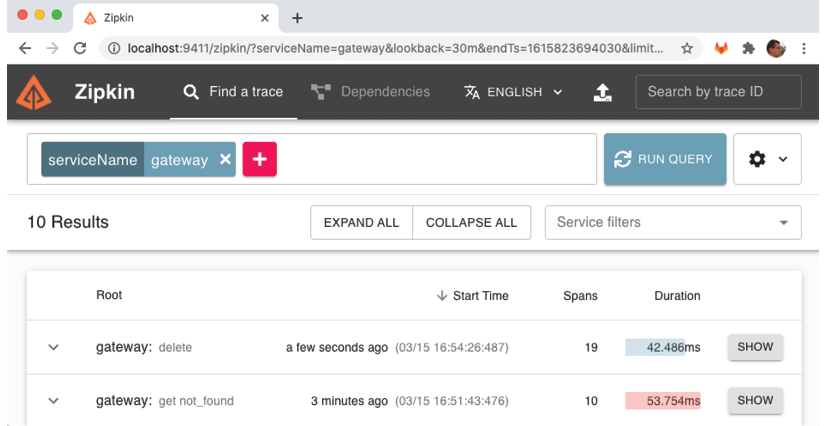
Après avoir trié les résultats par ordre chronologique décroissant, vous devriez voir la demande de suppression en haut de la liste renvoyée. Il est à noter que le nom du service racine, "gateway", est suffixé par la méthode HTTP utilisée, "delete". Pour voir les détails de cette demande de suppression, cliquez sur le bouton "AFFICHER" correspondant.
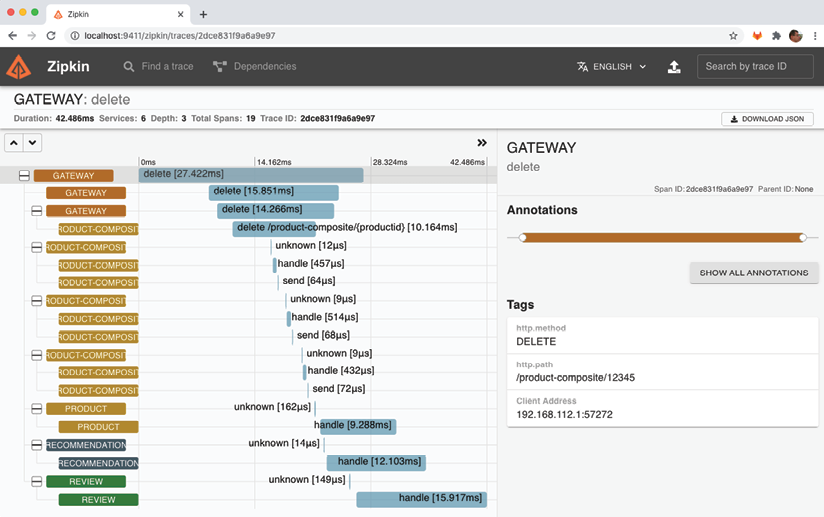
Les informations de trace pour le traitement de la demande de suppression sont affichées ici :
- La demande de suppression a été reçue par le service "gateway".
- Le service "gateway" a délégué le traitement de la demande au service "product-composite".
- Le service "product-composite" a publié trois événements sur le courtier de messages (RabbitMQ, dans ce cas).
- Le service "product-composite" a renvoyé un code d'état HTTP de réussite 200, via le service "gateway", à l'appelant.
- Les services principaux (product, recommendation et review) ont reçu les événements de suppression et ont commencé à les traiter de manière asynchrone, c'est-à-dire indépendamment les uns des autres.
Pour confirmer l'implication du courtier de messages, cliquez sur le premier span du service "product" :
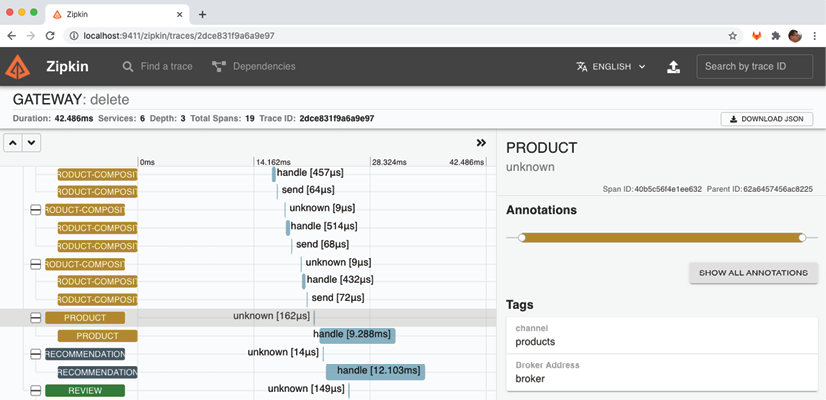
Dans la plage sélectionnée, le nom donné, "unknown", est plutôt inutile. Cependant, dans la section "Balises" de la plage sélectionnée, située à droite, nous pouvons trouver des informations plus intéressantes. Nous y découvrons que le service "product" a été déclenché par un message délivré sur son canal d'entrée, nommé "products". De plus, le nom du courtier de messages utilisé, "courtier", est visible dans le champ "Adresse du courtier".
En somme, dans cette section, nous avons appris à utiliser le traçage distribué pour comprendre comment nos microservices coopèrent. Nous avons appris à collecter des informations de trace en utilisant Spring Cloud Sleuth et à stocker et visualiser ces informations avec Zipkin. Pour favoriser le découplage des composants d'exécution, nous avons appris à configurer des microservices pour envoyer des informations de trace de manière asynchrone au serveur Zipkin, en utilisant RabbitMQ et Kafka comme courtiers de messages. Nous avons vu comment l'ajout de Spring Cloud Sleuth aux microservices est facile grâce à l'ajout de quelques dépendances aux fichiers de construction et à la configuration de quelques paramètres. Enfin, nous avons vu comment l'interface utilisateur de Zipkin permet d'identifier rapidement quelle partie d'un flux de travail complexe a provoqué un temps de réponse inattendu ou une erreur, et comment elle permet de visualiser des flux de travail synchrones et asynchrones.





