 Français
FrançaisDescription
Les cartes auto-adaptatives, également connues sous le nom de SOM (Self-Organizing Maps), sont une technique de clustering non supervisée utilisée en apprentissage automatique. Les SOM permettent de visualiser et d'analyser des données multidimensionnelles en projetant les points de données sur une grille de neurones bidimensionnelle, appelée carte SOM. Chaque neurone de la carte SOM représente une région de l'espace de données multidimensionnelles.
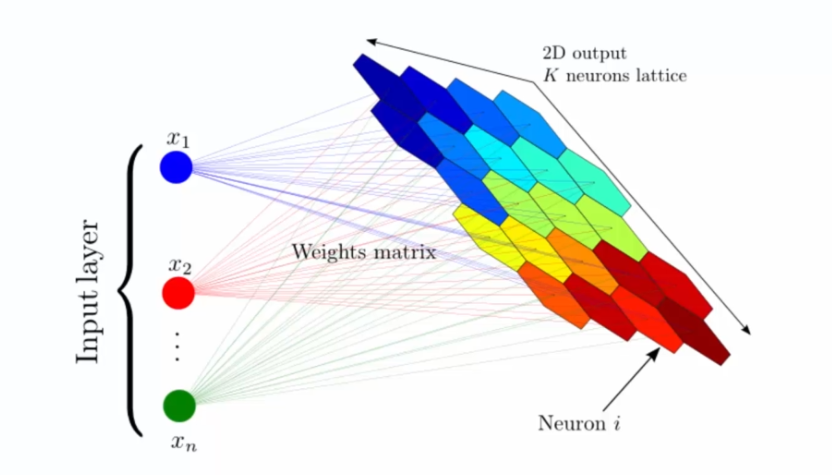
Les SOM sont souvent utilisées pour identifier des schémas et des relations entre les données, en particulier pour l'analyse exploratoire de données. Par exemple, en utilisant les données sur la pauvreté dans différents pays, une carte SOM peut être utilisée pour visualiser les niveaux de pauvreté et identifier les pays ayant des niveaux similaires de pauvreté.
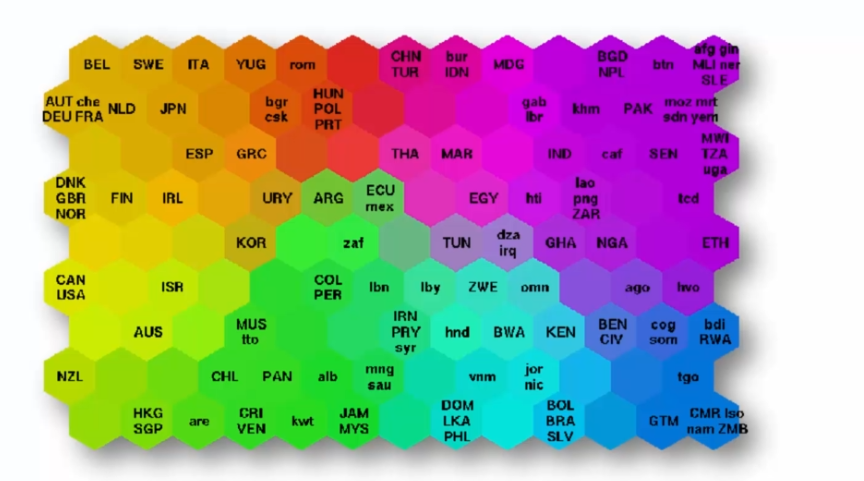
Voici un exemple simplifié : supposons que nous ayons des données sur la pauvreté dans différents pays, en utilisant la carte SOM, nous pourrions projeter ces données sur une grille de neurones de 5x5, où chaque neurone représente un cluster de pays ayant des niveaux de pauvreté similaires. La position de chaque pays sur la carte SOM serait déterminée par ses caractéristiques de pauvreté, telles que le taux de pauvreté, le revenu moyen, etc.
En regardant la carte SOM, nous pourrions identifier des régions de pays ayant des niveaux de pauvreté similaires, par exemple, les pays du nord de l'Afrique pourraient être groupés dans un cluster, tandis que les pays européens seraient groupés dans un autre. Cela permettrait de visualiser rapidement les niveaux de pauvreté dans différentes régions du monde et de détecter des schémas intéressants dans les données.
Voici un exemple de visualisation :
K-means
Le K-means est également une technique de clustering non supervisée utilisée en apprentissage automatique pour identifier des groupes de points de données similaires dans un ensemble de données. Contrairement aux SOM, le K-means ne projette pas les données sur une carte bidimensionnelle, mais plutôt il assigne chaque point de données à l'un des K clusters prédéfinis.
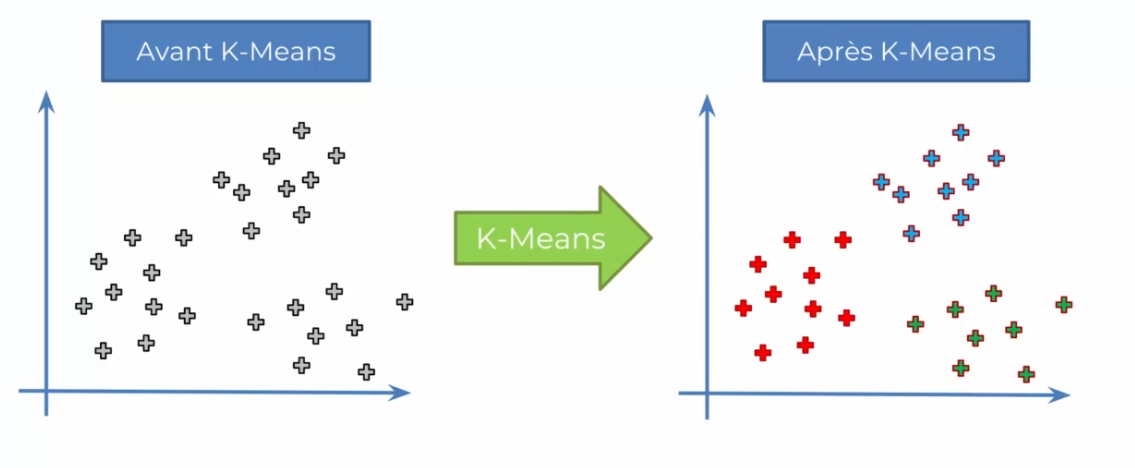
Comment ça marche ?
Le fonctionnement de l'algorithme K-means est relativement simple. Tout d'abord, l'utilisateur doit spécifier le nombre de clusters K qu'il souhaite utiliser. Ensuite, l'algorithme sélectionne K points aléatoires de l'ensemble de données initiale pour servir de centres de cluster initiaux.
Ensuite, chaque point de données est assigné au cluster le plus proche en termes de distance euclidienne avec les centres de cluster. Une fois que tous les points ont été assignés à un cluster initial, les centres de cluster sont recalculés comme la moyenne de tous les points dans chaque cluster. Ce processus est répété jusqu'à ce que les centres de cluster convergent vers une position stable.
Pour vous donner un exemple concret, supposons que vous disposez d'un ensemble de données contenant des informations sur le revenu par habitant et le taux de pauvreté dans différents pays. Vous pourriez utiliser l'algorithme K-means pour regrouper ces pays en différents clusters en fonction de leur niveau de pauvreté.
Par exemple :
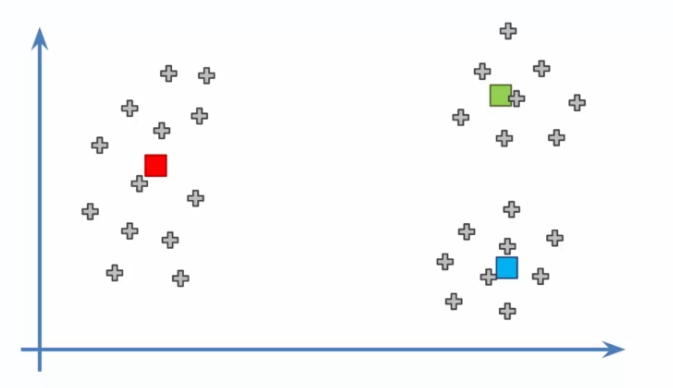
- Choix de K clusters : Tout d'abord, nous devons déterminer le nombre de clusters que nous voulons créer. Cela peut être décidé en fonction de notre objectif ou de notre connaissance du domaine d'application. Par exemple, si nous essayons de segmenter des clients d'une entreprise en groupes distincts, nous pouvons choisir K = 3 pour identifier les clients à haut, moyen et bas revenu.

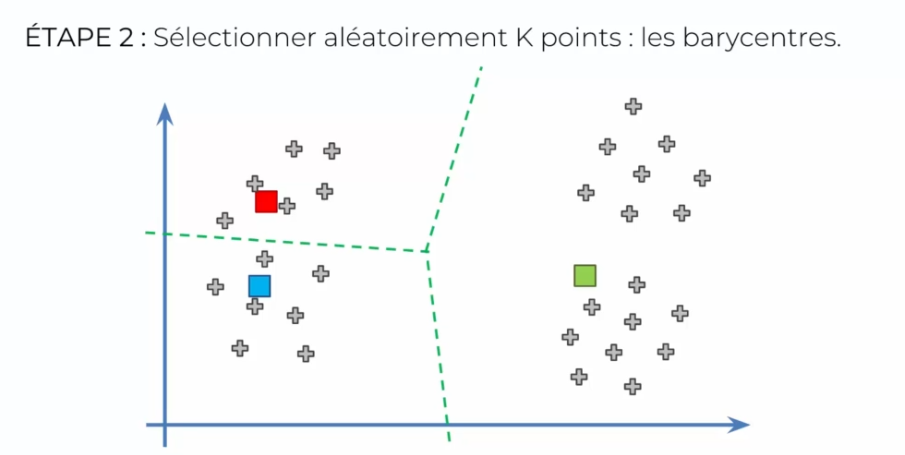
- Initialisation des barycentres : Nous devons maintenant choisir K points aléatoires dans l'ensemble de données pour servir de barycentres initiaux. Ces barycentres représentent les centres de chaque cluster et seront ajustés au fur et à mesure de l'itération de l'algorithme.
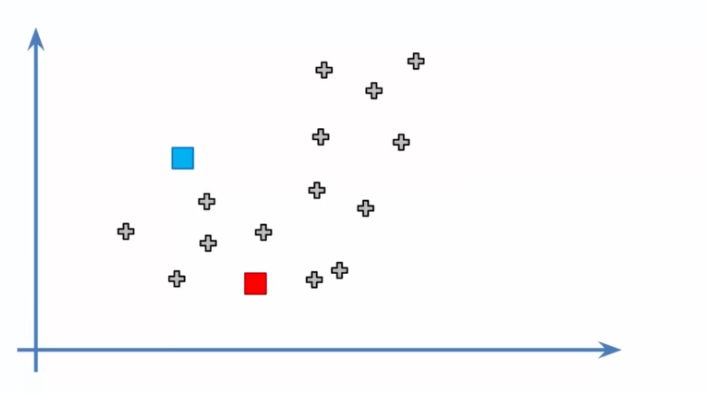
- Attribution des données aux barycentres : Nous attribuons chaque donnée à son barycentre le plus proche. Cela crée K clusters initiaux et nous permet de commencer à voir les différents groupes de données.
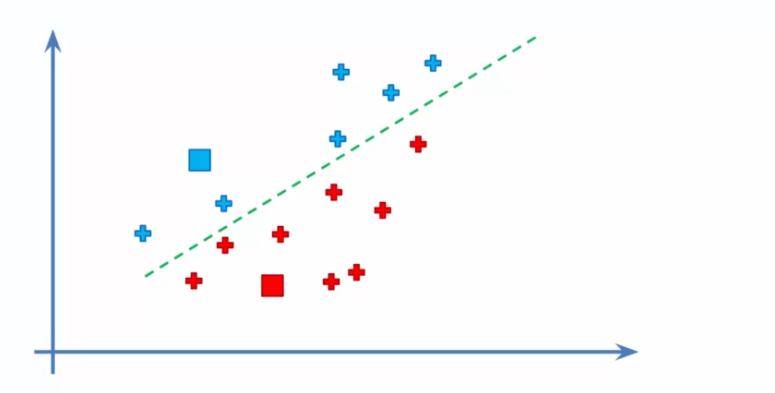
- Recalcul des barycentres : Nous recalculons les barycentres en prenant la moyenne de toutes les données associées à chaque cluster. Cela nous donne une position plus précise pour chaque barycentre et permet de réajuster les clusters.
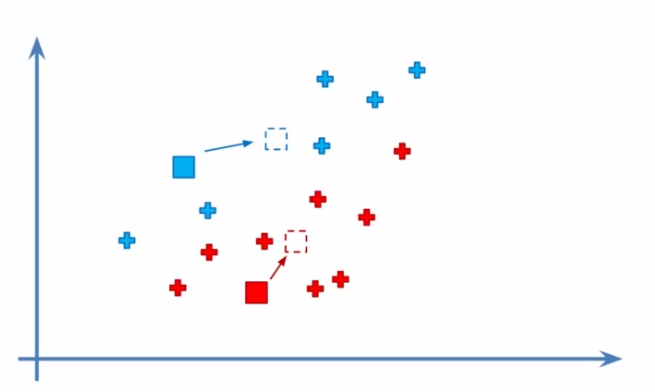
- Réattribution des données : Nous réattribuons chaque donnée à son barycentre le plus proche en fonction des nouveaux barycentres calculés. Si des réattributions ont lieu, nous retournons à l'étape 4 pour recalculer les barycentres et réajuster les clusters.
Le problème de l'initialisation
L'un des principaux défis est la sélection initiale des barycentres, qui peuvent affecter considérablement le résultat final. Lors de la sélection initiale des barycentres, il est possible de choisir des points qui peuvent ne pas être représentatifs de l'ensemble de données dans son ensemble. Cela peut entraîner une convergence vers des clusters qui ne sont pas optimaux. Dans certains cas, cela peut même entraîner une divergence de l'algorithme.
Prenons l'exemple où k est = à 3 cluster et installons nos barycentres pour créer les 3 groupes :
Mais est-ce que l'algorithme peut converger ? Que se passerait-il si on choisissait mal l'initialisation ?
Relançons notre algorithme en regardant les 5 étapes précédentes :
On passe ensuite à l'étape 4 pour bouger les barycentres. Ensuite, on arrive à l'étape 5 qui réassigne les points aux clusters. Mais on s'aperçoit que rien ne va changer, donc c'est terminé ! Toutefois, les clusters sont maintenant différents :
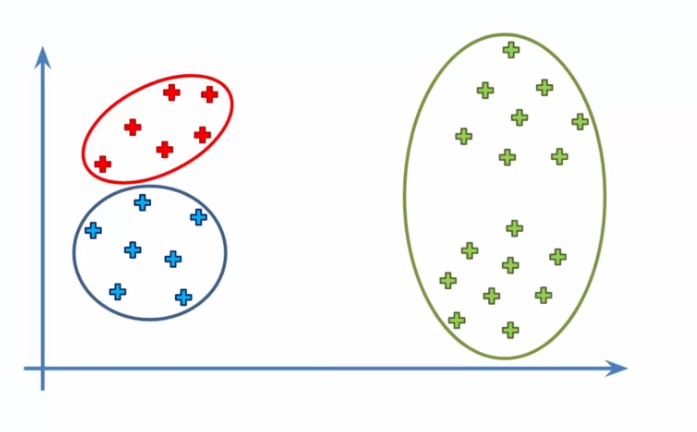
Pour éviter ce problème, une méthode améliorée appelée K-means++ a été proposée. Dans l'algorithme K-means++, les barycentres initiaux sont sélectionnés de manière plus intelligente. Au lieu de choisir des points aléatoires, K-means++ utilise une méthode de sélection pondérée pour sélectionner des points qui sont plus éloignés les uns des autres. Cette méthode permet de s'assurer que les barycentres initiaux sont bien répartis dans l'ensemble de données.
En outre, il est important de noter que l'algorithme K-means ne converge pas toujours vers une solution optimale. En effet, la convergence de l'algorithme dépend des points initiaux et de la nature des données. Dans certains cas, l'algorithme peut converger vers un minimum local plutôt que vers un minimum global, ce qui peut donner des résultats différents à chaque fois que l'algorithme est exécuté.
Choisir le bon nombre de cluster
Choisir le bon nombre de clusters pour l'algorithme K-means est crucial pour obtenir des résultats pertinents. Il est important de trouver le nombre optimal de clusters pour que l'algorithme puisse identifier des groupes significatifs dans les données. Voici quelques méthodes courantes pour déterminer le nombre de clusters :
-
La méthode du coude : Cette méthode consiste à tracer la somme des carrés des distances des points à leur barycentre en fonction du nombre de clusters. On cherche le point où la courbe commence à avoir une diminution plus lente, comme un coude. Cela peut nous aider à identifier le nombre optimal de clusters à utiliser.
-
La méthode de la silhouette : Cette méthode consiste à évaluer la qualité de la partition des clusters. Elle calcule la distance moyenne entre chaque point et les autres points de son cluster, puis la distance moyenne entre chaque point et les points des clusters voisins les plus proches. Ensuite, elle calcule une mesure de silhouette pour chaque point. La silhouette globale est calculée en prenant la moyenne des silhouettes pour tous les points de données. Un score de silhouette proche de 1 indique que les points sont bien regroupés, tandis qu'un score proche de 0 indique que les points sont mal regroupés.
-
La méthode de la validation croisée : Cette méthode consiste à diviser les données en deux ensembles distincts, l'un pour l'apprentissage et l'autre pour la validation. On utilise l'ensemble d'apprentissage pour exécuter K-means avec différents nombres de clusters, puis on évalue les résultats sur l'ensemble de validation en utilisant une mesure de qualité de cluster, comme la distance intra-cluster ou la variance expliquée.
Il est important de noter que la détermination du nombre optimal de clusters est souvent subjective et dépend de l'application et de l'expérience de l'utilisateur. En général, il est préférable d'utiliser plusieurs méthodes pour évaluer différents aspects de la qualité du cluster et d'examiner les résultats de manière qualitative et quantitative.
L'apprentissage des SOMs
L'apprentissage des SOMs se base sur un réseau de neurones organisé en une grille 2D de nœuds, chaque nœud étant associé à un vecteur de poids qui représente sa position dans l'espace de données. Lors de la phase d'apprentissage, les poids de chaque nœud sont ajustés pour qu'il puisse représenter une région de l'espace de données.
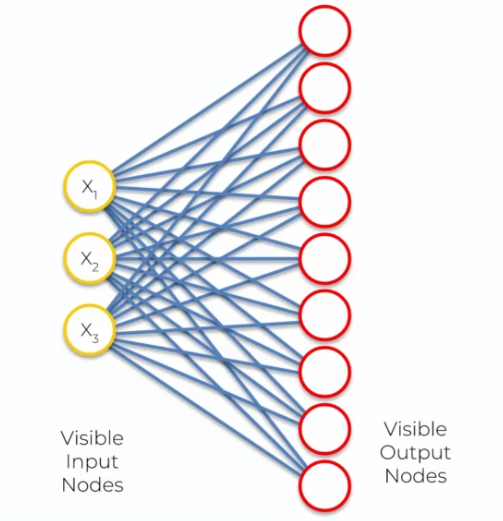
Le processus d'apprentissage commence par l'initialisation des poids des nœuds avec des valeurs aléatoires. Ensuite, pour chaque entrée, le nœud le plus proche est identifié en utilisant une mesure de distance (par exemple, la distance Euclidienne). Ce nœud est appelé le Best Matching Unit (BMU). Les poids du BMU et de ses voisins sont alors ajustés pour se rapprocher de l'entrée en utilisant une règle de mise à jour des poids basée sur la distance.
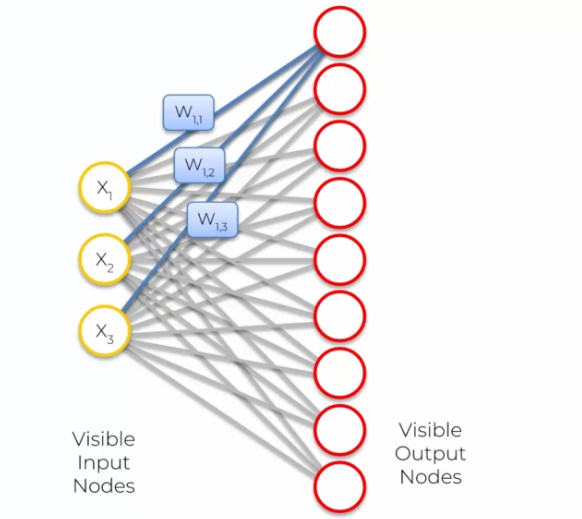
Cette mise à jour des poids des nœuds conduit à la formation d'une carte auto-organisatrice qui présente une topologie similaire à celle des données d'entrée. Les nœuds qui sont proches dans la carte ont des poids similaires, ce qui permet de visualiser la structure sous-jacente des données.
- Node1: (W1,1, W1,2, W1,3) car l'on a trois entrées !
- Node2: (W2,1, W2,2, W2,3) car l'on a trois entrées !
- ...
Mais pourquoi changeons nous cette manière de faire ? Car on créé une compétition entre les neurones de sortie. On passe dans chaque neurone pour savoir quelle neurone est le plus proche de la sortie : on obtient donc la distance :
- Node1 : Distance = 1.2
- Node2: Distance = 0.8
- ...
On a donc la distance pour chaque neurone qui correspond entre l'entrée et la sortie. La distance la plus courte est donc sélectionnée et le neurone gagnant est appelé BMU (Best Matching Unit). L'étape suivante est l'ajustement des poids de telle manière que le BMU soit le plus proche de notre entrée. On obtiendra donc une adaptation où on tire le neurone de sortie vers l'entrée :
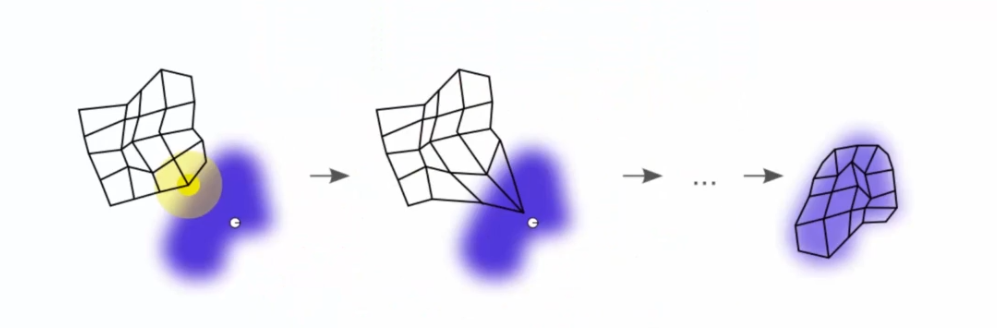
On a donc une adaptation de la map en continu. Mais comment ca se passe ? Prenons le cas de 5 BMUs coloriés par différente couleur :

Dans l'exemple, nous avons cinq BMUs colorés en différentes couleurs. Les neurones sont mis à jour pour se rapprocher des lignes les plus proches ainsi que de leur cercle d'influence. Chaque BMU tire les neurones vers lui pour atteindre un équilibre à la fin de chaque époque. Le processus se répète jusqu'à ce que la carte auto-organisatrice soit stabilisée.
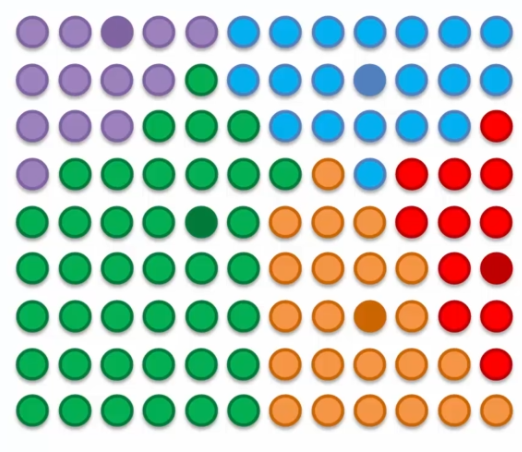
Le processus est de plus en plus précis à chaque époque car le rayon d'influence des BMUs est réduit. Ce processus permet de regrouper les données en clusters et de visualiser la structure sous-jacente des données. La carte auto-organisatrice peut être utilisée pour effectuer des tâches telles que la classification et la visualisation de données complexes.
Conclusion
Les SOMs retiennent la topologie du jeu d'entraînement en créant une carte auto-organisatrice qui préserve les relations topologiques entre les données. Cette caractéristique est importante car elle permet de visualiser les corrélations qui peuvent être difficiles à identifier autrement.
Contrairement aux techniques d'apprentissage supervisé, les SOMs ne nécessitent pas de cibles particulières car elles effectuent une catégorisation des données sans supervision. Les SOMs utilisent la compétition entre les neurones de sortie pour déterminer la BMU la plus proche de l'entrée et ajuster les poids en conséquence.
Il est également important de noter que les SOMs ne possèdent pas de connexions latérales entre les nœuds de sortie. Cela signifie que chaque nœud est indépendant et traite uniquement les entrées qui lui sont présentées. Cette caractéristique permet de traiter des données à grande échelle avec une grande efficacité et une faible complexité.





