 Français
FrançaisLes réseaux de neurones récurrents
Pour comprendre ceci nous avons besoin de comprendre notre cerveau :
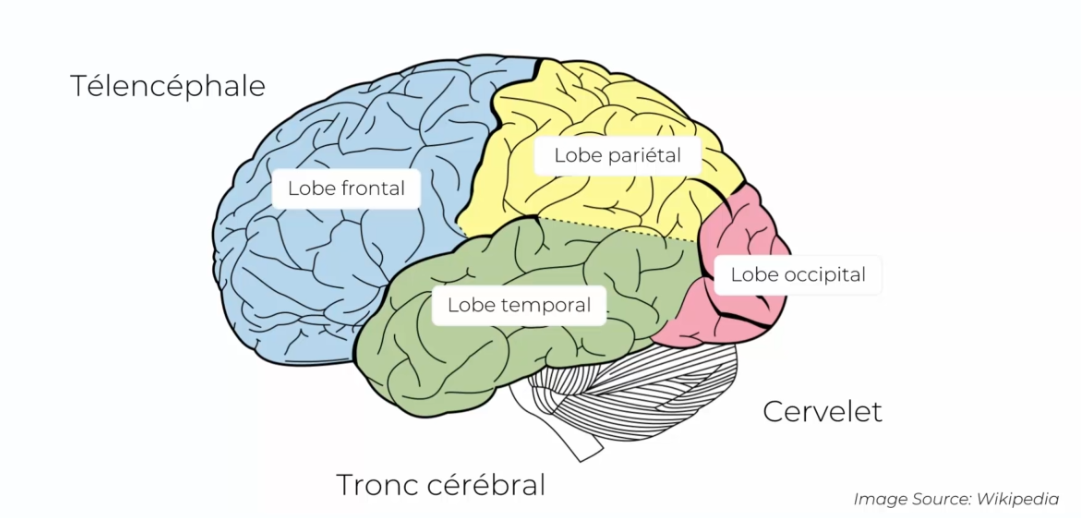
Notre cerveau, ou du moins la partie Télencéphale est composée de 4 parties:
- Lobe frontal
- Lobe pariétal (sensation perception)
- Lobe temporal
- Lobe occipital
Lorsque l'on crée un réseau de neurones, on a une notion de poids qui sont attachés à chaque synapse pour optimiser nos prédictions. On peut voir ces poids comme une mémoire à long terme, le cerveau n'oublie pas avec le temps : vous apprenez à faire du vélo, vos essais restent gravés dans votre mémoire. Cela sous-entend que cette partie représente notre Lobe temporal. Alors on retrouve dans tous les réseaux de neurones, mais plus particulièrement dans l'ANN dont c'est sa spécialité.
Lors de l'utilisation des réseaux de neurones à convolutions, ce réseau permettait de reconnaitre des images. On parle alors de notre vue d'humain qui est directement interprétée par le Lobe occipital.
Notre réseau de neurones récurrent lui correspond à notre mémoire à court terme. Ce réseau de neurones lui connait très bien ce qui s'est passé récemment et va s'en servir pour prédire ce qu'il va se passer plus tard, il représente le Lobe frontal.
OK, mais comment ça marche ?
On va partir d'un réseau de neurones normal :
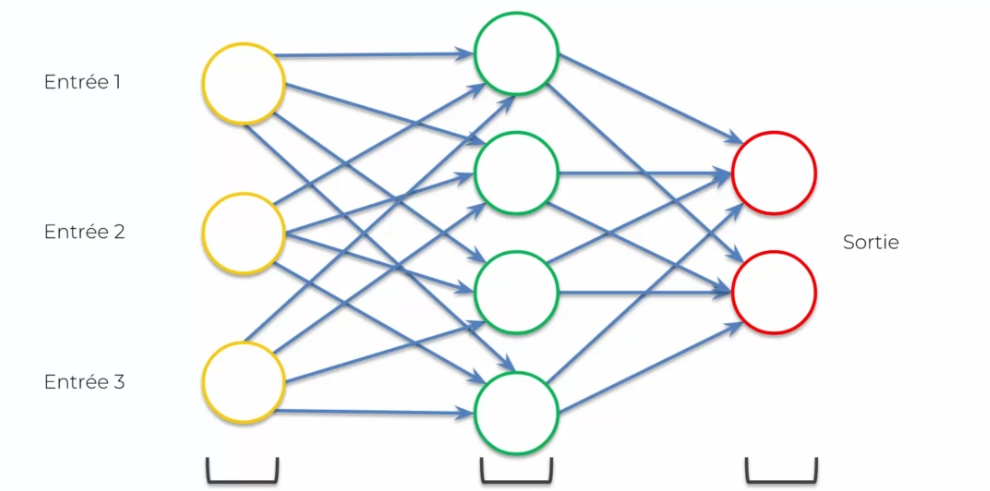
On va tout d'abord l'écraser :
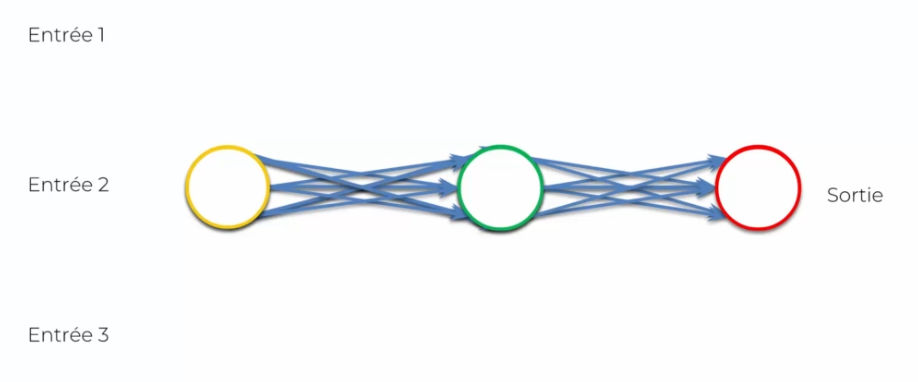
On peut penser que l'on a perdu de l'information, mais en réalité tout est encore là, rien n'a changé. En fait, ce n'est qu'une visualisation différente, mais on peut toujours la simplifier afin de voir ce réseau différemment :
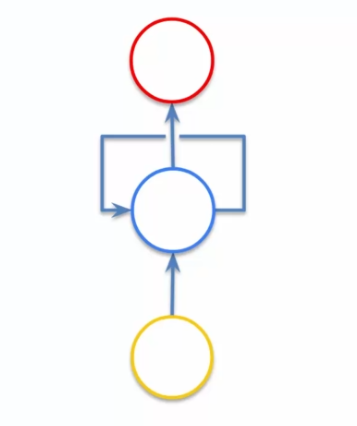
Notre réseau caché qui se trouve au milieu, créé une boucle temporelle. En gros le réseau caché envoi en sortie l'information, mais réutilise cette information directement après. On c'est un peu abstrait alors regardons ça d'un autre oeil :
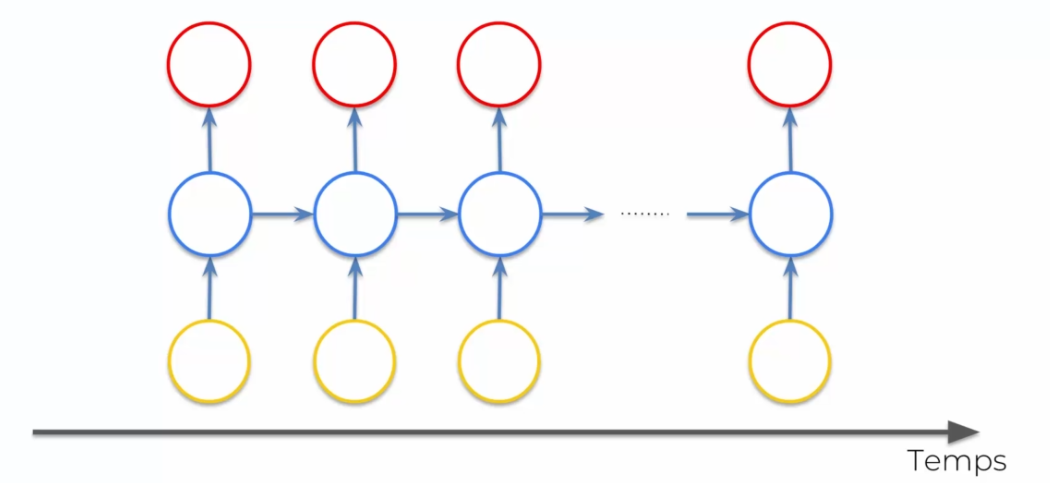
Le principe ici est qu'une information est réutilisée constamment dans le temps, même une fois traitée. On peut avoir :
- One-to-many : une entrée vers plusieurs sorties. Exemple: on essaie de décrire une image et si l'image correspond à un chat ou un chien. Le rôle du RNN sera de créer une phrase correcte, et non pas l'analyse de l'image.
- Many-to-one : plusieurs entrées vers une sortie. Exemple: l'analyse d'un texte qui permet de faire ressortir si ce texte est négatif ou positif. Ici il a besoin de comprendre la phrase pour donner une analyse.
- Many-to-many : plusieurs entrées vers plusieurs sorties. Exemple : google translate, on a plusieurs mots à traduire et de règle grammaticale, l'accord du genre par exemple...
Vanishing gradient
Lorsque l'on utilisait l'algorithme du gradient, on tentait de minimiser le cout. Ce qui se passait dans un ARR, on calculait la fonction de cout et on utilisait la rétropropagation pour appliquer le gradient ensuite (voir). Dans ce cas c'est différent, on fait une rétropropagation dans plusieurs sens, on a donc des neurones qui s'actualisent sur énormément d'étapes en arrière: 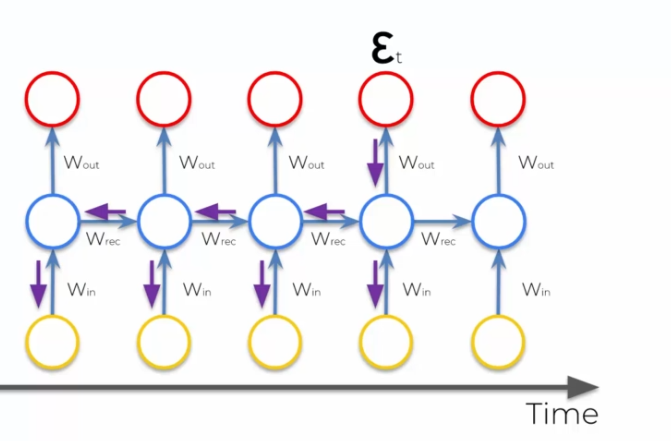
On a donc une multiplication de notre gradient qui est élevé au début, que l'on multiple ensuite par de petites valeurs (valeur entre 0 et 1), ce qui va le rendre de plus en plus petit. Cela pose un souci, car le gradient qui est là pour mettre à jour, devient de plus en plus inutile pour les réseaux éloignés, car ils ne seront pas suffisamment entrainés.
On aura donc la moitié du réseau entrainé et l'autre qui utilisera comme sortie la partie non entrainée, ce qui crée donc de mauvaises informations. On a un effet domino qui se crée, et des taux d'erreur énormes.
Long short term memory
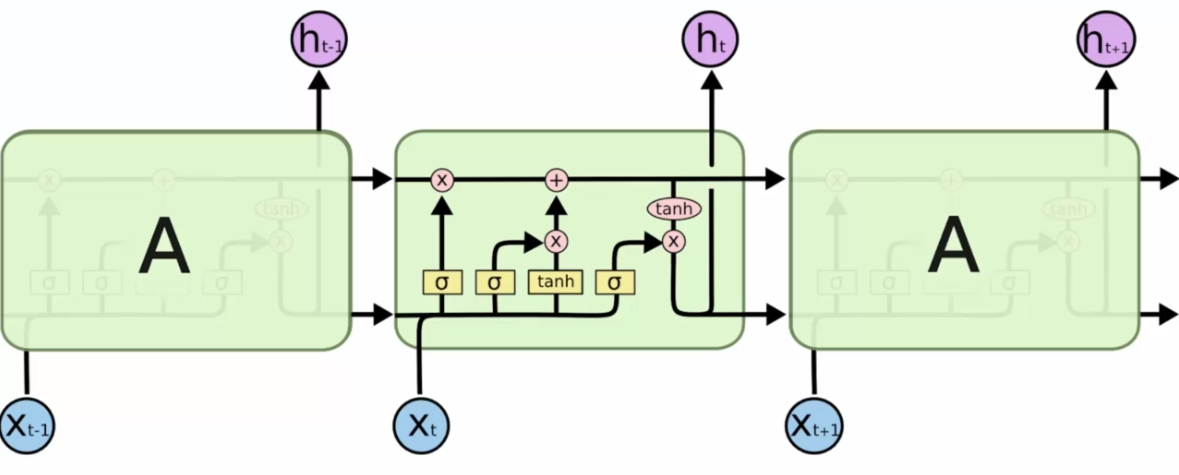
- Les flèches sont des transferts de vecteurs
- Quand deux flèches se croisent, on a une concaténation
- Quand deux flèches se séparent, on a une copie
- Les ronds roses correspondants à un système de valve, comme dans l'électricité, on peut choisir de les ouvrir ou les fermer
- Les rectangles jaunes sont des couches cachées
Comment ca marche
On a deux entrées, ces deux entrées rentrent dans un réseau caché, ici sigmoïde, qui déterminera si l'on ouvre la valve ou pas. On décide de savoir si oui ou non on interrompt le chemin de la mémoire :
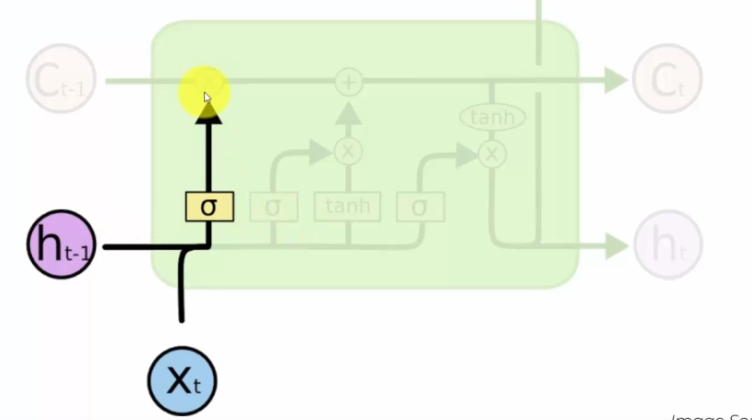
Xt est la nouvelle information entrante dans notre neurone. Ainsi Ht-1, représente la sortie du neurone précédent. Ici on parle de la valve de l'oublie, autrement dit on considère que l'information passante, si la valve est ouverte, comme pouvant être oubliee.
L'étape suivante consiste à déterminer quelles valeurs va être passée à travers la tangente hyperbolique et de savoir si oui ou non on ouvre la valve (sigmoïde). Cela permet de rajouter de l'information à la mémoire :
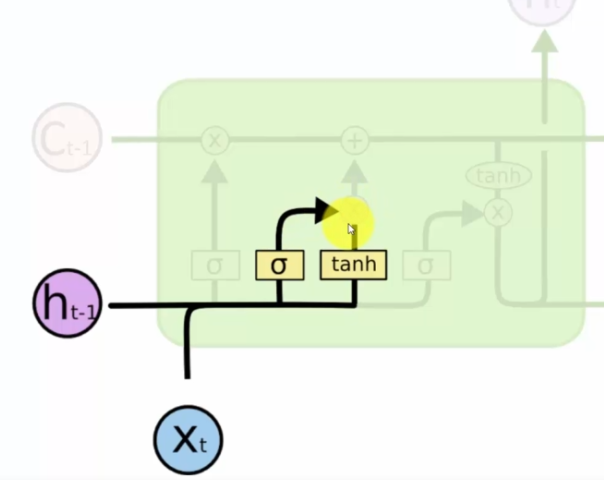
On parle alors de valve de la mémoire, qui si elle est ouverte viendra s'ajouter à la valeur de Ct-1, qui correspond à la mémoire passée de neurone en neurone.
On détermine ensuite quelle partie de la mémoire va partir dans la sortie :
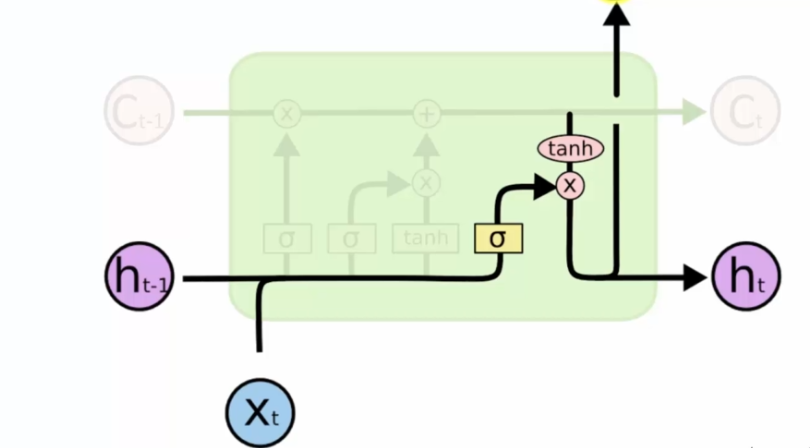
On est donc dans un système crucial qui déterminera la sortie ou non :
- Vers la mémoire
- Vers la sortie, dans ce cas la valeur est communiquée au neurone suivant par Ht
Ainsi on a plusieurs conditions qui permettent au réseau de neurones d'interpréter du texte. Chaque neurone deviendra responsable d'une partie de l'interprétation :
- Un neurone pour identifier les URLs
- Un neurone pour identifier des mots spéciaux
- Un neurone pour identifier la chaleur d'un mot (agressif, amical...)
Bref toute une série de neurones qui se spécialisent dans le but d'apprendre et interpréter du texte. C'est pourquoi dans notre cas, la notion de mémoire est très importante. En effet, celle-ci permettra au neurone de retenir, ligne par ligne les différentes étapes précédentes.
Ici nous avons la prédiction d'un neurone sur des caractères :
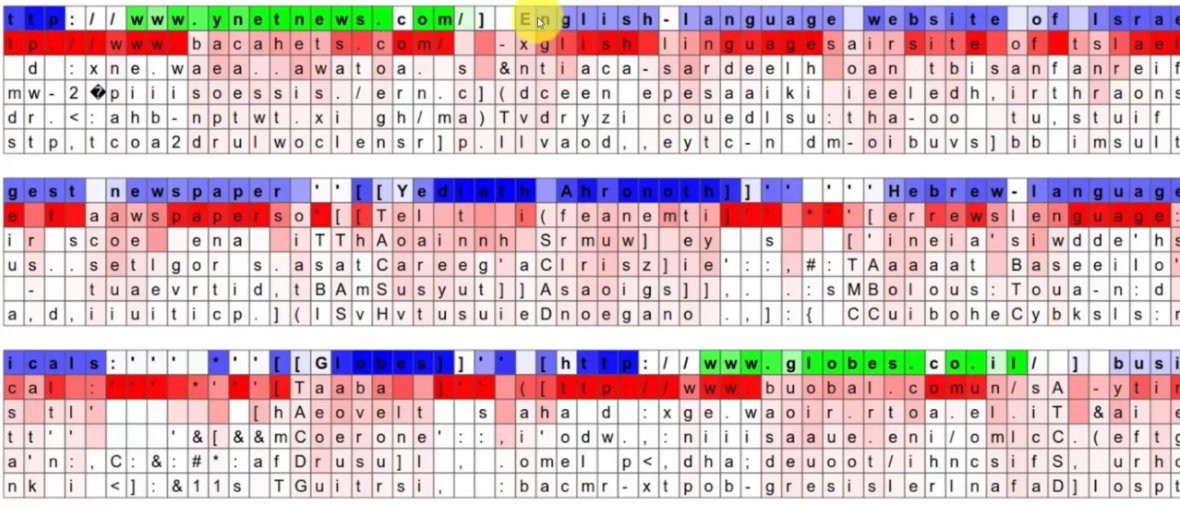
Il commence par la première ligne du texte :
- En vert, nous avons de bonnes prédictions et donc laisse passer en sortie (la valeur est proche de 1)
- En bleu, nous avons de mauvaises prédictions et donc ne laisse pas passer l'information en sortie (la valeur est proche de -1)
- En blanc, il n'a pas de prédiction
Il poursuit sur la deuxième ligne :
- On voit clairement que ce neurone est spécialisé dans la lecture d'URL
- On dit que : dans la deuxième ligne lorsque le caractère est rouge le neurone est "quasiment sûr" de sa prédiction. La certitude est marquée par un rouge plus significatif.
Variations des LSTMs
Variation numéro 1
Il arrive que l'on rajoute des lignes dans nos neurones : 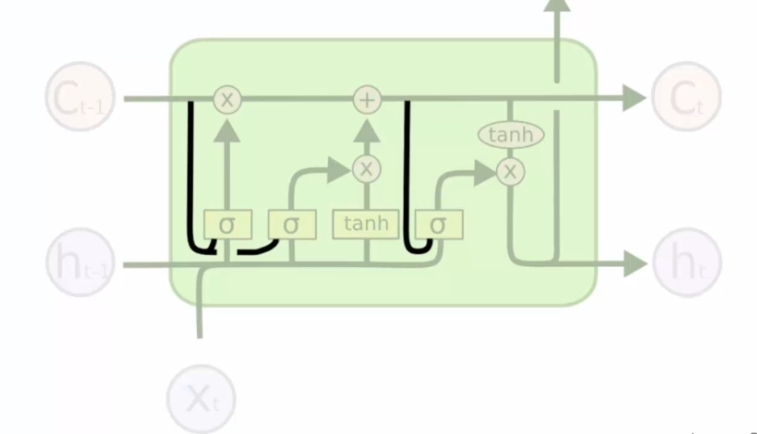
Cela permet de prendre en compte la mémoire (Ct-1) pour influencer sur les décisions. La mémoire dans ce cas a son mot à dire.
Variation numéro 2
On connecte la valve d'oublie (celle tout en haut à gauche X) avec la mémoire :
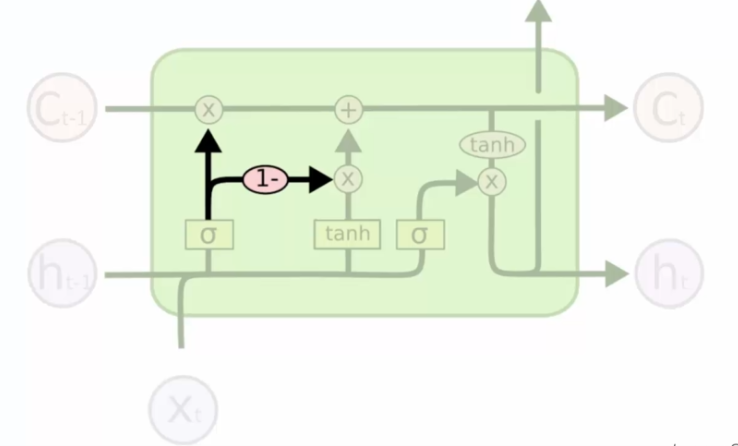
Précédemment on avait la possibilité de couper la mémoire à gauche et à droite de rajouter de l'information dans la mémoire. Maintenant au lieu de ça on a une décision pour les deux valves en même temps. La décision n'est pas la même :
- On ouvre la mémoire, cela ferme la vanne de l'oubli
- On ouvre la valve de l'oubli, on ferme celle de la mémoire
Variation numéro 3
On retire la ligne de mémoire (Ct+1), à la place on met l'information de sortie du réseau précédent (Ht-1) :
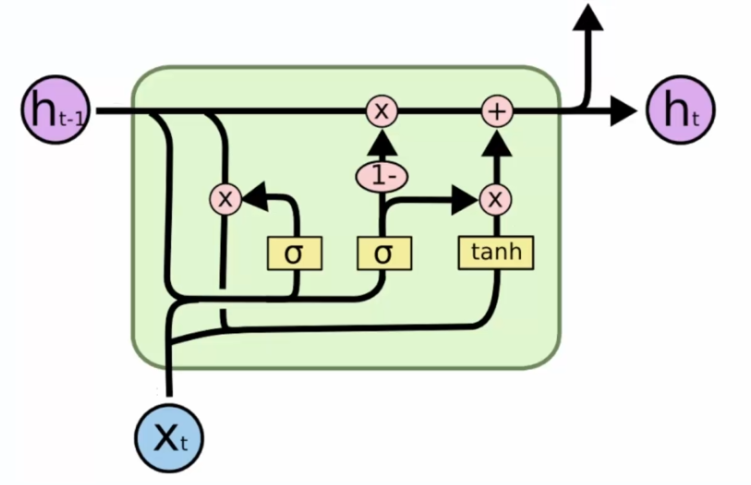
Du coup, on a plus qu'une seule valeur qui vient de la mémoire précédente, il y a moins de choses à contrôler.
Évaluation du réseau de neurones
Pour la régression, on évalue la performance du modèle grâce au RMSE (Root Mean Squared Error, ou Racine de l'Erreur Quadratique Moyenne). Le RMSE se calcule en prenant la racine carrée de la moyenne des différences au carré entre les prédictions et les valeurs réelles. Le RMSE est par défaut une bonne mesure de performance. Pour l'appliquer, on peut utiliser le code suivant :
import math
from sklearn.metrics import mean_squared_error
rmse = math.sqrt(mean_squared_error(real_stock_price, predicted_stock_price))
Amélioration
- Aller chercher plus de données : on a entraîné le modèle sur 5 ans, mais on pourrait essayer avec 10 ans de données.
- Augmenter le nombre de "timesteps" : on a choisi 60 dans les vidéos, ce qui correspond à environ 3 mois dans le passé. On pourrait augmenter ce nombre, par exemple à 120 (6 mois).
- Ajouter d'autres indicateurs : connaissez-vous d'autres entreprises dont l'action pourrait être corrélée à celle de Google ? On pourrait ajouter ces actions dans les données d'entraînement.
- Ajouter plus de couches LSTM : On a déjà 4 couches, mais peut-être qu'avec encore plus de couches, on obtiendrait de meilleurs résultats.
- Ajouter plus de neurones dans chaque couche LSTM : on a mis 50 neurones afin de capturer une certaine complexité dans les données, mais est-ce suffisant ? On pourrait essayer avec plus de neurones.





