 Français
FrançaisIntroduction
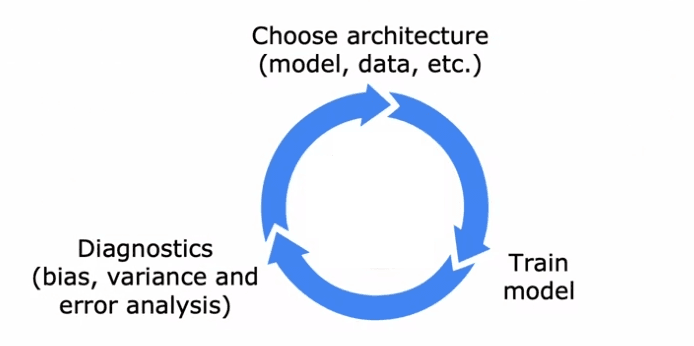
Le développement d'un système d'apprentissage machine peut être un processus complexe et itératif. Il implique le choix de l'architecture globale du système, la décision sur les données et les hyperparamètres à utiliser, et la mise en œuvre et la formation d'un modèle. Cependant, la première itération d'un modèle ne fonctionne souvent pas aussi bien que désiré. Pour améliorer les performances, il est nécessaire d'utiliser des diagnostics tels que l'analyse du biais et de la variance de l'algorithme et la conduite d'une analyse d'erreur. Sur la base des insights de ces diagnostics, des décisions peuvent être prises sur la façon d'ajuster l'architecture, telles que l'augmentation de la taille du réseau neuronal ou le changement du paramètre de régularisation. Ce processus est alors répété jusqu'à ce que les performances souhaitées soient atteintes.
Un exemple de ce processus peut être vu dans le développement d'un classificateur de courrier indésirable. Les courriers indésirables contiennent souvent des mots mal orthographiés et des tentatives de vente de produits, alors que les courriels légitimes n'en font pas. Une façon de construire un classificateur pour ce problème est de former un algorithme d'apprentissage supervisé en utilisant le texte du courriel comme caractéristiques d'entrée et l'étiquette de spam ou de non-spam en sortie. Les caractéristiques du courriel peuvent être construites de différentes façons, telles que l'utilisation des 10 000 mots les plus fréquents en anglais comme indicateurs binaires de leur apparition ou non dans le courriel, ou en comptant le nombre de fois où un mot donné apparaît.
Une fois le modèle initial formé, il existe de nombreuses façons potentielles d'améliorer sa performance. Par exemple, on peut collecter plus de données, développer des fonctionnalités plus sophistiquées ou créer des algorithmes pour détecter les fautes d'orthographe. Cependant, il peut être difficile de déterminer lesquelles de ces idées sont les plus prometteuses. En analysant le biais et la variance de l'algorithme et en effectuant une analyse d'erreur, il est possible de déterminer les zones du modèle qui ont le plus besoin d'amélioration et de prendre des décisions plus éclairées sur la façon de procéder. Cela peut grandement accélérer le processus de développement et améliorer la performance globale du modèle.
L'analyse d'erreurs
Diagnostiquer les performances d'un algorithme d'apprentissage est crucial pour l'améliorer. Il y a deux concepts importants dans ce contexte : le biais et la variance et l'analyse des erreurs. Dans cet article, nous plongerons dans ce que signifient ces deux concepts et comment ils peuvent vous aider à choisir quoi faire pour améliorer les performances de votre algorithme d'apprentissage.
Le biais et la variance sont des concepts importants pour comprendre les performances d'un algorithme d'apprentissage. Le biais fait référence à l'erreur introduite par la simplification de données du monde réel avec un modèle plus simple. La variance fait référence à la quantité d'erreur introduite par la complexité du modèle. Un biais élevé et une faible variance indiquent un sous-ajustement, tandis qu'une variance élevée et un faible biais indiquent un sur-ajustement.
L'analyse des erreurs, d'un autre côté, est le processus de vérification manuelle des exemples mal classifiés par l'algorithme. Cela vous aide à comprendre où l'algorithme se trompe. Pour effectuer une analyse des erreurs, prenez un ensemble d'exemples mal classifiés de l'ensemble de validation croisée et essayez de les regrouper en thèmes ou propriétés communs. Par exemple, si de nombreux exemples mal classifiés sont des e-mails de spam pharmaceutiques, comptez combien il y en a et essayez de trouver des traits communs. Ce processus peut révéler des domaines où votre algorithme d'apprentissage est faible et où des améliorations peuvent être apportées.
Ajout de données
L'augmentation de données pour les applications de l'apprentissage automatique
Les algorithmes d'apprentissage automatique sont souvent limités par la quantité de données qu'ils peuvent utiliser pour l'entraînement. C'est pourquoi les techniques d'augmentation de données peuvent être utiles pour augmenter la taille de l'ensemble d'entraînement et aider à améliorer les performances de ces algorithmes. Dans cet article, nous explorerons quelques conseils pour ajouter des données à votre application d'apprentissage automatique, y compris des techniques d'augmentation de données.
Ajout de données
L'une des façons les plus simples d'ajouter des données est simplement d'obtenir plus d'exemples de tout. Cependant, cette approche peut être lente et coûteuse. Une alternative plus efficace consiste à se concentrer sur l'ajout de données des types où l'analyse d'erreur a indiqué que cela pourrait aider. Par exemple, si vous entraînez un algorithme d'apprentissage automatique pour reconnaître les pourriels pharmaceutiques et qu'il a des difficultés avec cette tâche, vous pourriez vous concentrer sur l'ajout de plus d'exemples de pourriels pharmaceutiques plutôt que d'essayer simplement d'obtenir plus de données de tous les types.
L'augmentation de données
L'augmentation de données est une technique pour créer de nouveaux exemples à partir de données d'entraînement existantes, ce qui peut augmenter considérablement la taille de votre ensemble d'entraînement. Cette technique est souvent utilisée pour les données d'images et de sons.
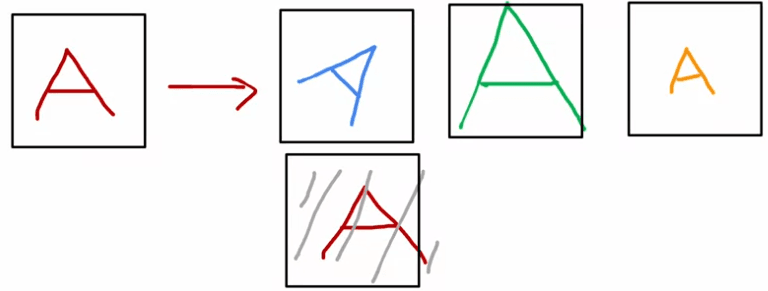
Par exemple, si vous entraînez un algorithme de reconnaissance optique des caractères pour reconnaître les lettres de A à Z, vous pouvez utiliser l'augmentation de données pour créer de nouveaux exemples d'entraînement à partir d'une seule image de la lettre A. Cela peut inclure la rotation de l'image, son agrandissement ou sa réduction, le changement de son contraste, ou même la prise de son image en miroir. En faisant cela, vous indiquez à l'algorithme que la lettre A est toujours la lettre A, même lorsqu'elle est tournée ou déformée de manière différente.
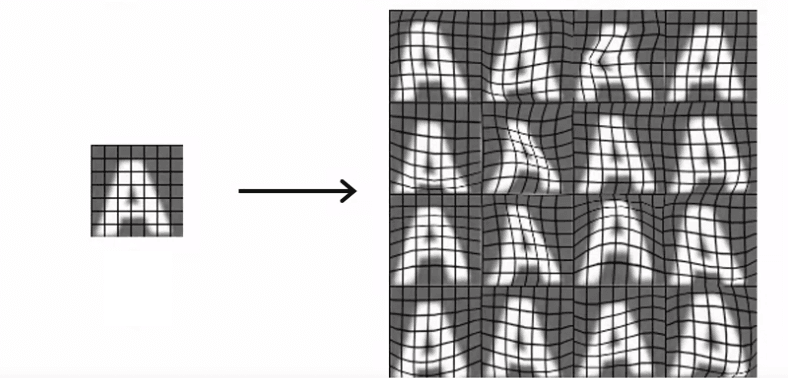
Un exemple plus avancé d'augmentation de données consisterait à introduire une déformation aléatoire à une lettre A à l'aide d'une grille placée sur le dessus de la lettre. Ce processus de distorsion de l'image peut transformer un exemple d'entraînement en plusieurs, permettant à l'algorithme d'apprendre plus robustement à quoi ressemble la lettre A.
L'augmentation de données peut également être appliquée à la reconnaissance vocale. Par exemple, vous pouvez utiliser un bruit de fond bruyant pour créer de nouveaux exemples à partir d'un clip audio original de quelqu'un demandant la météo. En faisant cela, vous indiquez à l'algorithme que la parole devrait toujours être reconnaissable même avec du bruit de fond.
L'augmentation de données est une technique précieuse pour augmenter la taille de votre ensemble d'entraînement et aider vos algorithmes d'apprentissage automatique à mieux performer. Que vous travailliez sur la reconnaissance d'images ou de sons, l'augmentation de données peut vous aider à tirer le meilleur parti de vos données d'entraînement existantes.
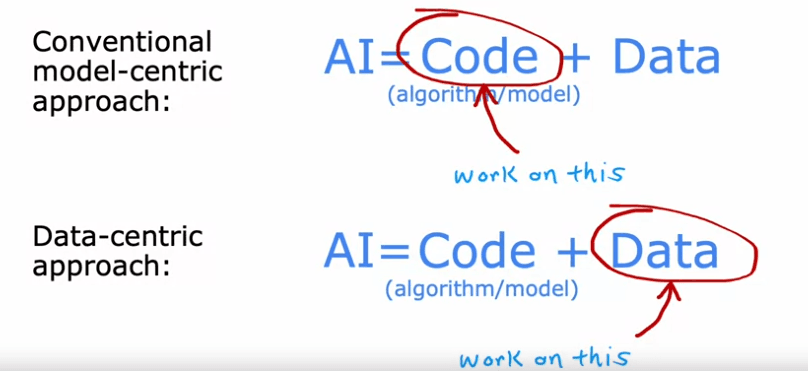
L'apprentissage par transfert
L'apprentissage par transfert est une technique précieuse en apprentissage automatique qui vous permet d'utiliser les données d'une tâche pour améliorer les performances sur une autre tâche. Cela est particulièrement utile lorsque vous n'avez pas une grande quantité de données pour votre tâche spécifique. Dans cet article, nous explorerons comment fonctionne l'apprentissage par transfert et comment vous pouvez l'implémenter dans vos propres applications.
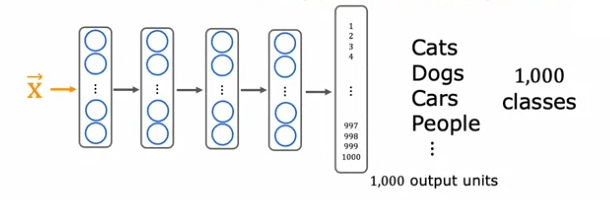
Commençons par un exemple concret : la reconnaissance de chiffres manuscrits de zéro à neuf. Si vous n'avez pas beaucoup de données étiquetées pour cette tâche, vous pouvez toujours utiliser l'apprentissage par transfert pour améliorer les performances de votre modèle. Par exemple, vous pouvez commencer par entraîner un réseau neuronal sur un grand ensemble de données de plus d'un million d'images de chats, de chiens, de voitures, de personnes, etc., avec 1000 classes différentes. En faisant cela, vous apprenez les paramètres pour la première couche du réseau neuronal (W^1, b^1), la deuxième couche (W^2, b^2), et ainsi de suite, jusqu'à la couche de sortie (W^5, b^5).
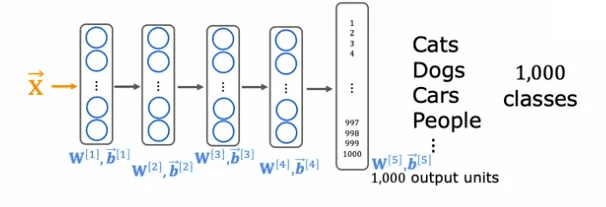
Pour appliquer l'apprentissage par transfert, vous faites une copie de ce réseau neuronal et le modifiez pour ne reconnaître que les chiffres de zéro à neuf en supprimant la dernière couche et en la remplaçant par une couche de sortie plus petite de 10 unités au lieu de 1000. Les nouveaux paramètres (W^5, b^5) doivent être entraînés à partir de zéro, tandis que les paramètres des couches précédentes peuvent être utilisés comme point de départ.
Il y a deux options pour l'entraînement du nouveau réseau :
- Entraînez uniquement les paramètres de la couche de sortie (W^5, b^5). Vous utilisez les paramètres des quatre premières couches tels quels et utilisez des algorithmes d'optimisation tels que la descente de gradient stochastique ou Adam pour mettre à jour uniquement W^5, b^5.
- Entraînez tous les paramètres du réseau (W^1, b^1 à W^5, b^5). Vous initialisez les paramètres des quatre premières couches avec les valeurs du réseau d'origine, puis les affinez en utilisant la descente de gradient.
La première étape de l'entraînement de l'ensemble de données volumineux s'appelle l'apprentissage supervisé préalable, tandis que la deuxième étape d'affiner les paramètres pour s'adapter à votre tâche spécifique s'appelle l'affinage. Si vous avez un petit ensemble de données, l'utilisation d'un modèle pré-entraîné peut considérablement améliorer les performances. De plus, vous n'avez pas besoin de former le modèle vous-même, car de nombreux chercheurs ont déjà formé des réseaux neuronaux sur de grands ensembles de données et les ont publiés en ligne gratuitement. Tout ce que vous avez à faire est de télécharger un modèle pré-entraîné, de remplacer la couche de sortie par la vôtre et de l'affiner pour s'adapter à votre tâche.
En conclusion, l'apprentissage par transfert est une technique puissante qui peut vous aider à obtenir de bonnes performances même avec des données limitées. En exploitant le travail des autres dans la communauté de l'apprentissage automatique, vous pouvez rapidement former un modèle de haute qualité pour votre tâche spécifique.
Cycle complet d'un cycle d'apprentissage automatique
- Définir le projet : décider de l'objectif et des objectifs du projet. Dans cet exemple, la reconnaissance vocale pour la recherche vocale sur les téléphones mobiles est le projet.
- Collecte de données : déterminer les données requises pour former le système d'apprentissage automatique et rassembler des fichiers audio et des transcriptions des étiquettes.
- Entraînement du modèle : entraîner le système de reconnaissance vocale, effectuer une analyse d'erreur et améliorer itérativement le modèle en collectant plus de données ou en augmentant les données existantes.
- Déploiement : déployer le modèle d'apprentissage automatique performant dans un environnement de production, le rendant disponible pour les utilisateurs.
- Maintenance : surveiller les performances du système déployé et le maintenir en cas de détérioration des performances.
- Amélioration du modèle : si les performances ne sont pas satisfaisantes, revenez à l'entraînement du modèle ou à la collecte de plus de données à partir du déploiement de production.
Ensuite, nous le déployons en production :
- Serveur d'inférence : Implémentez le modèle d'apprentissage automatique entraîné dans un serveur d'inférence pour faire des prédictions.
- Appel API : L'application mobile appelle l'API du serveur d'inférence, en passant le clip audio et en recevant les transcriptions de texte de ce qui a été dit.
- Ingénierie logicielle : Selon l'échelle de l'application, l'ingénierie logicielle peut être nécessaire pour garantir que le serveur d'inférence peut faire des prédictions fiables et efficaces et gérer le nombre d'utilisateurs.
- Enregistrement de données : Enregistrez les données d'entrée et de prédiction, en supposant que la confidentialité et le consentement de l'utilisateur le permettent. Les données sont utiles pour la surveillance et l'amélioration du système.
Équité, biais et éthique
L'apprentissage automatique est un domaine en croissance rapide qui a le potentiel d'impacter des milliards de personnes. Comme pour toute technologie, il est important de considérer les implications éthiques de son utilisation et de veiller à ce que les systèmes que nous construisons soient justes, impartiaux et sans danger.
Malheureusement, l'histoire de l'apprentissage automatique est remplie d'exemples de systèmes qui ont montré des niveaux inacceptables de biais et de discrimination. Par exemple, il y a eu des cas d'algorithmes de recrutement qui discriminent les femmes et de systèmes de reconnaissance faciale qui font correspondre des individus à la peau foncée à des photos de criminels plus souvent que des individus à la peau claire. Il est crucial que nous, en tant que communauté, prenions des mesures pour prévenir le déploiement de tels systèmes biaisés.
En plus des problèmes de biais et d'équité, il y a également eu des cas d'utilisation négatifs d'algorithmes d'apprentissage automatique. Par exemple, il y a eu des vidéos deepfake créées sans consentement ou divulgation, et des algorithmes de médias sociaux qui ont propagé des discours toxiques ou incendiaires. Certaines personnes ont même utilisé l'apprentissage automatique pour commettre des fraudes ou pour construire des produits nuisibles.
Étant donné l'impact potentiel de l'apprentissage automatique sur la société, il est important d'aborder le développement de ces systèmes avec un fort sens de l'éthique. Cela comprend l'assemblage d'une équipe diversifiée qui peut apporter des perspectives différentes à la table, la recherche de normes et de directives de l'industrie et la réalisation d'un audit approfondi du système avant le déploiement.
Bien que l'éthique soit un sujet complexe et multifacette, il est toujours possible de prendre des mesures pour garantir que notre travail soit plus juste, moins biaisé et plus éthique. Il incombe à chacun de nous de prendre cette responsabilité au sérieux et de faire un impact positif avec les systèmes que nous construisons.





