 Français
FrançaisIntroduction
À l'ère numérique d'aujourd'hui, la capacité de comprendre et de traiter le langage humain est devenue un aspect crucial de l'avancement technologique. Le traitement du langage naturel (NLP) se trouve à l'avant-garde de cette révolution, stimulant le développement de systèmes intelligents capables de comprendre et de communiquer avec les humains sans effort. Grâce à une combinaison de la linguistique, de l'informatique et de l'intelligence artificielle, le NLP permet aux machines de décrypter les nuances du discours et du texte humains, ouvrant un monde de possibilités dans divers domaines. Des assistants vocaux qui répondent à nos commandes aux chatbots qui engagent des conversations significatives, le NLP est apparu comme une force transformatrice, remodelant la façon dont nous interagissons avec la technologie. Cet article explore les complexités du NLP, mettant en évidence ses applications, ses défis et ses implications profondes pour les industries et la société dans son ensemble. Rejoignez-nous alors que nous découvrons la puissance du NLP et explorons comment il révolutionne l'avenir de la communication homme-machine.
Codages basés sur des mots
Les limites du codage des caractères : déverrouiller le sens au niveau des mots
Lorsqu'il s'agit de comprendre la signification des mots en utilisant des codages de caractères, les limites deviennent rapidement apparentes. Prenez, par exemple, le mot 'LISTEN,' codé en valeurs ASCII.
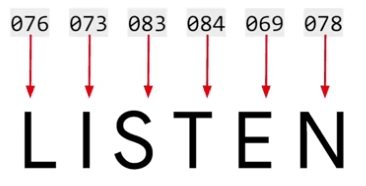
Bien que ce codage capture les caractères du mot, il ne parvient pas à transmettre la sémantique derrière celui-ci. En fait, considérez le mot 'SILENT,' qui partage les mêmes lettres que 'LISTEN' mais a un sens complètement différent.
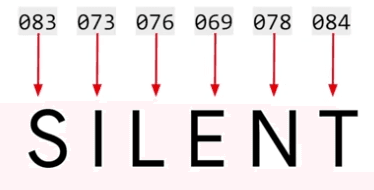
Cela démontre l'insuffisance des codages de caractères pour capturer la sémantique au niveau des mots.
Passer au codage au niveau des mots : une approche prometteuse
Pour surmonter les lacunes du codage des caractères, une évolution vers le codage au niveau des mots apparaît comme une approche plus prometteuse. En attribuant une valeur unique à chaque mot, nous pouvons saisir l'essence du mot et utiliser ces valeurs pour entraîner un réseau neuronal. Par exemple, considérons la phrase "J'aime mon chien." En attribuant des valeurs à chaque mot, comme 'J'' à 1, 'aime' à 2, 'mon' à 3 et 'chien' à 4, nous pouvons représenter la phrase comme la séquence 1, 2, 3, 4.
Flexibilité dans le codage des phrases et la création de tokens
Le codage au niveau des mots offre une flexibilité lors de la rencontre de nouvelles phrases. Supposons que nous ayons la phrase "J'aime mon chat." Comme nous avons déjà codé les mots 'J'aime mon' comme 1, 2, 3, nous pouvons réutiliser ces valeurs. Pour représenter 'chat,' qui est un nouveau token, nous lui attribuons le numéro 5. En comparant les codages des deux phrases, 'J'aime mon chien' est représenté comme 1, 2, 3, 4, tandis que 'J'aime mon chat' devient 1, 2, 3, 5. Cette similitude entre les codages des phrases forme une base pour l'entraînement de réseaux neuronaux basés sur des mots.
Simplifier le processus avec les API TensorFlow et Keras
Heureusement, des frameworks tels que TensorFlow et Keras fournissent des API pratiques qui simplifient le processus de codage au niveau des mots et de formation de réseaux neuronaux. Ces outils permettent aux chercheurs et aux développeurs d'utiliser efficacement les valeurs de mots et de construire des modèles robustes capables de comprendre et de traiter le langage humain à un niveau plus profond.
En adoptant le codage au niveau des mots, nous pouvons débloquer une compréhension plus nuancée de la langue et poser les bases de systèmes de traitement du langage naturel plus sophistiqués. Dans les sections suivantes, nous explorerons plus en profondeur les applications, les techniques et les avancées du NLP qui utilisent le codage au niveau des mots, nous rapprochant de la réduction de l'écart entre les humains et les machines.
Tensorflow
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.text import Tokenizer
sentences = [
'J'aime mon chien',
'J'aime mon chat'
]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
-
Codage des phrases : La méthode fit_on_texts du tokenizer est utilisée pour encoder les phrases fournies. Elle analyse les données textuelles et génère les codages de mots nécessaires en fonction de leur fréquence.
-
Dictionnaire d'index de mots : Après avoir encodé les phrases, le tokenizer fournit une propriété word_index, qui renvoie un dictionnaire contenant des paires clé-valeur. Chaque clé représente un mot, et la valeur correspondante est son jeton.
-
Gestion de la ponctuation et de la capitalisation : Le tokenizer gère automatiquement la ponctuation et la capitalisation. Il traite les mots avec différentes ponctuations ou capitalisations comme le même mot, garantissant ainsi une cohérence dans les encodages.
-
Nouveau texte et tokenisation : Si un nouveau texte est introduit, le tokenizer l'incorpore sans problème dans l'index de mots existant. Il attribue des tokens à tous les nouveaux mots et maintient les encodages précédents.
Résultat :
{'i': 1, 'aime': 2, 'mon': 3, 'chien': 4, 'chat': 5}
Texte en séquence
Pour commencer, créons une liste de séquences en codant des phrases à l'aide des tokens générés. À des fins de démonstration, j'ai mis à jour le code sur lequel nous avons travaillé. Notez que toutes les phrases précédentes étaient composées de quatre mots, mais maintenant nous allons introduire une phrase plus longue. Dans l'extrait de code ci-dessous, j'invoque simplement le tokenizer pour convertir les textes en séquences, ce qui donne la sortie suivante :
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing ?'
]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)
Résultat:
{'my': 1, 'love': 2, 'dog': 3, 'i': 4, 'you': 5, 'cat': 6, 'do': 7, 'think': 8, 'is': 9, 'amazing': 10}
[[4, 2, 1, 3], [4, 2, 1, 6], [5, 2, 1, 3], [7, 5, 8, 1, 3, 9, 10]]
En exécutant le code, vous observerez un nouveau dictionnaire en haut, contenant des tokens pour des mots supplémentaires comme "incroyable," "penser," "est," et "faire." En bas, la liste des phrases a été encodée en listes d'entiers, où les tokens remplacent les mots originaux. Par exemple, "I love my dog" devient "4, 2, 1, 3." Un aspect important à noter est que la fonction text_to_sequences peut gérer n'importe quel ensemble de phrases, les encodant en fonction de l'ensemble de mots appris à partir des données d'entraînement. Cette fonctionnalité devient particulièrement précieuse lors de l'inférence avec un modèle entraîné, car le texte d'entrée doit être encodé en utilisant le même index de mots pour obtenir des résultats significatifs.
Inférence et cohérence de l'index des mots:
Considérez l'extrait de code suivant. Pouvez-vous prédire le résultat ?
# Try with words that the tokenizer wasn't fit to
test_data = [
'i really love my dog',
'my dog loves my manatee'
]
# Generate the sequences
test_seq = tokenizer.texts_to_sequences(test_data)
# Print the word index dictionary
print("\nWord Index = " , word_index)
# Print the sequences with OOV
print("\nTest Sequence = ", test_seq)
# Print the padded result
padded = pad_sequences(test_seq, maxlen=10)
print("\nPadded Test Sequence: ")
print(padded)
En exécutant le code, la sortie sera comme suit :
[[4,2,1,3],[1,3,1]]
Dans les exemples fournis, la phrase "J'aime vraiment mon chien" reste codée comme "4, 2, 1, 3," tandis que le mot "vraiment" est perdu car il n'existe pas dans l'index des mots. D'autre part, "mon chien aime mon lamantin" est codé comme "1, 3, 1," représentant "mon chien mon."
Gérer les mots invisibles et le remplissage
Pour éviter des structures de phrases indésirables comme "mon chien mon", il est essentiel d'avoir un ensemble de données d'entraînement diversifié et vaste. Un vocabulaire large est nécessaire pour capturer efficacement les nuances de la langue. En exposant le réseau neuronal à une large gamme d'exemples, nous augmentons les chances de générer des phrases cohérentes. La qualité et la taille des données d'entraînement jouent un rôle crucial dans la réalisation de cet objectif.
Gestion des mots invisibles
Dans certains cas, il est bénéfique de gérer les mots invisibles au lieu de les ignorer complètement. Plutôt que d'ignorer ces mots, nous pouvons leur attribuer une valeur spéciale pour les représenter. Cela peut être accompli en utilisant une propriété appelée "oov_token" dans le constructeur de tokenizer. En spécifiant un jeton "oov" (hors vocabulaire), nous indiquons que tous les mots non présents dans l'index des mots doivent être représentés par ce jeton. Il est important de choisir une valeur unique et reconnaissable qui ne sera pas confondue avec un mot réel. Regardons un exemple :
tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")
En exécutant ce code, les séquences de test résultantes ressembleraient à ce qui suit :
{'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
[[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
Par exemple, la première phrase devient "i en dehors du vocabulaire, love my dog," et la deuxième phrase devient "my dog oov, my oov." Bien que la syntaxe ne soit pas encore parfaite, cela démontre une amélioration en incorporant le jeton "oov". À mesure que le corpus d'entraînement s'élargit et que davantage de mots sont inclus dans l'index des mots, la couverture des phrases précédemment invisibles devrait s'améliorer.
Rembourrage pour l'uniformité
De manière similaire à la nécessité de tailles d'images uniformes lors de l'entraînement avec des images, les données textuelles nécessitent également un niveau d'uniformité avant l'entraînement avec des réseaux neuronaux. Pour y parvenir, nous pouvons nous appuyer sur le concept de rembourrage. Le rembourrage implique l'ajout de jetons ou de valeurs spéciaux aux phrases pour garantir qu'elles aient toutes la même longueur. Ce processus aligne les données textuelles et les rend compatibles avec les architectures de réseaux neuronaux. En rembourrant, nous pouvons traiter les phrases comme des unités uniformes pendant l'entraînement, permettant un apprentissage et un traitement efficaces.
Rembourrage
Pour commencer, nous devons importer la fonction pad_sequences de tensorflow.keras.preprocessing.sequence. Une fois que le tokenizer a généré les séquences, nous pouvons les passer à pad_sequences pour appliquer le rembourrage. Voici un exemple de comment l'utiliser :
de tensorflow.keras.preprocessing.sequence importer pad_sequences
# Extrait de code pour générer des séquences en utilisant le tokenizer
# Rembourrage des séquences
padded_sequences = pad_sequences(sequences)
Le résultat est une représentation claire des séquences rembourrées. Vous pouvez observer que la liste des phrases a été transformée en une matrice, où chaque rangée a la même longueur.
{'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
[[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
[[ 0 0 0 0 0 0 5 3 2 4]
[ 0 0 0 0 0 0 5 3 2 7]
[ 0 0 0 0 0 0 6 3 2 4]
[ 0 0 0 8 6 9 2 4 10 11]]
Le processus de rembourrage insère le nombre approprié de zéros au début de la phrase. Par exemple, une phrase comme "5-3-2-4" ne nécessite pas de rembourrage, tandis que des phrases plus longues peuvent ne pas avoir besoin de rembourrage non plus. Il est à noter que dans certains exemples, le rembourrage se produit après la phrase plutôt qu'avant. Si vous préférez cette dernière approche, vous pouvez modifier le code en ajoutant le paramètre padding='post'.
Définition de la longueur maximale et gestion des phrases dépassant
Par défaut, la largeur de la matrice résultante correspond à la longueur de la phrase la plus longue. Cependant, vous pouvez remplacer ce comportement en utilisant le paramètre maxlen. Par exemple, si vous souhaitez limiter vos phrases à un maximum de cinq mots, vous pouvez définir maxlen=5. Il est important de considérer que si vous avez des phrases plus longues que la longueur maximale spécifiée, des informations seront perdues. Par défaut, la troncature se produit au début de la phrase (troncature='pre'). Si vous préférez tronquer à partir de la fin, vous pouvez utiliser le paramètre truncating='post'.
Gestion de données plus complexes:
Jusqu'à présent, nous avons démontré l'encodage, le rembourrage et la gestion de phrases précédemment inconnues en utilisant des exemples de données codées en dur. Cependant, reconnaissons que les scénarios du monde réel impliquent souvent des données plus complexes. Dans la section suivante, nous explorerons comment appliquer ces techniques pour gérer des ensembles de données plus complexes et diversifiés.
Détection du sarcasme
Les ensembles de données publics sont des ressources inestimables pour l'entraînement des réseaux neuronaux, offrant des données et des aperçus du monde réel. Dans cet article, nous explorerons le processus de préparation d'un ensemble de données public spécifiquement axé sur la détection du sarcasme. Notre ensemble de données de choix est un ensemble de données fascinant du domaine public CC0 créé par Rishabh Misra, qui peut être trouvé sur Kaggle. Avec sa structure simple et sa simplicité, cet ensemble de données est un point de départ idéal pour l'entraînement d'un réseau neuronal.
L'ensemble de données se compose de trois éléments essentiels: l'étiquette de sarcasme, le titre et le lien de l'article correspondant. Bien que l'analyse du contenu HTML des articles et la suppression des scripts et des styles dépassent le cadre de cet article, nous nous concentrerons uniquement sur les titres. Pour faciliter le chargement des données dans Python, une légère modification du format de l'ensemble de données est recommandée. Sinon, vous pouvez télécharger l'ensemble de données pré-formaté fourni dans le code accompagnant cet article.
Une fois l'ensemble de données correctement formaté, le chargement dans Python devient une tâche simple. La bibliothèque json s'avère très utile à cet égard, nous permettant de charger et d'analyser l'ensemble de données au format JSON sans effort. Voici une ventilation étape par étape du processus:
- Importer la bibliothèque json pour gérer les données JSON.
- Ouvrir le fichier de l'ensemble de données en utilisant la fonction open().
- Charger l'ensemble de données en utilisant json.load(file), où file est le fichier de l'ensemble de données ouvert.
- Créer des listes séparées pour stocker les phrases, les étiquettes et les URL extraites de l'ensemble de données.
- Parcourir l'ensemble de données en utilisant une boucle for.
- Pour chaque élément de l'ensemble de données, extraire le titre, l'étiquette is_sarcastic et le lien de l'article, et les ajouter aux listes respectives.
with open("data/sarcasm.json", 'r') as f:
datastore = json.load(f)
# Non-sarcastic headline
print(datastore[0])
# Sarcastic headline
print(datastore[20000])
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])
En suivant ces étapes, vous pouvez structurer efficacement l'ensemble de données, le préparant ainsi pour un traitement ultérieur et l'entraînement d'un réseau neuronal. Les phrases peuvent être utilisées pour la tokenisation, les étiquettes pour l'entraînement du modèle, et les URL pour des analyses supplémentaires si nécessaire.
Suppression des Stopwords
La suppression des stopwords est importante lors du travail avec des données textuelles car ces mots ne portent généralement pas de signification significative ou ne contribuent pas beaucoup au contexte ou à la classification du texte. Les stopwords sont des mots couramment utilisés dans une langue, tels que les articles (par exemple, "le", "la", "un", "une"), les conjonctions (par exemple, "et", "mais", "ou"), les prépositions (par exemple, "dans", "sur", "à"), et d'autres mots fréquemment utilisés.
En supprimant les stopwords, nous pouvons réduire la dimensionnalité des données textuelles et nous concentrer sur les mots qui sont plus informatifs et discriminants pour la tâche à accomplir. Cela peut conduire à une amélioration des performances dans des tâches de traitement du langage naturel telles que la classification de texte, l'analyse des sentiments, la modélisation des sujets et la récupération de l'information.
Les stopwords apparaissent souvent en grande quantité dans différents documents ou textes, et leur inclusion peut introduire du bruit et rendre plus difficile pour les algorithmes d'apprentissage automatique d'identifier des motifs et d'extraire des caractéristiques significatives. Leur suppression permet à l'algorithme de se concentrer sur les mots plus importants qui portent l'essence du texte.
De plus, la suppression des stopwords peut également aider à améliorer l'efficacité computationnelle. En éliminant les mots communs et moins significatifs, nous pouvons réduire la taille des données et accélérer le temps de traitement pour diverses tâches d'analyse de texte.
Cependant, il convient de mentionner que l'ensemble des stopwords peut varier en fonction de la tâche spécifique, du domaine ou de la langue analysée. Différentes langues ont différents ensembles de stopwords, et il peut y avoir des stopwords spécifiques au domaine qui doivent être pris en compte. Par conséquent, il est important de choisir une liste de stopwords appropriée ou même de la personnaliser en fonction des exigences spécifiques de la tâche et des caractéristiques des données textuelles en cours de traitement.
words = sentence.split()
words = [word for word in words if word not in stopwords]
sentence = ' '.join(words)
Projecteur d'incorporation avec classification
Dans cette section, nous expliquerons comment construire un classificateur de critiques de films. Les critiques peuvent être catégorisées en deux groupes principaux : positif et négatif. Avec l'aide des étiquettes, TensorFlow a efficacement généré des incorporations qui montrent un regroupement distinct de mots spécifiques à chaque type de critique. En effectuant des recherches de mots, nous pouvons observer l'illumination de certains groupes et identifier les mots associés qui indiquent clairement une classification positive ou négative. Par exemple, lors de la recherche de "ennuyeux", nous pouvons observer sa proéminence dans un groupe aux côtés de mots comme "inregardable", qui appartiennent sans équivoque à la catégorie négative. De même, une recherche d'un terme négatif comme "agaçant" révélerait sa présence, ainsi que des mots connexes, dans le groupe spécifiquement associé aux critiques négatives. À l'inverse, une recherche de "amusant" nous conduirait à la découverte que "amusant" et "drôle" sont positifs, "fondamental" est neutre, tandis que "pas drôle" tombe sans équivoque dans la catégorie négative.
Jeu de données
Un aspect crucial de la vision de TensorFlow pour faciliter l'apprentissage et l'utilisation de l'apprentissage automatique et de l'apprentissage profond est l'inclusion de jeux de données intégrés. Il existe une bibliothèque appelée TensorFlow Data Services (TFDS), qui contient de nombreux jeux de données couvrant diverses catégories. Par exemple, il existe une large gamme de jeux de données basés sur l'image, ainsi qu'une sélection de jeux de données textuels. Dans nos tâches à venir, nous utiliserons l'ensemble de données de critiques IMDB, qui s'avère être un excellent choix.
Voici le lien vers l'ensemble de données : Large Movie Review Dataset
Chargeons l'ensemble de données :
import tensorflow_datasets as tfds
# Load the IMDB Reviews dataset
imdb, info = tfds.load("imdb_reviews", with_info=True, as_supervised=True)
L'ensemble de données est divisé en 25 000 échantillons pour l'entraînement et 25 000 échantillons pour les tests. Chacun de ces ensembles se compose d'itérables contenant les phrases et étiquettes respectives stockées sous forme de tenseurs. Pour utiliser les outils de tokenisation et de padding de Keras, une conversion est nécessaire. Tout d'abord, nous définissons des listes pour contenir les phrases et les étiquettes pour les données d'entraînement et de test. Nous pouvons ensuite parcourir les données d'entraînement pour extraire les phrases et les étiquettes. Puisque les valeurs sont des tenseurs, nous pouvons utiliser la méthode NumPy pour obtenir leurs valeurs réelles. Le même processus est effectué pour l'ensemble de test. Créons nos données :
train_data, test_data = imdb['train'], imdb['test']
# Initialize sentences and labels lists
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
# Loop over all training examples and save the sentences and labels
for s,l in train_data:
training_sentences.append(s.numpy().decode('utf8'))
training_labels.append(l.numpy())
# Loop over all test examples and save the sentences and labels
for s,l in test_data:
testing_sentences.append(s.numpy().decode('utf8'))
testing_labels.append(l.numpy())
# Convert labels lists to numpy array
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
Nous procédons à la tokenisation des phrases. Les hyperparamètres sont placés en haut pour une modification facile, ce qui est plus pratique que de chercher à travers des séquences de fonctions pour changer les valeurs littérales. Le tokeniseur et les séquences de padding sont importés comme auparavant. Une instance du tokeniseur est créée, en spécifiant la taille du vocabulaire et le jeton souhaité hors vocabulaire. Le tokeniseur est ensuite ajusté sur l'ensemble d'entraînement pour construire l'index des mots.
# Parameters
vocab_size = 10000
max_length = 120
embedding_dim = 16
trunc_type='post'
oov_tok = "<OOV>"
# Initialize the Tokenizer class
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
# Generate the word index dictionary for the training sentences
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
Une fois l'index des mots obtenu, les chaînes contenant des mots dans les phrases sont remplacées par leurs valeurs de jeton correspondantes, ce qui donne une liste appelée "séquences."
# Generate and pad the training sequences
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
# Generate and pad the test sequences
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length, truncating=trunc_type)
Comme les phrases ont des longueurs variables, les séquences sont rembourrées ou tronquées pour assurer une longueur uniforme, déterminée par le paramètre maxlength. Le même processus est appliqué aux séquences de test. Il est important de noter que l'index des mots est dérivé de l'ensemble d'entraînement, donc les données de test peuvent contenir plus de jetons hors vocabulaire.
Il est maintenant temps de définir le réseau neuronal, qui devrait être familier maintenant, sauf pour la ligne "embedding".
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Setup the training parameters
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# Print the model summary
model.summary()
La couche d'incorporation est un composant crucial pour l'analyse de sentiment de texte dans TensorFlow, où la transformation des mots en vecteurs denses dans un espace de dimension inférieure se produit, permettant la magie de l'analyse de sentiment.
Dans l'analyse de sentiment de texte, les mots ayant des significations similaires ont tendance à apparaître à proximité les uns des autres dans une phrase. Nous pouvons représenter les mots comme des vecteurs dans un espace de dimension supérieure, comme 16 dimensions, où les mots trouvés ensemble ont des vecteurs similaires et se regroupent. Ces vecteurs de mots sont appris par le réseau neuronal pendant l'entraînement et associés aux étiquettes de sentiment, ce qui donne lieu à des incorporations de mots.
Pour classer le sentiment d'une phrase, nous créons un tableau 2D d'incorporations de mots, avec la longueur de la phrase et la dimension d'incorporation (par exemple, 16). Nous pouvons aplatir ce tableau ou utiliser une mise en commun globale moyenne 1D pour le préparer à la classification. La mise en commun globale moyenne 1D calcule la moyenne sur le vecteur pour l'aplatir.
L'utilisation de la mise en commun globale moyenne 1D rend le résumé du modèle plus simple et potentiellement plus rapide. Avec cette approche, vous pouvez obtenir une précision d'entraînement de 0,9664 et une précision de test de 0,8187 sur 10 époques, chaque époque prenant environ 6,2 secondes. Alternativement, l'utilisation de flatten peut donner une précision d'entraînement de 1,0, une précision de validation d'environ 0,83, et chaque époque prend environ 6,5 secondes. Bien que légèrement plus lent, l'approche flatten a tendance à être plus précise.
Formons et visualisons notre incorporation :
#training
num_epochs = 10
# Train the model
model.fit(padded, training_labels_final, epochs=num_epochs, validation_data=(testing_padded, testing_labels_final))
#Visualize
# Get the embedding layer from the model (i.e. first layer)
embedding_layer = model.layers[0]
# Get the weights of the embedding layer
embedding_weights = embedding_layer.get_weights()[0]
# Print the shape. Expected is (vocab_size, embedding_dim)
print("embedding_weights.shape")
print(embedding_weights.shape)
Le résultat va devenir :
embedding_weights.shape
(10000, 16)
Commençons par extraire les résultats de la couche d'incorporations, qui correspond à la couche zéro dans notre modèle. Nous récupérons les poids de cette couche et imprimons leur forme, qui dans ce cas est un tableau de 10 000 par 16. Cela indique que notre corpus contient 10 000 mots, et nous travaillons avec un espace d'incorporation de 16 dimensions.
Pour tracer ces incorporations, nous devons inverser notre index de mots. Actuellement, l'index de mots a le mot comme clé et le jeton correspondant comme valeur. Pour décoder les jetons en mots, nous devons retourner l'index de mots :
# Get the index-word dictionary
reverse_word_index = tokenizer.index_word
Ensuite, nous écrivons les fichiers vecteurs et métadonnées auto. Ces types de fichiers sont reconnus par le Projecteur TensorFlow, qui nous permet de visualiser les incorporations dans un espace 3D. Dans le fichier vecteurs, nous écrivons les valeurs des coefficients de chaque dimension pour chaque incorporation de mots. Le fichier métadonnées contient les mots eux-mêmes.
Pour voir les résultats, visitez le site Web du Projecteur d'Incorporation TensorFlow à projector.tensorflow.org Cliquez sur le bouton "Charger les données" situé sur le côté gauche de l'écran. Dans la boîte de dialogue du fichier, sélectionnez le fichier vector.TSV pour les vecteurs et le fichier meta.TSV pour les métadonnées. Une fois les données chargées, vous verrez une visualisation similaire à celle décrite.
Pour activer le clustering binaire des données, cochez la case "sphériser les données" en haut à gauche. Cette option vous permet d'observer le clustering des mots. N'hésitez pas à expérimenter en recherchant des mots spécifiques ou en cliquant sur les points bleus représentant des mots dans le graphique. Le but est d'explorer et de s'amuser avec la visualisation.
Subwords
Heureusement, certains scientifiques de données ont déjà préparé l'ensemble de données IMDb pour nous. Dans cette vidéo, nous allons explorer une version pré-tokenisée de l'ensemble de données, où la tokenisation est effectuée sur des sous-mots. Cela est intéressant car cela met en évidence les défis uniques de la classification du texte, où la séquence de mots peut être tout aussi cruciale que leur présence individuelle.
SubwordTextEncoder
SubwordTextEncoder est un type de tokenizer utilisé dans les tâches de traitement du langage naturel, en particulier pour la classification du texte. Il relève le défi de tokeniser les mots d'une manière qui capture à la fois les mots individuels et les unités de sous-mots significatives.
Contrairement aux tokenizeurs traditionnels qui divisent le texte uniquement sur la base des espaces blancs ou de la ponctuation, SubwordTextEncoder décompose les mots en unités de sous-mots plus petites. Cela est particulièrement utile pour gérer les mots hors vocabulaire (OOV), les mots rares ou les mots ayant des variations morphologiques.
Ajouter neuronal
Nous avons maintenant un tokenizer de sous-mots pré-entraîné disponible. Pour examiner son vocabulaire, nous accédons simplement à sa propriété de sous-mots. Pour comprendre comment il encode ou décode des chaînes, nous pouvons utiliser les méthodes encoder et décoder, respectivement. Cela révèle le processus de tokenisation en imprimant les chaînes encodées et décodées.
# Encode the first plaintext sentence using the subword text encoder
tokenized_string = tokenizer_subwords.encode(training_sentences[0])
print(tokenized_string)
# Decode the sequence
original_string = tokenizer_subwords.decode(tokenized_string)
# Print the result
print (original_string)
Si nous voulons voir les jetons individuels, nous pouvons décoder chaque élément séparément, montrant l'association valeur-jeton. Gardez à l'esprit que ce tokenizer respecte la sensibilité à la casse et à la ponctuation, ce qui est un écart par rapport au tokenizer précédent que nous avons examiné.
Maintenant, tournons notre attention vers l'application de ce tokenizer pour la classification IMDB. La structure du modèle que nous utiliserons devrait vous sembler familière à présent. Cependant, il est important de considérer la forme des vecteurs émergeant du tokenizer à travers la couche d'incorporation, car ils ne peuvent pas être facilement aplatis. Par conséquent, nous utiliserons le Pooling Moyen Global 1D.
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer_subwords.vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Suivant les procédures standard, vous pouvez compiler et entraîner le modèle. La visualisation du résultat peut être réalisée avec le code fourni, et les graphiques générés devraient ressembler à un motif particulier.
import matplotlib.pyplot as plt
# Plot utility
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
# Plot the accuracy and results
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
Un aspect intéressant de la tokenisation en sous-mots est que les sous-mots individuels manquent souvent de sens logique. Ce n'est que lorsqu'ils sont mis en séquence qu'ils produisent des informations sémantiquement significatives. Par conséquent, une stratégie permettant d'apprendre à partir de séquences pourrait améliorer considérablement les performances de notre modèle.
Modèles de séquence
Dans le domaine de l'intelligence artificielle, les réseaux neuronaux servent de fonctions puissantes qui apprennent les règles à partir des données d'entrée et des étiquettes correspondantes. Cela nous permet d'exploiter ces règles apprises pour diverses tâches. Cependant, les réseaux neuronaux traditionnels ne tiennent pas compte de l'importance de l'information séquentielle. Pour saisir l'importance des séquences, explorons la séquence de Fibonacci - un ensemble ordonné de nombres. Nous pouvons remplacer les valeurs spécifiques par des variables comme n_0, n_1, n_2, etc., pour les désigner. Dans cette séquence, chaque nombre est la somme des deux nombres précédents. Par exemple, 3 égale 2 plus 1, 5 égale 2 plus 3, 8 égale 3 plus 5, etc.
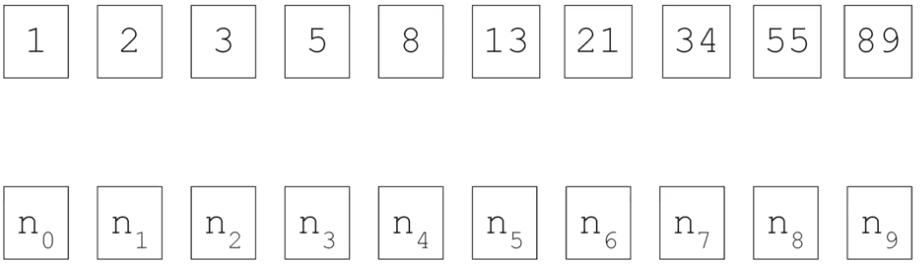
Pour représenter ce processus visuellement, nous pouvons imaginer que les nombres un et deux sont entrés dans une fonction, donnant le nombre trois. Le deuxième nombre, deux, est reporté à l'étape suivante, où il se combine avec trois pour donner cinq. Ce schéma se poursuit, chaque sortie devenant une partie de l'entrée de l'étape suivante. Ce concept partage des similitudes avec les réseaux neuronaux récurrents (RNN).
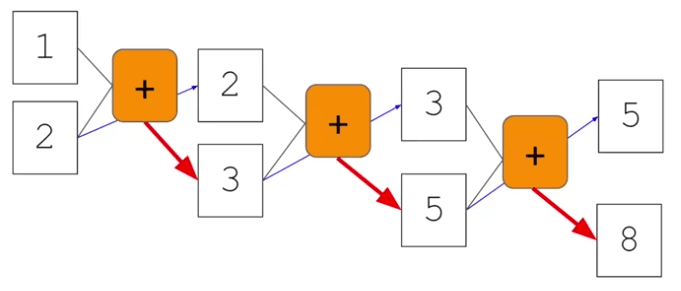
Un RNN, représenté par x en entrée et y en sortie, incorpore une boucle de rétroaction où la sortie d'une étape précédente devient une entrée pour l'étape suivante. Cela devient plus clair lorsque nous connectons plusieurs RNNs dans une structure en chaîne. Par exemple, x_0 est entré dans la fonction, produisant la sortie y_0. Cette sortie sert ensuite d'entrée, avec x_2, pour la fonction suivante, produisant la sortie y_2.
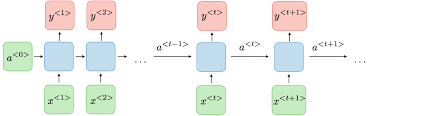
Ce processus se poursuit, permettant au réseau de conserver et de traiter les informations des étapes précédentes. En conséquence, cela forme la base des réseaux neuronaux récurrents (RNNs).
LSTMs (Long Short-Term Memory)
Une limitation inhérente se présente lorsque l'on utilise des approches conventionnelles pour la classification de texte. Considérez le scénario suivant : "Le soleil brille et le ciel est d'une nuance envoûtante d'azur." Quel mot viendrait probablement ensuite ? Très probablement, "bleu." La description du ciel comme "une nuance envoûtante d'azur" fournit un indice crucial dans ce contexte.
Cependant, examinons une autre phrase : "Pendant mes voyages au Japon, je me suis immergé dans leur riche culture et j'ai appris à manger quelque chose." Comment compléteriez-vous cette phrase ? Alors que certains pourraient suggérer "sushi," une réponse plus précise serait "ramen." La mention du Japon et la référence à l'immersion dans leur riche culture fournissent le contexte nécessaire pour comprendre la cuisine préférée.
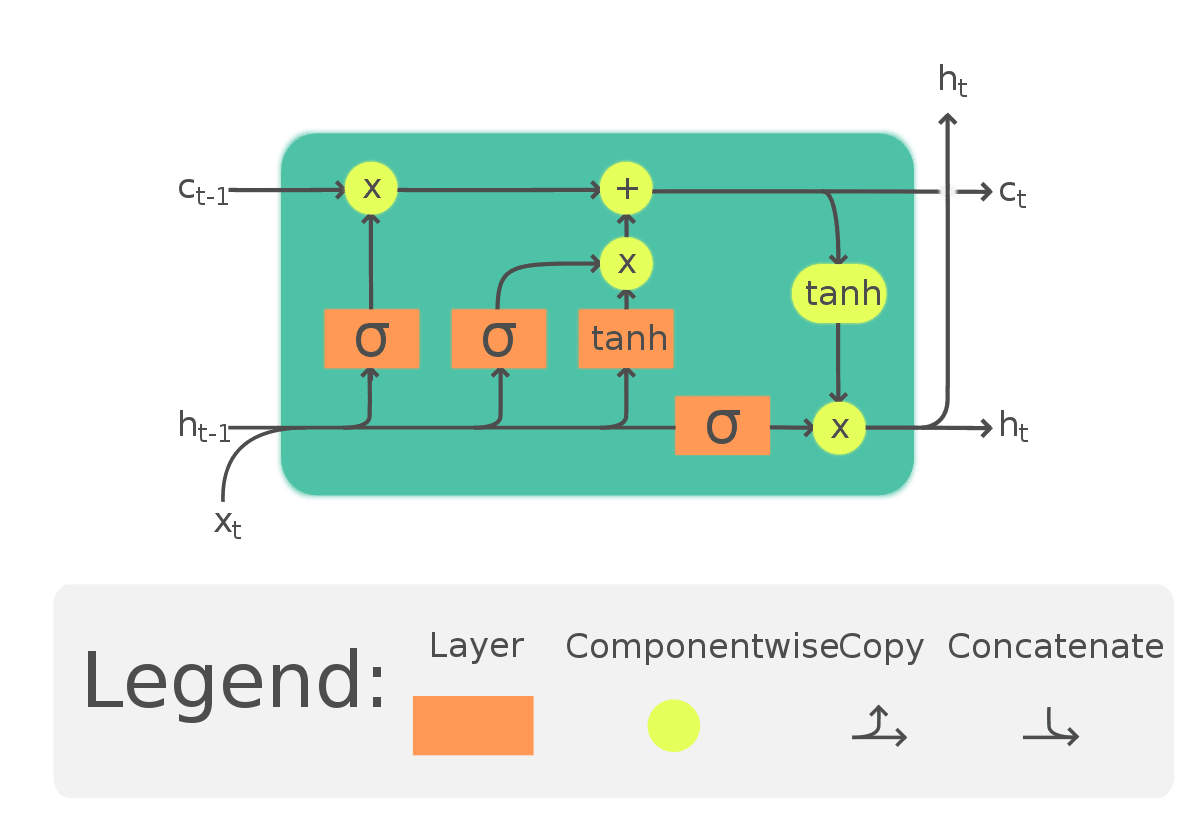
Pour répondre à ces défis, une mise à jour des réseaux neuronaux récurrents (RNN) a été développée, connue sous le nom de mémoire à long terme à court terme (LSTM). Les LSTMs vont au-delà du simple passage du contexte, comme dans les RNN, en introduisant un chemin supplémentaire appelé "état cellulaire." Ce chemin permet au réseau de retenir et d'utiliser le contexte des jetons précédents, atténuant les problèmes où le contexte pertinent apparaît plus loin dans la phrase. De plus, les états cellulaires peuvent être bidirectionnels, permettant aux contextes ultérieurs d'influencer les précédents. Nous explorerons les implémentations de code pour mieux comprendre l'impact bidirectionnel sur le contexte.
Implémentation LSTM
Maintenant, plongeons dans l'implémentation des LSTMs dans le code. Ci-dessous se trouve un exemple d'un modèle où j'ai ajouté une deuxième couche en tant que LSTM en utilisant tf.keras.layers.LSTM. Le paramètre passé à la couche LSTM représente le nombre souhaité de sorties, qui dans ce cas est de 64. En l'enveloppant avec tf.keras.layers.Bidirectional, nous permettons à l'état cellulaire de se propager dans les deux directions, avant et arrière. Vous observerez ce comportement bidirectionnel en explorant le résumé du modèle, représenté comme suit :
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_seq_length))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
model.summary()
Le résumé du modèle présente une couche d'incorporation suivie d'un LSTM bidirectionnel, puis de deux couches denses. Notamment, la sortie du LSTM bidirectionnel est maintenant de 128, même si nous avons initialement spécifié 64 sorties pour la couche LSTM. Ce doublement se produit en raison de la nature bidirectionnelle, qui combine les sorties des directions avant et arrière.
Il est également possible d'empiler des LSTM similaires aux autres couches Keras. Pour y parvenir, vous devez inclure le paramètre return_sequences=True dans la première couche LSTM. Cela garantit que les sorties du LSTM correspondent aux entrées attendues de la couche suivante. Voici un exemple :
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_seq_length))
model.add(tf.keras.layers.LSTM(64, return_sequences=True))
model.add(tf.keras.layers.LSTM(32))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
model.summary()
En incorporant le paramètre return_sequences=True dans la première couche LSTM, vous conservez les informations de séquence et fournissez des entrées appropriées pour la couche suivante dans la pile.
LSTM simple vs multiple LSTM
Maintenant, comparons les précisions entre un LSTM à une couche et un LSTM à deux couches sur 10 époques.
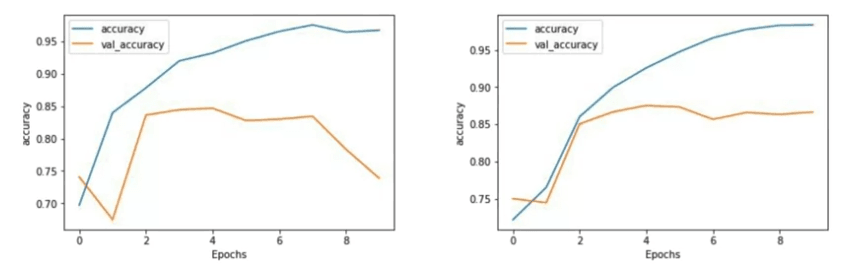
Bien qu'il n'y ait pas de différence significative dans la précision, nous pouvons observer une distinction notable dans la courbe de précision de validation. Remarquez que la courbe d'entraînement pour le LSTM à deux couches semble plus lisse. Dans mon expérience d'entraînement des réseaux, la rugosité de la courbe peut indiquer que des améliorations du modèle sont nécessaires, et le LSTM à une couche dans ce cas présente une certaine rugosité.
Si nous étendons l'entraînement à 50 époques, nous pouvons analyser davantage les résultats.
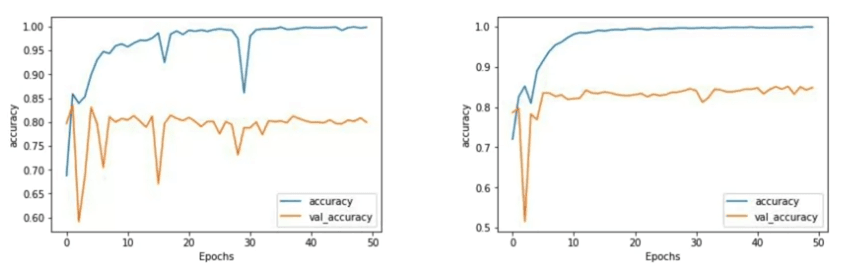
Le LSTM à une couche montre une tendance à l'augmentation de la précision mais est susceptible de chutes brusques en cours de route. Alors que la précision finale pourrait être bonne, ces chutes suscitent des préoccupations quant à la précision globale du modèle. D'autre part, le LSTM à deux couches présente une courbe de précision beaucoup plus lisse, inspirant une plus grande confiance dans ses résultats.
Il convient de noter la précision de validation, qui se stabilise à environ 80 pour cent. Étant donné que les ensembles d'entraînement et de test se composent de 25 000 avis, et que nous n'utilisons que 8 000 sous-mots de l'ensemble d'entraînement, il y aura de nombreux jetons dans l'ensemble de test qui seront hors vocabulaire. Pourtant, même avec ce défi, nous atteignons une précision d'environ 80 pour cent.
Les résultats de perte montrent une tendance similaire, avec le LSTM à deux couches présentant une courbe plus lisse. La perte augmente progressivement à chaque époque, indiquant la nécessité d'une surveillance attentive pour s'assurer qu'elle s'aplatit dans les époques ultérieures, comme souhaité.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Lorsque j'ai remplacé la couche de pooling par un LSTM, les résultats ont considérablement changé. Le modèle a non seulement atteint rapidement le benchmark précédent de 85% de précision, mais il a également continué à s'améliorer, atteignant finalement environ 97,5% de précision en seulement 50 époques. Bien que la précision de l'ensemble de validation ait quelque peu diminué au fil du temps, elle est restée comparable au modèle initial sans le LSTM. Une observation intéressante ici était un léger surajustement, une préoccupation courante avec le LSTM qui pourrait être résolue avec un peu de réglage fin.
De plus, les valeurs de perte des modèles ont affiché des motifs différents. Le modèle non-LSTM a atteint rapidement un état sain puis est resté relativement stable. Cependant, avec le modèle LSTM, la perte d'entraînement a constamment diminué, mais la perte de validation a augmenté au fil du temps. Cela pourrait être une autre indication de surajustement dans le réseau LSTM. Il est à noter que si la précision de la prédiction s'est améliorée, la confiance en elle a légèrement diminué.
Lorsque vous expérimentez avec différents types de réseaux, il est crucial d'ajuster vos paramètres d'entraînement en conséquence. Ce ne sont pas de simples remplacements; chaque changement peut affecter considérablement les performances et les caractéristiques de votre modèle.
Réseau convolutif
Un autre type de couche qui peut être utilisé est la couche convolutive, similaire à la façon dont elle est appliquée dans le traitement de l'image.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_seq_length))
model.add(tf.keras.layers.Conv1D(filters=128, kernel_size=5, activation='relu'))
model.add(tf.keras.layers.GlobalMaxPooling1D())
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(num_classes, activation='softma
The code snippet provided demonstrates the usage of a convolutional layer in a network, which closely resembles the previous architecture. By specifying the desired number of convolutions, their size, and activation function, words are grouped based on the filter size (e.g., 5 in this case). Convolutions are learned to map word classifications to the desired output.
Training the network with convolutions yields even better accuracy than before, achieving close to 100 percent on the training set and around 80 percent on the validation set. However, as observed previously, the validation loss increases, indicating potential overfitting. Given the simplicity of the current network, this outcome is not surprising, and further experimentation with different combinations of convolutional layers is necessary to address this issue.
By revisiting the model and exploring the parameters, it becomes evident that we have 128 filters, each considering 5 words. Inspecting the model dimensions reveals that the input size was 120 words, and a 5-word filter shaves off 2 words from both ends, resulting in 116 remaining words. The specified 128 filters are visualized within the convolutional layer component of the model.





