 Français
FrançaisIntroduction
Dans nos articles précédents, nous nous sommes concentrés sur le développement de réseaux neuronaux convolutionnels (CNN) excellant dans la reconnaissance d'images dans des classes binaires, telles que la distinction entre chevaux et humains ou chats et chiens. Malgré leur remarquable efficacité, nous devons rester prudents de ne pas tomber dans le piège de la surconfiance induite par le surapprentissage. Ce risque devient particulièrement proéminent lors de la formation de CNN avec des ensembles de données limités. Dans cet article, nous allons explorer le concept de surapprentissage, fournir un exemple utilisant TensorFlow, et explorer des techniques efficaces pour relever ce défi, en commençant par la puissance de l'augmentation des données.
Comprendre le surapprentissage :
Le surapprentissage fait référence à une situation où un modèle devient exceptionnellement doué pour reconnaître des motifs spécifiques à partir d'un ensemble de données restreint, mais éprouve des difficultés face à des instances inconnues. Pour illustrer ce concept, considérons un scénario impliquant des chaussures. Supposons que les seules chaussures que vous ayez jamais rencontrées dans votre vie sont des bottes de randonnée. Avec cette exposition limitée, vous avez développé une compréhension claire de ce à quoi ressemblent les chaussures basées sur cet exemple singulier. Par conséquent, si quelqu'un devait vous montrer des bottes de randonnée de différentes tailles, vous les identifieriez facilement comme des chaussures. Cependant, si l'on vous présentait une chaussure à talon haut, malgré le fait qu'il s'agisse d'une chaussure, vous pourriez ne pas la reconnaître comme telle. Dans ce cas, votre compréhension de ce qui constitue une chaussure est devenue trop adaptée aux caractéristiques spécifiques des bottes de randonnée, vous rendant inflexible aux variations. Le surapprentissage est un défi courant dans la formation de classificateurs, surtout lorsqu'on travaille avec des données limitées.
Augmentation : Maximiser l'efficacité de l'ensemble de données : Pour atténuer les risques associés au surapprentissage, nous pouvons utiliser divers outils et techniques pour rendre nos ensembles de données plus petits plus efficaces. Une telle approche est l'augmentation des données. Lorsque nous travaillons avec des CNN, nous appliquons généralement des convolutions aux images pour identifier des caractéristiques spécifiques, comme les oreilles pointues pour les chats ou le nombre de jambes pour les humains. Les convolutions excellent dans l'identification de caractéristiques distinctes clairement visibles dans l'image. Cependant, et si nous pouvions aller au-delà ? Et si nous pouvions manipuler l'image du chat pour ressembler à d'autres images de chats avec des oreilles orientées différemment ? En entraînant le réseau avec des images augmentées, nous pouvons augmenter son adaptabilité et améliorer sa capacité à reconnaître des variations d'une caractéristique particulière.
Exemple avec TensorFlow :
Prenons un exemple pratique en utilisant TensorFlow pour mettre en évidence la puissance de l'augmentation des données. Supposons que nous ayons un ensemble de données d'images de chats, mais aucune d'elles ne dépeint un chat incliné. Sans augmentation des données, notre CNN pourrait avoir du mal à identifier un chat incliné puisqu'il n'a jamais été exposé à de tels exemples lors de la formation. Cependant, en introduisant des techniques d'augmentation comme la rotation de l'image, nous pouvons transformer les images de chats debout dans notre ensemble de données, les faisant ressembler à des chats inclinés. Cette augmentation renforce la capacité du réseau à détecter des chats inclinés, même si aucune image explicite de chat incliné n'était disponible pour la formation. En élargissant l'ensemble de données artificiellement par l'augmentation, nous introduisons des exemples plus divers, réduisant le risque de surapprentissage et améliorant les capacités de généralisation du réseau.
Augmentation de l'image
L'augmentation de l'image joue un rôle crucial dans l'amélioration des performances des réseaux neuronaux convolutionnels (CNN) en introduisant des variations et en augmentant l'adaptabilité du modèle à différentes caractéristiques. Dans nos discussions précédentes, nous avons exploré la classe image generator, qui incorporait déjà un certain niveau d'augmentation par le redimensionnement. Cependant, d'autres options sont disponibles pour augmenter davantage l'ensemble de données. Examinons certaines de ces options et leur impact potentiel sur le processus d'entraînement.
-
Plage de Rotation : Le paramètre
rotation rangenous permet de faire pivoter aléatoirement les images dans une plage spécifiée (0-180 degrés). En introduisant des rotations aléatoires, nous pouvons exposer le réseau à des images sous différents angles. Par exemple, spécifier une plage de rotation de 0 à 40 degrés signifie que les images tourneront d'une quantité aléatoire entre 0 et 40 degrés. -
Décalage : Le décalage consiste à déplacer l'image dans son cadre. De nombreuses images ont le sujet centré, ce qui peut conduire au surapprentissage si le modèle est formé uniquement sur de telles images. Pour y remédier, nous pouvons décaler aléatoirement le sujet dans l'image d'une proportion spécifiée de la taille de l'image. Par exemple, décaler le sujet de 20 pour cent verticalement ou horizontalement introduit de la variabilité et réduit le risque de surapprentissage aux sujets centrés.
-
Cisaillement: Le cisaillement est une technique puissante d'augmentation qui peut aider le modèle à se généraliser à différentes orientations. Considérez une image d'une personne dans une pose particulière absente de l'ensemble d'apprentissage. Cependant, si nous avons une image similaire avec une pose comparable, nous pouvons ciseler cette dernière image en la faussant le long de l'axe des x pour obtenir une pose similaire. Le paramètre
shear_rangenous permet de ciseler l'image par des montants aléatoires, jusqu'à une proportion spécifiée de la taille de l'image. Par exemple, une plage de cisaillement de 20 pour cent signifie que l'image peut être ciselée jusqu'à 20 pour cent. -
Zoom: Zoomer ou dézoomer sur une image peut être une technique d'augmentation efficace pour améliorer la capacité du modèle à reconnaître des exemples généralisés. En zoomant, nous pouvons repérer des détails qui pourraient être manqués à une échelle plus large. Le paramètre
zoomspécifie la partie relative de l'image sur laquelle zoomer. Par exemple, utiliser une valeur de 0,2 signifie que les images seront aléatoirement zoomées jusqu'à 20 pour cent de leur taille originale. -
Basculement Horizontal: Le basculement horizontal est un outil utile pour augmenter la similitude structurelle entre les images. Il peut aider le modèle à se généraliser à différentes orientations ou poses. Par exemple, si nos données d'entraînement manquent d'images de femmes avec la main gauche levée mais incluent des images avec le bras droit levé, retourner horizontalement ces dernières images les rend plus structurellement similaires aux premières. En permettant le basculement horizontal aléatoire, les images seront retournées au hasard pendant l'entraînement.
-
Mode de Remplissage: Le paramètre
fill modedétermine comment remplir les pixels qui pourraient être perdus lors des opérations d'augmentation. Utiliser le mode de remplissage "nearest", qui utilise les pixels voisins, aide à maintenir l'uniformité de l'image. Cependant, il existe d'autres options disponibles, et il est conseillé de se référer à la documentation du caret pour plus de détails.
par exemple:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Define the augmentation options
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# Load and augment the images
train_generator = datagen.flow_from_directory(
'path_to_training_data_directory',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
# Create and train the model using augmented data
model = create_model() # Replace with your own model creation function
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(train_generator, epochs=10)
L'Impact de l'Augmentation d'Image:
Pour observer l'impact de l'augmentation d'image, examinons un scénario impliquant la formation d'un modèle pour classer les chats contre les chiens. Nous comparerons les performances des modèles formés avec et sans augmentation. En évaluant les deux cas, nous pouvons évaluer l'efficacité de l'augmentation pour améliorer la capacité du modèle à généraliser et à éviter le surapprentissage.
Apprentissage par transfert
Dans les sections et articles précédents, nous avons discuté des défis du surapprentissage et exploré des techniques telles que l'augmentation d'image pour en atténuer les effets. Cependant, ces approches ont des limites, en particulier lorsqu'on travaille avec de petits ensembles de données d'entraînement. Dans de tels cas, l'apprentissage par transfert offre une solution puissante en tirant parti des modèles préexistants formés sur des ensembles de données plus grands et plus diversifiés. Examinons le concept de l'apprentissage par transfert et ses avantages.
Concept
L'apprentissage par transfert implique de prendre un modèle existant qui a été formé sur une grande quantité de données et d'utiliser les caractéristiques qu'il a apprises pour une tâche ou un ensemble de données différent. Au lieu de construire un modèle à partir de zéro, nous pouvons utiliser les couches convolutionnelles d'un modèle pré-entraîné qui a déjà appris des caractéristiques riches et utiles. Ce faisant, nous pouvons économiser du temps et des ressources tout en bénéficiant des connaissances codées dans le modèle pré-entraîné.
En visualisant un modèle typique, nous voyons une série de couches convolutionnelles suivies d'une couche dense menant à la couche de sortie. Lors de l'utilisation de l'apprentissage par transfert, nous pouvons incorporer le modèle pré-entraîné de quelqu'un d'autre, qui peut être plus sophistiqué et formé sur un ensemble de données beaucoup plus grand. Ces modèles viennent avec des couches convolutionnelles intactes qui ont déjà appris des caractéristiques puissantes. Plutôt que de ré-entraîner ces couches sur notre propre ensemble de données, nous pouvons les verrouiller et les utiliser pour extraire des caractéristiques de nos propres données. De cette façon, nous pouvons tirer parti des couches convolutionnelles d'un modèle formé sur un grand ensemble de données pour identifier les caractéristiques importantes de nos propres données.
Le processus consiste à utiliser les convolutions apprises du modèle pré-entraîné pour extraire des caractéristiques de nos données, puis à ré-entraîner les couches denses du modèle en utilisant notre ensemble de données. En suivant cette approche, nous pouvons bénéficier des connaissances et des capacités d'extraction de caractéristiques d'un modèle formé sur une grande quantité de données, tout en adaptant les couches finales à notre tâche spécifique.
Généralement, les couches convolutionnelles sont verrouillées pour préserver les caractéristiques apprises. Cependant, il y a de la flexibilité dans la décision des couches à ré-entraîner. Bien que les couches convolutionnelles de haut niveau soient souvent laissées verrouillées, certaines couches de bas niveau peuvent être ré-entraînées si elles sont trop spécialisées pour les images spécifiques de notre ensemble de données. L'expérimentation et l'essai et l'erreur peuvent aider à déterminer la combinaison optimale de couches verrouillées et ré-entraînées.
Un exemple d'un modèle bien entraîné de pointe est Inception, qui a été pré-entraîné sur l'ensemble de données ImageNet à grande échelle. ImageNet se compose de 1,4 million d'images à travers 1 000 classes différentes, ce qui en fait une source précieuse de connaissances préexistantes pour diverses tâches de vision par ordinateur.
En tirant parti de l'apprentissage par transfert et en utilisant des modèles pré-entraînés comme Inception, nous pouvons tirer parti des caractéristiques apprises des couches convolutionnelles et les adapter pour résoudre notre problème de classification spécifique avec un ensemble de données plus petit.
Caractéristiques Transférées
Toutes les couches ont des noms, vous pouvez donc rechercher le nom de la dernière couche que vous souhaitez utiliser. Si vous inspectez le résumé, vous verrez que les couches inférieures ont convolué à 3 par 3. Mais je veux utiliser quelque chose avec un peu plus d'informations. Alors j'ai remonté la description du modèle pour trouver mixed7, qui est la sortie de beaucoup de convolution qui sont 7 par 7. Vous n'avez pas à utiliser cette couche et il est amusant d'expérimenter avec d'autres. Mais avec ce code, je vais saisir cette couche d'Inception et la prendre en sortie.
# Define new model
last_output = inception.get_layer('mixed7').output
x = Flatten()(last_output)
x = Dense(hidden_units, activation='relu')(x)
output = Dense(1, activation='sigmoid')(x)
model = Model(inception.input, output)
Alors maintenant, nous allons définir notre nouveau modèle, en prenant la sortie de la couche mixed7 du modèle Inception, que nous avons appelée last_output. Cela devrait ressembler exactement aux modèles denses que vous avez créés au tout début de ce cours. Le code est un peu différent, mais c'est juste une façon différente d'utiliser l'API de couches. Vous commencez par aplatir l'entrée, qui se trouve être la sortie d'Inception. Puis ajoutez une couche cachée dense. Et ensuite votre couche de sortie qui n'a qu'un seul neurone activé par un sigmoïde pour classer entre deux éléments. Vous pouvez ensuite créer un modèle en utilisant la classe abstraite Model et en passant l'entrée et la définition des couches que vous venez de créer.
Et ensuite, vous le compilez comme avant avec un optimiseur, une fonction de perte et les mesures que vous souhaitez collecter.
Je ne vais pas entrer dans tous les codes pour télécharger à nouveau les chats contre les chiens, c'est dans le cahier si vous voulez l'utiliser. Mais comme avant, vous allez augmenter les images avec le générateur d'images. Puis, comme avant, nous pouvons obtenir nos données d'entraînement à partir du générateur en s'écoulant du répertoire spécifié et en passant par toutes les augmentations. Et maintenant, nous pouvons nous entraîner comme avant avec model.fit_generator. Je vais le faire fonctionner pendant 100 époques.
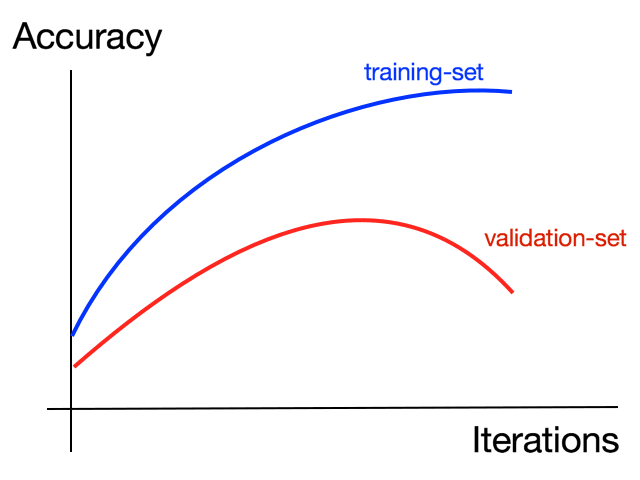
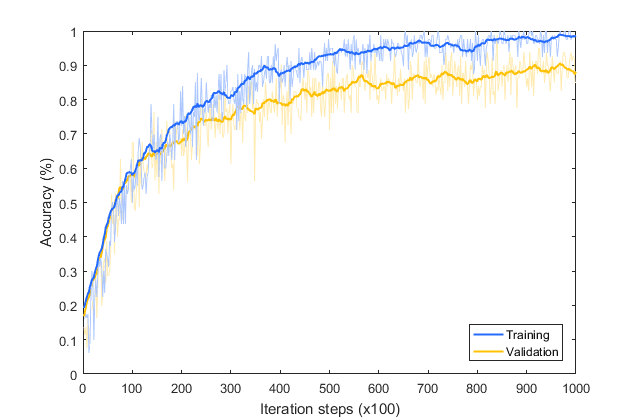
Ce qui est intéressant si vous faites cela, c'est que vous vous retrouvez avec une autre mais une situation de surapprentissage différente. Voici le graphique de l'exactitude de l'entraînement par rapport à la validation. Comme vous pouvez le voir, bien qu'il ait bien commencé, la validation s'écarte de l'entraînement d'une manière vraiment mauvaise. Alors, comment corriger cela ? Nous allons examiner cela dans la prochaine leçon.
Abandons
Lorsque nous ré-entraînons les caractéristiques du classificateur Inception pour les chats contre les chiens, nous finissons à nouveau par sur-apprendre. Nous avons également eu une augmentation, mais malgré cela, nous avons encore souffert de surapprentissage. Alors discutons de quelques moyens de l'éviter dans cette leçon. Maintenant, voici la précision de notre ensemble d'entraînement par rapport à notre ensemble de validation sur 100 époques. Ce n'est pas très sain.
Il y a une autre couche dans Keras appelée un abandon. Et l'idée derrière l'abandon est que les couches dans un réseau neuronal peuvent parfois finir par avoir des poids similaires et éventuellement se nuire mutuellement, conduisant à un surapprentissage. Avec un grand modèle complexe comme celui-ci, c'est un risque. Alors si vous pouvez imaginer que les couches denses peuvent ressembler un peu à ceci.
![]()
En en éliminant quelques-unes, nous le faisons ressembler à ceci.
Et cela a pour effet que les voisins ne s'affectent pas trop mutuellement et éliminent potentiellement le surapprentissage.
Alors comment y parvenir en code ? Eh bien, voici notre définition de modèle d'avant. Et voici où nous ajoutons l'abandon. Le paramètre est entre 0 et 1 et c'est la fraction des unités à abandonner.
Multiclasse
Dans les dernières sections, nous avons construit un classificateur binaire. Celui qui détecte deux types d'objets différents, cheval ou humain, chat ou chien, ce genre de choses. Dans cette section, nous allons examiner comment nous pouvons l'étendre à plusieurs classes.
Souvenez-vous que lorsque nous classifions les chevaux ou les humains, nous avions une structure de fichiers comme celle-ci:
dataset
train
- chevaux
- humains
validation
- chevaux
- humains
Il y avait des sous-répertoires pour chaque classe, où dans ce cas nous n'en avions que deux.
La première chose que vous devrez faire est de reproduire ceci pour plusieurs classes comme ceci:
dataset
train
- roche
- papier
- ciseaux
validation
- roche
- papier
- ciseaux
Dans ces répertoires, nous pouvons mettre des images d'entraînement et de validation pour la roche, le papier et les ciseaux.
Comment faire
Une fois votre répertoire configuré, vous devez configurer votre générateur d'images. Voici le code que vous avez utilisé précédemment, mais notez que le mode de classe était défini sur "binaire". Pour plusieurs classes, vous devrez le changer en "catégorique" comme ceci:
train_datagen = ImageDataGenerator(...)
train_generator = train_datagen.flow_from_directory(..., class_mode='categorical')
Le prochain changement intervient dans la définition de votre modèle, où vous devrez modifier la couche de sortie. Pour un classificateur binaire, il était plus efficace d'avoir un neurone et d'utiliser une fonction sigmoid pour l'activer. Maintenant, cela ne convient pas pour un multi-classes, donc nous devons le changer. Maintenant, nous avons une couche de sortie qui a trois neurones, un pour chacune des classes (roche, papier et ciseaux), et elle est activée par softmax, qui transforme toutes les valeurs en probabilités qui s'additionneront à un. Ainsi, la sortie d'un réseau de neurones avec trois neurones et une activation softmax refléterait les probabilités de chaque classe.
model.add(Dense(3, activation='softmax'))
Le dernier changement intervient lorsque vous compilez votre réseau. Auparavant, votre fonction de perte était l'entropie croisée binaire. Maintenant, vous la changerez en entropie croisée catégorique comme ceci :
model.compile(loss='entropie_croisée_catégorique', ...)
Il existe d'autres fonctions de perte catégoriques, y compris l'entropie croisée catégorique creuse, que vous avez utilisée dans l'exemple de mode, et vous pouvez également les utiliser.
Entraînez le modèle pendant 100 époques, et vous pouvez observer la progression de l'entraînement avec un graphique. Dans cet exemple, l'entraînement atteint un maximum à environ 25 époques. Je recommande donc d'utiliser un nombre plus petit d'époques pour plus d'efficacité.





