 Français
FrançaisIntroduction
Le plus populaire et largement utilisé algorithme d'apprentissage aujourd'hui est appelé la classification binaire, qui est utilisée pour prédire l'une des deux résultats possibles, tels que si un e-mail est un spam ou non, si une transaction financière est frauduleuse ou non, ou si une tumeur est maligne ou bénigne. Ce type de problème de classification est appelé classification binaire parce qu'il n'y a que deux classes ou catégories possibles.
Les deux classes ou catégories sont souvent désignées par non ou oui, faux ou vrai, ou zéro ou un. La classe négative est souvent appelée la classe fausse ou zéro, et la classe positive est souvent appelée la classe vraie ou un.
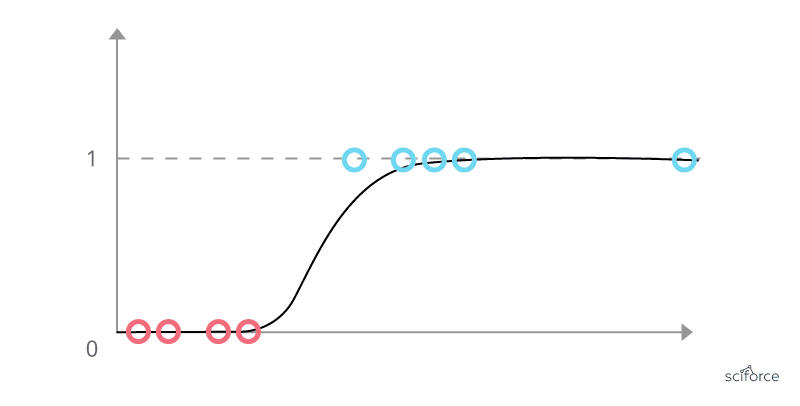
Pour construire un algorithme de classification, une approche consiste à utiliser la régression linéaire pour ajuster une ligne droite aux données, mais cette méthode prédit tous les nombres entre zéro et un, plutôt que seulement les catégories de zéro et un. Donc, un graphique ressemblera à ceci:
Régression logistique
Introduction:
La régression logistique est un algorithme de classification couramment utilisé qui est utilisé pour prédire des résultats binaires. Dans cet exemple, nous l'utiliserons pour classifier si une tumeur est maligne ou bénigne.
Problème:
Nous avons un ensemble de données où l'axe horizontal est la taille de la tumeur et l'axe vertical ne prend que des valeurs de 0 et 1, car il s'agit d'un problème de classification. La régression linéaire n'est pas un bon algorithme pour ce problème.
Solution:
La régression logistique est utilisée pour ajuster une courbe en forme de S à l'ensemble de données. Par exemple, si un patient arrive avec une tumeur d'une certaine taille, l'algorithme produira une valeur comprise entre 0 et 1, suggérant la probabilité que la tumeur soit maligne ou bénigne.
Fonction Sigmoïde:
Pour construire l'algorithme de régression logistique, nous utilisons une fonction mathématique importante appelée fonction sigmoïde, également appelée fonction logistique. La fonction sigmoïde produit une valeur entre 0 et 1, basée sur la variable d'entrée Z. La formule de g(z) est égale à 1 sur 1 plus e à la puissance moins z, où e est une constante mathématique qui prend une valeur d'environ 2,7.
Nous pouvons représenter le graphique comme ceci:
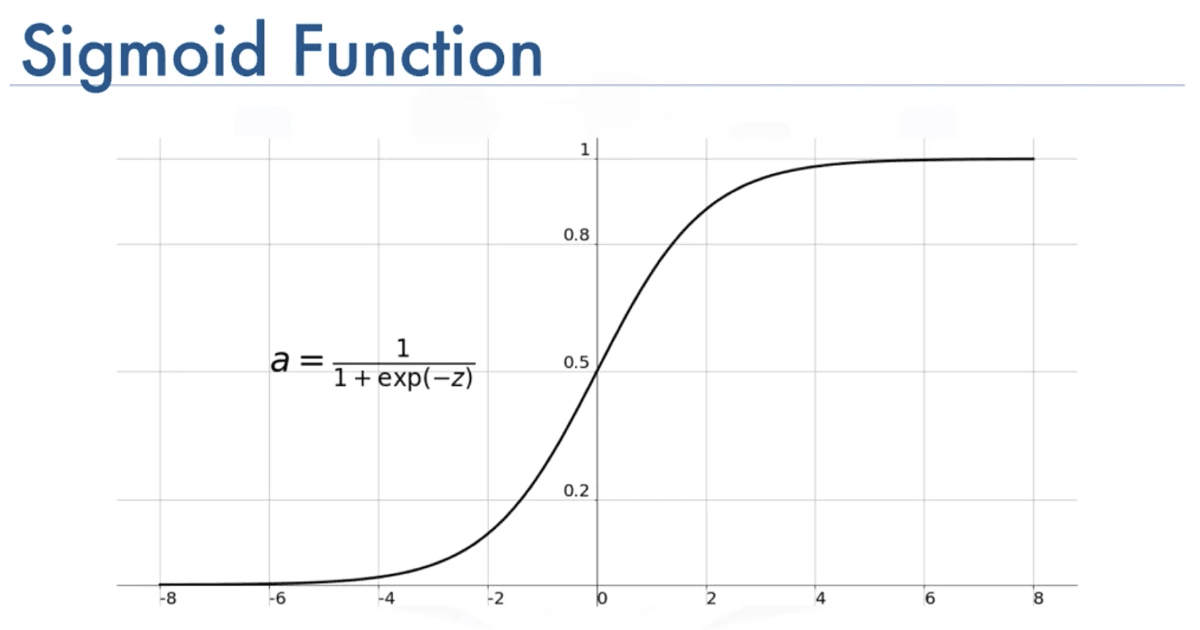
Notez que nous avons des valeurs positives et négatives pour les valeurs horizontales (Z).
Construction du modèle de régression logistique :
Dans la première étape, nous définissons une fonction de ligne droite, comme une fonction de régression linéaire, qui est représentée par la variable Z. La prochaine étape consiste à prendre cette valeur de Z et à la passer à travers la fonction Sigmoïde, qui est représentée par la variable g(z). Cette fonction produit une valeur entre 0 et 1. Lorsque z est grand, g(z) est proche de 1 et lorsque z est un grand nombre négatif, g(z) est proche de 0. Lorsque z est égal à 0, g(z) est égal à 0,5. Cette fonction sigmoïde est utilisée pour construire le modèle de régression logistique, qui prend en entrée une caractéristique ou un ensemble de caractéristiques et produit un nombre entre 0 et 1.
Sortie:
Le modèle de régression logistique prend un ensemble de caractéristiques (c'est-à-dire des données d'entrée) et produit une valeur entre 0 et 1, qui peut ensuite être utilisée pour classer l'entrée dans l'une des deux classes possibles. La prochaine étape consiste à interpréter la sortie du modèle de régression logistique et à prendre une décision en fonction du résultat.
Nous pouvons définir la formule comme suit : 𝑓𝑤->,𝑏(𝑥->)=𝑤->*𝑥->+𝑏 où 𝑧 = 𝑤->*𝑥->+𝑏
Nous savons que la formule de la fonction sigmoïde est : 𝑔(𝑧)=1/(1+𝑒−𝑧) Nous pouvons donc dire : *𝑓𝑤->,𝑏(𝑥->) = 1/(1+𝑒−(𝑤->𝑥->+𝑏))
Exemple :
- X est la "taille de la tumeur"
- Y est 0 (non maligne) ou 1 (maligne)
𝑓𝑤->,𝑏(𝑥->) = 0,7 signifie que nous avons 70 % de chances que la tumeur soit maligne
Implémentation
Importons nos dépendances :
# Créer un tableau d'entrée et utiliser la fonction exp pour calculer l'exponentielle de chaque élément
input_array = np.array([1, 2, 3])
exp_array = np.exp(input_array)
# Imprimer l'entrée et la sortie de la fonction exp
print("Entrée pour exp :", input_array)
print("Sortie de exp :", exp_array)
Nous pouvons ajouter nos valeurs et utiliser la fonction exponentielle pour les calculer :
# Créer un tableau d'entrée et utiliser la fonction exp pour calculer l'exponentielle de chaque élément
input_array = np.array([1, 2, 3])
exp_array = np.exp(input_array)
# Imprimer l'entrée et la sortie de la fonction exp
print("Entrée pour exp :", input_array)
print("Sortie de exp :", exp_array)
Résultat
Entrée pour exp : [1 2 3]
Sortie de exp : [ 2.72 7.39 20.09]
Entrée pour exp : 1
Sortie de exp : 2.718281828459045
Nous pouvons appliquer notre formule de sigmoïde : 1/(1+np.exp(-z))
# Define the sigmoid function
def sigmoid(z):
"""
Compute the sigmoid of z
Args:
z (ndarray): A scalar, numpy array of any size.
Returns:
g (ndarray): sigmoid(z), with the same shape as z
"""
g = 1/(1+np.exp(-z))
return g
Nous pouvons calculer notre fonction et l'afficher dans un graphique :
# Create an array of values for z
z_tmp = np.arange(-10,11)
# Calculate sigmoid(z) for each value in the z_tmp array
y = sigmoid(z_tmp)
# Print the input and output of the sigmoid function
np.set_printoptions(precision=3)
print("Input (z), Output (sigmoid(z))")
print(np.c_[z_tmp, y])
# Plot z vs sigmoid(z)
fig,ax = plt.subplots(1,1,figsize=(5,3))
plots(1,1,figsize=(5,3))
ax.plot(z_tmp, y, c="b")
#Add title, labels and vertical threshold line to the plot
ax.set_title("Sigmoid function")
ax.set_ylabel('sigmoid(z)')
ax.set_xlabel('z')
draw_vthresh(ax,0)
Nous avons maintenant un exemple :
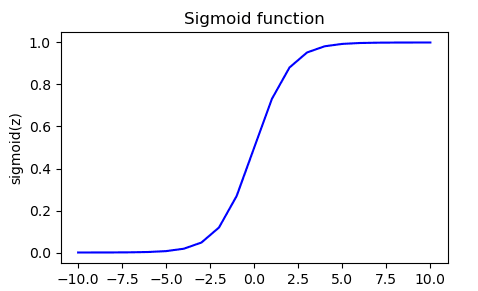
Avec comme résultat :
Input (z), Output (sigmoid(z))
[[-1.000e+01 4.540e-05]
[-9.000e+00 1.234e-04]
[-8.000e+00 3.354e-04]
[-7.000e+00 9.111e-04]
[-6.000e+00 2.473e-03]
[-5.000e+00 6.693e-03]
[-4.000e+00 1.799e-02]
[-3.000e+00 4.743e-02]
[-2.000e+00 1.192e-01]
[-1.000e+00 2.689e-01]
[ 0.000e+00 5.000e-01]
[ 1.000e+00 7.311e-01]
[ 2.000e+00 8.808e-01]
[ 3.000e+00 9.526e-01]
[ 4.000e+00 9.820e-01]
[ 5.000e+00 9.933e-01]
[ 6.000e+00 9.975e-01]
[ 7.000e+00 9.991e-01]
[ 8.000e+00 9.997e-01]
[ 9.000e+00 9.999e-01]
[ 1.000e+01 1.000e+00]]
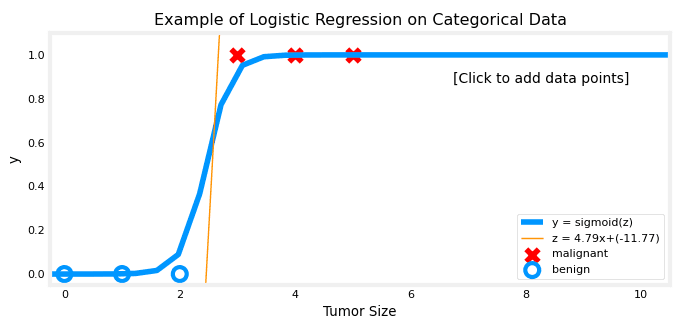
Maintenant, nous pouvons appliquer la régression logistique aux données catégorielles :
#Create training data for x and y
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train = np.array([0, 0, 0, 1, 1, 1])
#Initialize weight and bias
w_in = np.zeros((1))
b_in = 0
#Close all existing plots
plt.close('all')
#Plot the training data with the addpt function
addpt = plt_one_addpt_onclick(x_train,y_train, w_in, b_in, logistic=True)
Ce graphique est maintenant affiché:
## Introduction
The most popular and widely used learning algorithm today is called binary classification, which is used to predict one of two possible outcomes, such as whether an email is spam or not, if a financial transaction is fraudulent or not, or if a tumor is malignant or benign. This type of classification problem is called binary classification because there are only two possible classes or categories.
The two classes or categories are often designated as no or yes, false or true, or zero or one. The negative class is often referred to as the false or zero class, and the positive class is often referred to as the true or one class.
To build a classification algorithm, one approach is to use linear regression to fit a straight line to the data, but this method predicts all numbers between zero and one, rather than just the categories of zero and one. So a graph will be like :
Logistic regression
Introduction:
Logistic Regression is a commonly used classification algorithm that is used to predict binary outcomes. In this example, we will use it to classify whether a tumor is malignant or benign.
Problem:
We have a dataset where the horizontal axis is the size of the tumor and the vertical axis takes on only values of 0 and 1, because it is a classification problem. Linear regression is not a good algorithm for this problem.
Solution:
Logistic regression is used to fit an S-shaped curve to the dataset. For example, if a patient comes in with a tumor of a certain size, the algorithm will output a value between 0 and 1, suggesting the likelihood of the tumor being malignant or benign.
Sigmoid Function:
To build the logistic regression algorithm, we use an important mathematical function called the Sigmoid function, also referred to as the logistic function. The Sigmoid function outputs a value between 0 and 1, based on the input variable Z. The formula of g(z) is equal to 1 over 1 plus e to the negative z, where e is a mathematical constant that takes on a value of about 2.7.
We can represent the plot like this :
Note that we have positive and negative value for the horyzontal values (Z).
Building the Logistic Regression Model:
In the first step, we define a straight line function, like a linear regression function, which is represented by the variable Z. The next step is to take this value of Z and pass it through the Sigmoid function, which is represented by the variable g(z). This function outputs a value between 0 and 1. When z is large, g(z) is close to 1 and when z is a large negative number, g(z) is close to 0. When z is equal to 0, g(z) is equal to 0.5. This Sigmoid function is used to build the logistic regression model, which inputs a feature or set of features and outputs a number between 0 and 1
Output:
The logistic regression model takes in a set of features (i.e. input data) and outputs a value between 0 and 1, which can then be used to classify the input into one of the two possible classes. The next step is to interpret the output of the logistic regression model and make a decision based on the result.
We can define the formula as : 𝑓𝑤->,𝑏(𝑥->)=𝑤->*𝑥->+𝑏 where 𝑧 = 𝑤->*𝑥->+𝑏
We know that the sigmoide formula is : 𝑔(𝑧)=1/(1+𝑒−𝑧) We can by the way say : *𝑓𝑤->,𝑏(𝑥->) = 1/(1+𝑒−(𝑤->𝑥->+𝑏))
Example :
- X is "tumor size"
- Y is 0 (not malignant) or 1 (malignant)
𝑓𝑤->,𝑏(𝑥->) = 0.7 means that we have 70% of chance that the tumor is malignant
Implementation
Let's import our dependencies :
import numpy as np
import matplotlib.pyplot as plt
from plt_one_addpt_onclick import plt_one_addpt_onclick
from lab_utils_common import draw_vthresh
We can add our value and use the exponential function to calculate them :
# Create an input array and use the exp function to calculate the exponential of each element
input_array = np.array([1,2,3])
exp_array = np.exp(input_array)
# Print the input and output of the exp function
print("Input to exp:", input_array)
print("Output of exp:", exp_array)
Result :
Input to exp: [1 2 3]
Output of exp: [ 2.72 7.39 20.09]
Input to exp: 1
Output of exp: 2.718281828459045
We can apply our sigmoid formula : 1/(1+np.exp(-z))
# Define the sigmoid function
def sigmoid(z):
"""
Compute the sigmoid of z
Args:
z (ndarray): A scalar, numpy array of any size.
Returns:
g (ndarray): sigmoid(z), with the same shape as z
"""
g = 1/(1+np.exp(-z))
return g
We can calculate our function and display it into a graph :
# Create an array of values for z
z_tmp = np.arange(-10,11)
# Calculate sigmoid(z) for each value in the z_tmp array
y = sigmoid(z_tmp)
# Print the input and output of the sigmoid function
np.set_printoptions(precision=3)
print("Input (z), Output (sigmoid(z))")
print(np.c_[z_tmp, y])
# Plot z vs sigmoid(z)
fig,ax = plt.subplots(1,1,figsize=(5,3))
plots(1,1,figsize=(5,3))
ax.plot(z_tmp, y, c="b")
#Add title, labels and vertical threshold line to the plot
ax.set_title("Sigmoid function")
ax.set_ylabel('sigmoid(z)')
ax.set_xlabel('z')
draw_vthresh(ax,0)
We have now an example :
With values printed :
Input (z), Output (sigmoid(z))
[[-1.000e+01 4.540e-05]
[-9.000e+00 1.234e-04]
[-8.000e+00 3.354e-04]
[-7.000e+00 9.111e-04]
[-6.000e+00 2.473e-03]
[-5.000e+00 6.693e-03]
[-4.000e+00 1.799e-02]
[-3.000e+00 4.743e-02]
[-2.000e+00 1.192e-01]
[-1.000e+00 2.689e-01]
[ 0.000e+00 5.000e-01]
[ 1.000e+00 7.311e-01]
[ 2.000e+00 8.808e-01]
[ 3.000e+00 9.526e-01]
[ 4.000e+00 9.820e-01]
[ 5.000e+00 9.933e-01]
[ 6.000e+00 9.975e-01]
[ 7.000e+00 9.991e-01]
[ 8.000e+00 9.997e-01]
[ 9.000e+00 9.999e-01]
[ 1.000e+01 1.000e+00]]
Now we can apply logistic regression to the categorical data :
#Create training data for x and y
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train = np.array([0, 0, 0, 1, 1, 1])
#Initialize weight and bias
w_in = np.zeros((1))
b_in = 0
#Close all existing plots
plt.close('all')
#Plot the training data with the addpt function
addpt = plt_one_addpt_onclick(x_train,y_train, w_in, b_in, logistic=True)
We should have this graph displayed :
Frontière de décision
En régression logistique, l'objectif est de prédire si la valeur de y est 0 ou 1. Pour ce faire, un seuil est fixé, et si la probabilité prédite que y est égal à 1 (calculée à l'aide de la fonction Sigmoïde) est supérieure ou égale au seuil, la prédiction est que y est 1.
Inversement, si la probabilité prédite est inférieure au seuil, la prédiction est que y est 0. Une valeur seuil commune est 0.5, ce qui signifie que si f(x) (la sortie de la fonction Sigmoïde) est supérieure ou égale à 0.5, y est prédit comme étant 1, et si f(x) est inférieure à 0.5, y est prédit comme étant 0.
Pour visualiser comment le modèle fait des prédictions, un exemple est fourni en utilisant un problème de classification avec deux caractéristiques : x1 et x2.
- Le modèle de régression logistique utilise la fonction f(x) = g(z), où z = w1x1 + w2x2 + b.
- La ligne où wx + b = 0 est appelée la frontière de décision et sépare les points où le modèle prédit que y est 1 et y est 0.
- Cette frontière de décision est représentée par une ligne droite.
- La frontière de décision (Z= W->*X-> +b) dépend des valeurs des paramètres w1, w2 (qui sont égaux à 1) et b (-1). Donc, disons : Z= X(1,2) + X(2,2) -1 = 0 Où (Z= 3), ce qui prédit ^y = 1.
Cependant, dans des exemples plus complexes, la frontière de décision peut ne pas être une ligne droite. Par exemple, en utilisant des caractéristiques polynomiales, z peut être défini comme w1x1^2 + w2x2^2 + b, dans ce cas, la frontière de décision sera une ligne courbe. Nous pouvons dire :
Nous savons que la formule de la sigmoïde est : 𝑓𝑤->,𝑏(𝑥->) = 𝑔(𝑤1𝑥1+𝑤2𝑥2+𝑏)
La frontière de décision peut également être non linéaire. Par exemple, la frontière de décision pourrait être une courbe ou même une forme ovale, parmi d'autres formes possibles.
Fonction de coût
La fonction de coût en régression logistique est utilisée pour mesurer à quel point un ensemble spécifique de paramètres s'adapte aux données d'entraînement. Cela nous aide à choisir de meilleurs paramètres pour notre modèle.
Exemple : nous avons un ensemble d'entraînement pour notre modèle de régression logistique, où chaque ligne correspond à un patient visitant le médecin et étant diagnostiqué avec une condition. L'ensemble d'entraînement a
- un nombre m d'exemples
- chaque exemple ayant n caractéristiques telles que la taille de la tumeur et l'âge du patient.
| Taille de la tumeur | Age | Maligne |
|---|---|---|
| 24 | 30 | 1 |
| 10 | 32 | 0 |
| 5 | 23 | 0 |
| 5 | 12 | 1 |
Basé sur ce que nous avons dit :
- M est le nombre d'entraînements, m = 3
- Chaque entraînement, i a n données, ici n = 2
- L'étiquette cible Y ne peut prendre que deux valeurs, 0 ou 1
Le modèle de régression logistique est défini par l'équation : f(x) = 1/(1+e^(-wx-b))
Comment choisir les paramètres W et B ?
La fonction de coût d'erreur quadratique n'est pas un choix idéal pour la régression logistique car lorsque la fonction de coût est tracée en utilisant cette valeur de f(x), elle devient une fonction de coût non convexe avec plusieurs minima locaux. La descente de gradient peut rester bloquée dans ces minima locaux, au lieu de converger vers le minimum global. Reproduisons-le avec un graphique :
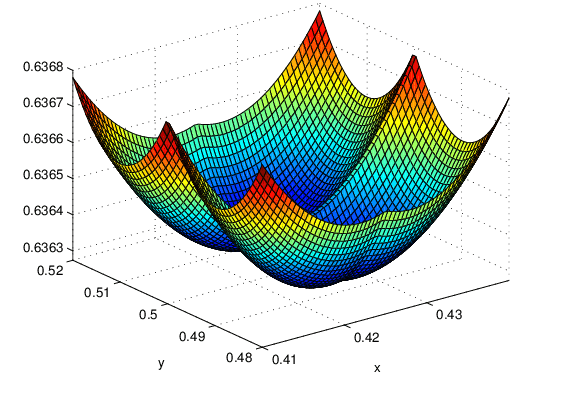
Pour surmonter cela, une fonction de coût différente est utilisée pour la régression logistique, qui rend à nouveau la fonction de coût convexe.
La nouvelle fonction de coût est définie comme : J(w,b) = 1/n * ∑L(f(x),y)
Où L est la perte sur un seul exemple d'entraînement et est une fonction de la prédiction de l'algorithme d'apprentissage, f(x) et l'étiquette vraie y.
Donc : 𝑙𝑜𝑠𝑠(𝑓𝐰,𝑏(𝐱(𝑖)),𝑦(𝑖)) qui est le coût pour un seul point de données comme :
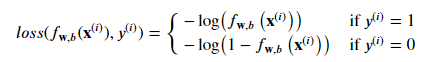
- 𝑓𝐰,𝑏(𝐱(𝑖)) est la prédiction du modèle, tandis que 𝑦(𝑖) est la valeur cible.
- 𝐰,𝑏(𝐱(𝑖))=𝑔(𝐰⋅𝐱(𝑖)+𝑏) où la fonction 𝑔 est la fonction sigmoïde.
La fonction de perte utilisée en régression logistique est caractérisée par son utilisation de deux courbes distinctes, l'une pour lorsque l'étiquette cible est 0 (y=0) et une autre pour lorsque l'étiquette cible est 1 (y=1). Ces courbes travaillent ensemble pour fournir le comportement souhaité pour une fonction de perte, qui est d'être nulle lorsque la prédiction correspond à la cible et d'augmenter rapidement de valeur lorsque la prédiction diffère de la cible. Comme on peut le voir sur le graphique, la fonction de perte est nulle lorsque la prédiction correspond à la cible, et elle augmente lorsque la prédiction diffère de la cible.
Cette fonction de perte peut être visualisée sous forme de graphique et fournit un aperçu de la performance du modèle sur un seul exemple d'entraînement. En additionnant les pertes sur tous les exemples d'entraînement, nous pouvons nous assurer que la fonction de coût globale est convexe et que la descente de gradient peut converger vers le minimum global.
Nous pouvons simplifier cette fonction de coût pour qu'elle soit plus facile à mémoriser :
𝐽(𝐰,𝑏)=1/𝑚∑𝑖=0𝑚−1[𝑙𝑜𝑠𝑠(𝑓𝐰,𝑏(𝐱(𝑖)),𝑦(𝑖))]
où
𝑙𝑜𝑠𝑠(𝑓𝐰,𝑏(𝐱(𝑖)),𝑦(𝑖)) est le coût pour un seul point de données, qui est : 𝑙𝑜𝑠𝑠(𝑓𝐰,𝑏(𝐱(𝑖)),𝑦(𝑖))=−𝑦(𝑖)log(𝑓𝐰,𝑏(𝐱(𝑖)))−(1−𝑦(𝑖))log(1−𝑓𝐰,𝑏(𝐱(𝑖)))
où m est le nombre d'exemples d'entraînement dans l'ensemble de données et :
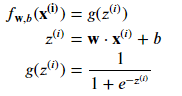
Implémentation
import numpy as np
import matplotlib.pyplot as plt
from lab_utils_common import plot_data, sigmoid, dlc
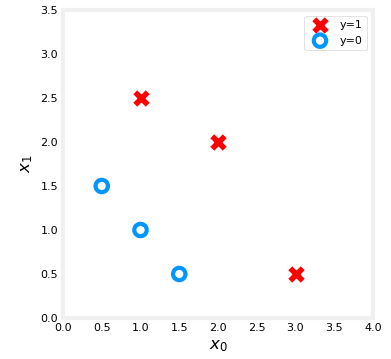
Nous pouvons définir notre ensemble de données comme suit :
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]]) #(m,n)
y_train = np.array([0, 0, 0, 1, 1, 1])
Dessinons ces données en utilisant des croix et des cercles :
fig,ax = plt.subplots(1,1,figsize=(4,4))
plot_data(X_train, y_train, ax)
# Set both axes to be from 0-4
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$', fontsize=12)
ax.set_xlabel('$x_0$', fontsize=12)
plt.show()
Voici le graph :
Nous pouvons créer notre fonction précédemment définie comme suit :
def compute_cost_logistic(X, y, w, b):
"""
Computes cost
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i)
cost = cost / m
return cost
Nous pouvons maintenant l'appliquer et vérifier le coût :
w_tmp = np.array([1,1])
b_tmp = -3
print(compute_cost_logistic(X_train, y_train, w_tmp, b_tmp))
Le résultat devrait être : 0.36686678640551745
Maintenant, voyons ce que la fonction de coût donne pour une valeur différente de 𝑤.
Dans un laboratoire précédent, vous avez tracé la frontière de décision pour 𝑏=−3,𝑤0=1,𝑤1=1. Autrement dit, vous avez eu b = -3, w = np.array([1,1]).
Supposons que vous voulez voir si 𝑏=−4,𝑤0=1,𝑤1=1 ou b = -4, w = np.array([1,1]) fournit un meilleur modèle.
Commençons par tracer la frontière de décision pour ces deux valeurs de 𝑏 pour voir laquelle correspond mieux aux données.
Pour 𝑏=−3,𝑤0=1,𝑤1=1 , nous allons tracer −3+𝑥0+𝑥1=0 (en bleu) Pour 𝑏=−4,𝑤0=1,𝑤1=1 , nous allons tracer −4+𝑥0+𝑥1=0 (en magenta)
Descente de gradient
L'objectif de la régression logistique est de trouver les valeurs des paramètres w et b qui minimisent la fonction de coût J de w et b.
La méthode utilisée pour atteindre cet objectif est la descente de gradient. La fonction de coût J est définie comme la moyenne du terme d'erreur, qui est la différence entre l'étiquette prédite y et l'étiquette réelle y.
Pour minimiser J, la dérivée de J par rapport à w et b est calculée à l'aide du calcul différentiel. La dérivée par rapport à w est 1/m fois la somme du terme d'erreur multiplié par la j-ième fonction de l'exemple d'entraînement i.
La dérivée par rapport à b est similaire, mais sans la multiplication par x_j. Ces dérivées sont introduites dans l'algorithme de descente de gradient, et les paramètres sont mis à jour simultanément.
La régression logistique est différente de la régression linéaire car la fonction f de x est définie comme la fonction sigmoïde appliquée à wx plus b, plutôt que simplement wx plus b. La descente de gradient peut également être surveillée pour assurer la convergence, et la mise à l'échelle des caractéristiques peut être utilisée pour accélérer le processus. La vectorisation peut également être utilisée pour rendre la descente de gradient plus rapide pour la régression logistique.
Basé sur ce que nous disons, nous pouvons isoler cette formule:
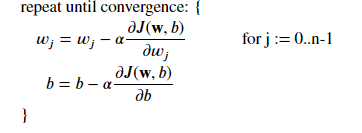
Ces 2 équations ressemblent exactement aux mêmes que pour linéaire. N'oubliez pas que la définition de la fonction F(x) a changé en utilisant le sigmoïde !
Où chaque itération effectue des mises à jour simultanées sur 𝑤𝑗 pour tous les 𝑗, où
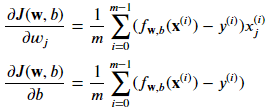
Les paramètres:
- m est le nombre d'exemples d'entraînement dans l'ensemble de données
- 𝑓𝐰,𝑏(𝑥(𝑖)) est la prédiction du modèle, tandis que 𝑦(𝑖) est la cible
La mise en œuvre de l'algorithme de descente de gradient a deux composantes principales:
La boucle mettant en œuvre l'équation de descente de gradient (1). Cela est généralement appelé la fonction "gradient_descent" et est généralement fournie en option et en pratique de laboratoires. Le calcul du gradient actuel, conformément aux équations (2,3) ci-dessus. Cela est généralement appelé la fonction "compute_gradient_logistic" et est généralement la partie de la mise en œuvre que les étudiants sont invités à compléter dans les laboratoires pratiques. La fonction "compute_gradient_logistic" est responsable du calcul du gradient pour tous 𝑤𝑗 et 𝑏 et est décrite comme suit:
Initialiser les variables pour accumuler les gradients dj_dw et dj_db Pour chaque exemple dans l'ensemble de données: a. Calculer l'erreur pour cet exemple 𝑔(𝐰⋅𝐱(𝑖)+𝑏)−𝐲(𝑖) b. Pour chaque valeur d'entrée 𝑥(𝑖)𝑗 dans cet exemple, multiplier l'erreur par l'entrée 𝑥(𝑖)𝑗 et l'ajouter à l'élément correspondant de dj_dw (équation 2 ci-dessus) c. Ajouter l'erreur à dj_db (équation 3 ci-dessus) Diviser dj_db et dj_dw par le nombre total d'exemples (m) Notez que 𝐱(𝑖) en numpy est représenté par X [i, :] ou X [i] et 𝑥(𝑖)𝑗 est X [i, j]
Nous pouvons implémenter cela, d'abord importons nos dépendances :
import copy, math
import numpy as np
import matplotlib.pyplot as plt
from lab_utils_common import dlc, plot_data, plt_tumor_data, sigmoid, compute_cost_logistic
from plt_quad_logistic import plt_quad_logistic, plt_prob
Chargeons maintenant quelques ensembles de données d'entraînement :
# Load the training dataset
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train = np.array([0, 0, 0, 1, 1, 1])
Nous allons tracer ces données à l'aide de notre fonction auxiliaire (disponible sur git) :
fig,ax = plt.subplots(1,1,figsize=(4,4))
plot_data(X_train, y_train, ax)
# Set the plot limits and labels
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$', fontsize=12)
ax.set_xlabel('$x_0$', fontsize=12)
plt.show()
Très bien, nous devrions obtenir ce résultat :
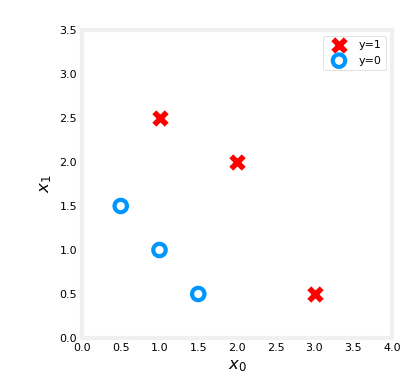
Maintenant, créons notre fonction basée sur notre formule :
def compute_gradient_logistic(X, y, w, b):
"""
Computes the gradient of the logistic cost function with respect to the parameters w and b.
"""
m,n = X.shape
dj_dw = np.zeros((n,)) #(n,)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar
err_i = f_wb_i - y[i] #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar
dj_db = dj_db + err_i
dj_dw = dj_dw/m #(n,)
dj_db = dj_db/m #scalar
return dj_db, dj_dw
Calculons et retournons quelques résultats pour avoir une vue de notre algorithme :
X_tmp = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_tmp = np.array([0, 0, 0, 1, 1, 1])
w_tmp = np.array([2.,3.])
b_tmp = 1.
dj_db_tmp, dj_dw_tmp = compute_gradient_logistic(X_tmp, y_tmp, w_tmp, b_tmp)
print(f"dj_db: {dj_db_tmp}" )
print(f"dj_dw: {dj_dw_tmp.tolist()}" )
Le code ci-dessous implémente l'équation (1) ci-dessus. Il est important de prendre un moment pour localiser et comparer les fonctions utilisées dans la routine avec les équations mentionnées ci-dessus.
def gradient_descent(X, y, w_in, b_in, alpha, num_iters):
J_history = []
w = copy.deepcopy(w_in)
b = b_in
for i in range(num_iters):
# Compute the gradient and update the parameters
dj_db, dj_dw = compute_gradient_logistic(X, y, w, b)
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save the cost function value at each iteration
if i<100000:
J_history.append( compute_cost_logistic(X, y, w, b) )
# Print the cost function value every 10th iteration or if less than 10 iterations
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]} ")
# Return the final updated parameters and the cost function history for plotting
return w, b, J_history
Exécutons la descente de gradient :
# Test the gradient computation function with a sample dataset and parameters
w_tmp = np.zeros_like(X_train[0])
b_tmp = 0.
alph = 0.1
iters = 10000
w_out, b_out, _ = gradient_descent(X_train, y_train, w_tmp, b_tmp, alph, iters)
print(f"\nupdated parameters: w:{w_out}, b:{b_out}")
Result :
Iteration 0: Cost 0.684610468560574
Iteration 1000: Cost 0.1590977666870456
Iteration 2000: Cost 0.08460064176930081
Iteration 3000: Cost 0.05705327279402531
Iteration 4000: Cost 0.042907594216820076
Iteration 5000: Cost 0.034338477298845684
Iteration 6000: Cost 0.028603798022120097
Iteration 7000: Cost 0.024501569608793
Iteration 8000: Cost 0.02142370332569295
Iteration 9000: Cost 0.019030137124109114
updated parameters: w:[5.28 5.08], b:-14.222409982019837
Nous pouvons enfin tracer le résultat :
# Create a figure with specified size
fig,ax = plt.subplots(1,1,figsize=(5,4))
# Plot the probability of the logistic regression model with updated parameters
plt_prob(ax, w_out, b_out)
# Set labels for x and y axis
ax.set_ylabel(r'$x_1$')
ax.set_xlabel(r'$x_0$')
# Set axis limits
ax.axis([0, 4, 0, 3.5])
# Plot the original data points
plot_data(X_train,y_train,ax)
# Calculate the decision boundary
x0 = -b_out/w_out[0]
x1 = -b_out/w_out[1]
# Plot the decision boundary on the same plot
ax.plot([0,x0],[x1,0], c=dlc["dlblue"], lw=1)
# Show the plot
plt.show()
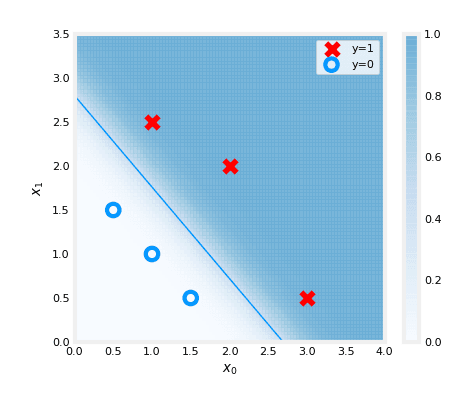
Le graphique ci-dessus illustre la probabilité de y=1, représentée par l'ombrage. La frontière de décision est représentée par la ligne à laquelle la probabilité de y=1 est égale à 0,5. Elle sépare la zone où la probabilité de y=1 est supérieure à 0,5 de la zone où elle est inférieure à 0,5. En d'autres termes, c'est la ligne qui sépare la zone où le modèle prédit y=1 de la zone où il prédit y=0.





