 Français
FrançaisInstallation
Je vous recommande d'utiliser la documentation officielle pour installer Kubernetes sur différents environnements. En effet, la documentation fournit des instructions détaillées et précises pour l'installation de Kubernetes sur différentes plateformes, telles que Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure et bien d'autres. La documentation officielle est régulièrement mise à jour et fournit des conseils utiles pour garantir une installation réussie et une utilisation optimale de Kubernetes. De plus, elle comprend des informations sur la configuration et la gestion de Kubernetes, ainsi que des astuces pour résoudre les problèmes courants. En suivant la documentation officielle, vous pouvez être sûr de bénéficier d'une installation sécurisée et fiable de Kubernetes, adaptée à votre environnement spécifique.
Master et worker
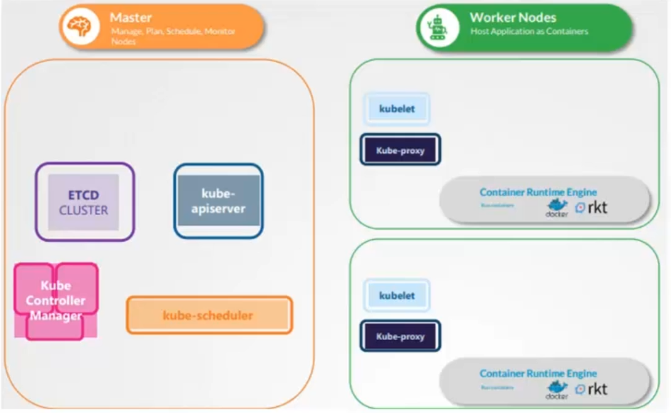
En Kubernetes, il existe deux types de nœuds : les nœuds Master et les nœuds Worker. Le nœud Master est responsable de la gestion et de la coordination du cluster, tandis que les nœuds Worker exécutent les charges de travail et les applications.
Les modules du nœud Master sont les suivants :
- Kube-apiserver : il s'agit du composant central de Kubernetes qui fournit l'interface de programmation pour l'interaction avec le cluster.
- ETCD-cluster : il s'agit d'une base de données distribuée qui stocke les informations sur l'état du cluster et les configurations des objets Kubernetes.
- Kube-scheduler : il s'agit du composant qui décide sur quel nœud Worker les charges de travail doivent être planifiées.
- Kube controller manager : il s'agit d'un ensemble de contrôleurs qui surveillent l'état du cluster et agissent en conséquence pour maintenir l'état désiré.
Les modules du nœud Worker sont les suivants :
- Kubelet : il s'agit du composant qui s'exécute sur chaque nœud Worker et qui gère l'état des conteneurs.
- Kube-proxy : il s'agit du composant responsable de la communication réseau entre les différents nœuds du cluster et des services exposés par les conteneurs.
Lorsqu'une commande est envoyée à Kubernetes, elle est interprétée par le nœud Master qui décide sur quel nœud Worker la charge de travail doit être planifiée. Le Kubelet du nœud Worker reçoit ensuite la commande et crée les conteneurs à l'aide de Docker. Une fois les conteneurs déployés sur le nœud Worker, les informations sont mises à jour dans ETCD pour refléter l'état actuel du cluster.
Le pod
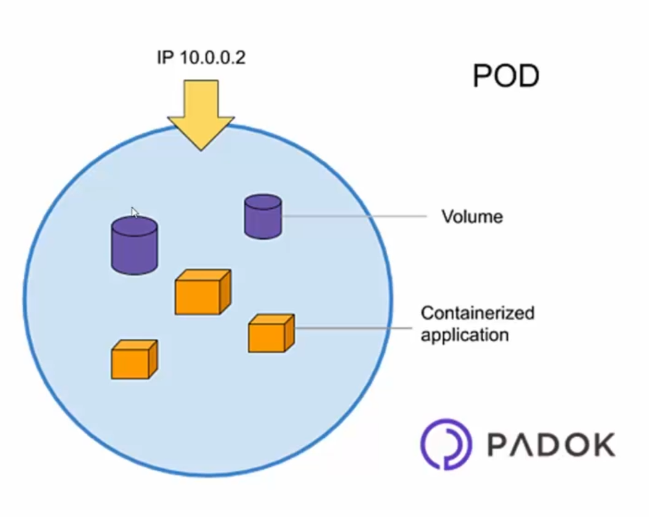
Le Pod est la plus petite unité d'exécution dans Kubernetes et il est utilisé pour héberger des conteneurs. Lorsque vous créez un Pod dans Kubernetes, vous pouvez y spécifier un ou plusieurs conteneurs qui seront exécutés ensemble sur le même nœud Worker.
En effet, les conteneurs doivent être regroupés dans un Pod pour pouvoir être déployés dans Kubernetes. Cela signifie que si vous voulez déployer un conteneur, vous devez le déployer dans un Pod.
Il est important de noter que chaque Pod a sa propre adresse IP unique et peut communiquer avec les autres Pods via un réseau virtuel interne. Cela signifie que les conteneurs qui se trouvent dans un même Pod peuvent communiquer entre eux via "localhost", même s'ils sont exécutés dans des conteneurs différents.
Lorsque vous déployez un Pod dans Kubernetes, vous pouvez spécifier les ressources (CPU, mémoire, etc.) nécessaires pour chaque conteneur, ainsi que d'autres configurations telles que des volumes de stockage partagé entre les conteneurs du Pod.
Replicat Set
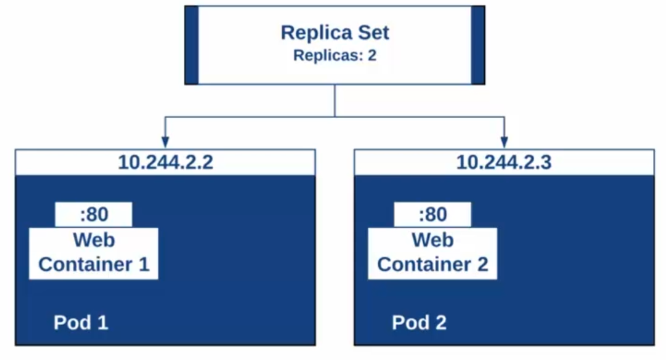
Il est important d'assurer la résilience et la haute disponibilité des applications déployées dans Kubernetes. Pour cela, on peut utiliser l'objet ReplicationController, qui est maintenant remplacé par l'objet ReplicaSet, pour gérer la réplication des Pods.
Un ReplicaSet permet de spécifier le nombre de réplicas (instances) d'un Pod que l'on souhaite avoir en cours d'exécution, ainsi que de garantir que le nombre spécifié de Pods est toujours disponible. Si l'un des Pods meurt ou est supprimé, un nouveau Pod sera automatiquement créé pour maintenir le nombre de réplicas souhaité.
Cela permet d'assurer une haute disponibilité de l'application, même en cas de panne ou d'incident. De plus, on peut également utiliser ReplicaSet pour augmenter ou diminuer dynamiquement le nombre de réplicas en fonction de la demande, afin d'améliorer la scalabilité de l'application.
En ce qui concerne la gestion de version, on peut utiliser l'objet Deployement qui permet de gérer le déploiement de différentes versions d'une application. Ainsi, lorsque vous mettez à jour une application, vous pouvez utiliser le Deployement pour gérer le déploiement progressif de la nouvelle version tout en maintenant la disponibilité de l'ancienne version.
Le déployeur
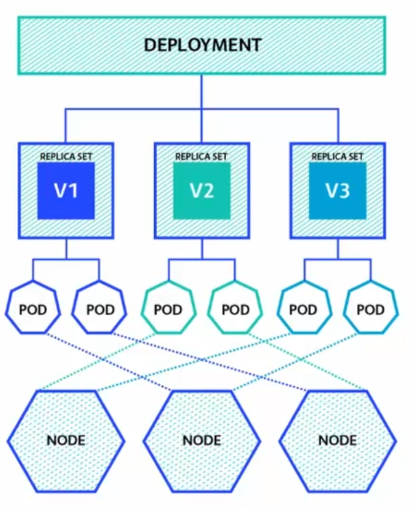
Le Deployement est un objet Kubernetes qui permet de gérer les déploiements d'applications en contrôlant les ReplicaSets sous-jacents.
Le Deployement permet de spécifier la version de l'application à déployer, ainsi que les paramètres de configuration associés. Il fournit également des fonctionnalités de gestion de version et de mise à jour des applications. Par exemple, vous pouvez utiliser le Deployement pour déployer une nouvelle version d'une application tout en gardant l'ancienne version en cours d'exécution, puis basculer progressivement vers la nouvelle version en utilisant des stratégies de déploiement comme le Rolling Update.
En plus de la gestion de version, le Deployement permet également d'assurer la scalabilité en modifiant dynamiquement le nombre de répliques de l'application en fonction de la demande. Vous pouvez facilement augmenter ou diminuer le nombre de répliques en modifiant simplement la configuration du Deployement. Par exemple, vous pouvez augmenter le nombre de répliques d'un Deployement de 2 à 3 pour mieux répondre à une demande accrue.
Kubectl
Il existe deux types de commandes pour piloter Kubernetes : les commandes impératives et les commandes déclaratives.
Les commandes impératives sont des commandes de ligne de commande qui permettent de manipuler les ressources Kubernetes directement à partir de la ligne de commande. Elles sont très utiles pour les opérations simples et rapides telles que la création d'un Pod ou la suppression d'une ressource. Les commandes impératives sont utilisées en spécifiant une série de paramètres et de variables d'environnement directement dans la ligne de commande.
Les commandes déclaratives sont des commandes qui utilisent un fichier de configuration YAML ou JSON pour décrire l'état désiré du cluster Kubernetes. Elles permettent de créer, mettre à jour ou supprimer des ressources Kubernetes en se basant sur un état désiré décrit dans le fichier de configuration. Les commandes déclaratives sont particulièrement utiles pour les opérations plus complexes, telles que la création de plusieurs ressources en même temps ou la gestion de la mise à jour d'une application dans le temps.
En utilisant les deux types de commandes, il est possible de piloter et de gérer efficacement Kubernetes. Les commandes impératives sont utiles pour les opérations rapides et simples, tandis que les commandes déclaratives sont plus adaptées aux opérations plus complexes et à la gestion de l'état des ressources dans le temps.
Kubectl -action -type -objet
#exemple
Kubectl get pod nginx
Kubectl delete replicaset test
Kubectl create deployment app
Manifeste
En Kubernetes, un manifeste est un fichier YAML ou JSON qui décrit l'état désiré d'une ou plusieurs ressources Kubernetes. Il s'agit d'un fichier de configuration déclarative qui permet de spécifier les détails de configuration pour créer, mettre à jour ou supprimer des ressources Kubernetes, telles que des Pods, des ReplicaSets, des Deployments, des Services, des ConfigMaps, des Secrets, etc.
Le manifeste permet de décrire les caractéristiques de la ressource, telles que les volumes, les ports, les labels, les annotations, les images Docker à utiliser, les politiques de redémarrage, les quotas de ressources, etc. Une fois le manifeste créé, il peut être appliqué au cluster Kubernetes à l'aide d'une commande de ligne de commande telle que kubectl apply -f fichier-manifeste.yaml.
L'avantage d'utiliser des manifestes est qu'ils permettent une gestion plus efficace et automatisée des ressources dans Kubernetes, en spécifiant l'état désiré des ressources dans un fichier de configuration déclarative. De plus, les manifestes peuvent être versionnés et stockés dans un système de contrôle de code source tel que Git, permettant de gérer facilement les modifications et les mises à jour de configuration.
Mise en exécution
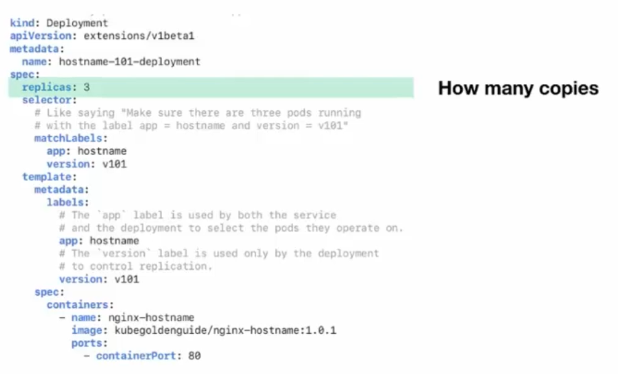
C'est un object yaml, plus précisément un fichier de configuration pour l'application que nous voulons déployer.
- kind : type d'objet
- apiVersion : version de l'API
- name: nom de l'objet
- replicas : nombre de replicas
- spec: spécification de l'objet a déployer
- image: image docker a lancer
Exemple :
apiVersion: v1
kind: Pod
metadata:
name: simple-webapp-color
labels:
app: web
spec:
containers:
- name: web
image: mmumshad/simple-webapp-color
ports:
- containerPort: 8080
env:
- name: APP_COLOR
value: red
Ce manifeste peut ensuite être lancé à travers la commande :
kubectl apply -f pod.yml
pod/simple-webapp-color created
Pour voir si les pods sont bien démarrés :
[node1 ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
simple-webapp-color 0/1 ContainerCreating 0 37s
Ici, il est en cours de création pour avoir des détails sur la création :
[node1 ~]$ kubectl describe
error: You must specify the type of resource to describe. Use "kubectl api-resources" for a complete list of supported resources.
[node1 ~]$ kubectl describe po simple-webapp-color
Name: simple-webapp-color
Namespace: default
Priority: 0
Node: node1/10.0.0.3
Start Time: Mon, 20 Dec 2021 05:36:41 +0000
Labels: app=web
Annotations:
Status: Running
IP: 10.32.0.4
IPs:
IP: 10.32.0.4
Containers:
web:
Container ID: docker://4c65229efd830f5eb79621b34539aad27caad583ad12ff5628b9547ce0ed7b41
Image: mmumshad/simple-webapp-color
Image ID: docker-pullable://mmumshad/simple-webapp-color@sha256:637eff5492960b6620d2c86bb9a5355408ebfc69234172502049e34b6ee94057
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 20 Dec 2021 05:38:48 +0000
Ready: True
Restart Count: 0
Environment:
APP_COLOR: red
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-8x5v4 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-8x5v4:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-8x5v4
Optional: false
QoS Class: BestEffort
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m21s default-scheduler Successfully assigned default/simple-webapp-color to node1
Normal Pulling 2m20s kubelet, node1 Pulling image "mmumshad/simple-webapp-color"
Normal Pulled 35s kubelet, node1 Successfully pulled image "mmumshad/simple-webapp-color" in 1m45.390758129s
Normal Created 14s kubelet, node1 Created container web
Normal Started 14s kubelet, node1 Started container web
On peut ensuite exposer notre application sur le port 8080 :
[node1 ~]$ kubectl port-forward simple-webapp-color 8080:8080 --address 0.0.0.0
Forwarding from 0.0.0.0:8080 -> 8080
Si je veux supprimer le pod :
[node1 ~]$ kubectl delete -f pod.yml
pod "simple-webapp-color" deleted
C'est bien beau tout cela, mais le mieux serait de créer notre objet deployement. Pour cela nous pouvons utiliser un fichier manifeste :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80
On lance notre déployement :
[node1 ~]$ kubectl apply -f nginx-deployment.yml
deployment.apps/nginx-deployment created
Pour voir les détails de l'image qui a été lancée :
[node1 ~]$ kubectl get replicaset -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx-deployment-67dfd6c8f9 2 2 2 110s nginx nginx:1.18.0 app=nginx,pod-template-hash=67dfd6c8f9
Maintenant si l'on voulait passer à la dernière version de notre nginx, on a juste a changer la version de notre image :
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
On relance ce deployement :
[node1 ~]$ kubectl applyl -f nginx-deployment.yml
deployment.apps/nginx-deployment configured
On voit ici qu'il reconfigure et ne redeployement l'existant et si je veux plus de détail :
[node1 ~]$ kubectl get replicaset -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx-deployment-67dfd6c8f9 0 0 0 6m1s nginx nginx:1.18.0 app=nginx,pod-template-hash=67dfd6c8f9
nginx-deployment-845d4d9dff 2 2 2 86s nginx nginx app=nginx,pod-template-hash=845d4d9dff
On voit qu'avant de supprimer le deployement précédent on attend que le nouveau soit up pour que cela soit transparent pour l'utilisateur.
La gestion du réseau
La gestion des labels est très importante en Kubernetes, car elle permet d'identifier et de sélectionner des ressources spécifiques dans le cluster. Lorsque vous créez une ressource Kubernetes, vous pouvez ajouter des labels qui sont des paires clé-valeur qui identifient la ressource de manière unique.
Dans l'exemple précédent, le label app: nginx est ajouté à la fois au Deployment et au Pod créé par le Deployment. Ce label peut ensuite être utilisé pour sélectionner le Pod spécifique à partir d'un ensemble de Pods. Par exemple, si vous souhaitez exposer le Deployment en tant que Service, vous pouvez créer un Service qui sélectionne les Pods ayant le label app: nginx.
La sélection de ressources en fonction des labels se fait à l'aide de sélecteurs. Les sélecteurs sont utilisés pour filtrer les ressources Kubernetes en fonction de leurs labels. Dans l'exemple précédent, le sélecteur spécifie que les Pods sélectionnés doivent avoir le label app: nginx.
En utilisant des labels et des sélecteurs, il est possible de gérer efficacement les ressources dans Kubernetes, en permettant de sélectionner et de cibler des ensembles spécifiques de ressources pour des opérations telles que la mise à jour, la surveillance ou la suppression.
Maintenant que la notion de labels est introduise, prenons le cas suivant :
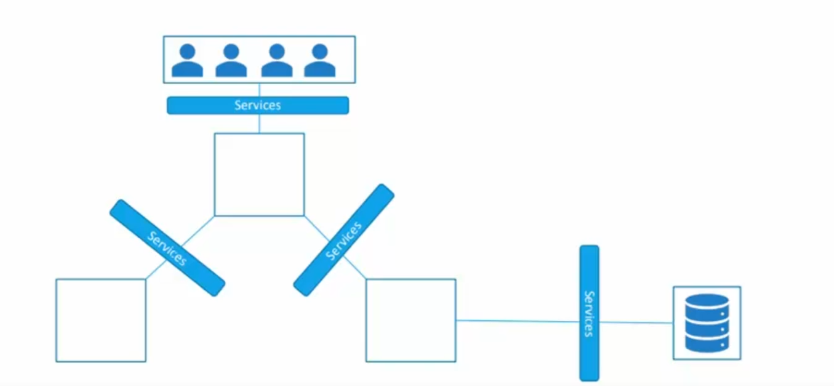
Nous disposons d'applications sous forme de pods, que les utilisateurs vont utiliser pour se connecter. Cependant, si certains pods sont perdus, le replica redéploiera automatiquement de nouveaux pods, mais les utilisateurs ne seront pas informés de la nouvelle adresse des pods. Par conséquent, il est nécessaire de mettre en place un mécanisme de fédération pour relier les utilisateurs et les pods : les services. Les services sont des objets Kubernetes qui permettent d'exposer un ensemble de pods via un point d'entrée, ce qui facilite la redistribution des adresses des différents pods.
Ainsi, chaque service dans Kubernetes a pour mission de fédérer un ensemble de pods par un point d'entrée. Il existe plusieurs types de services dans Kubernetes :
- NodePort : crée un service qui permet d'exposer l'ensemble des pods via un port en dehors de la machine, pour permettre l'accès aux utilisateurs.
- ClusterIP : crée un service qui permet d'exposer les pods uniquement à l'intérieur du cluster. Le front-end communique uniquement avec le back-end en interne, sans rendre ce dernier accessible de l'extérieur.
- LoadBalancer : permet d'exposer les services directement à un fournisseur de services Cloud. L'utilisateur se connecte au loadbalancer, qui est une IP fournie par le Cloud, et le loadbalancing est délégué au fournisseur de services Cloud.
Dans le cas de nos applications, il est important de séparer les environnements par namespace, où chacun est indépendant de l'autre. Par exemple, nous pouvons définir un namespace pour l'environnement de développement et un autre pour l'environnement de production, afin qu'ils ne puissent pas accéder l'un à l'autre et qu'ils puissent partager les mêmes données de manière sécurisée.
apiVersion: v1
kind: Namespace
metadata:
name: production
Ensuite il est nécessaire de créer ce namespace :
[node2 ~]$ kubectl apply -f namespace.yml
On peut très facilement regarder l'état de notre namespace :
[node2 ~]$ kubectl get namespaces
NAME STATUS AGE
default Active 4m57s
kube-node-lease Active 4m59s
kube-public Active 4m59s
kube-system Active 4m59s
production Active 103s
Pour mettre un pod dans un namespace, il existe deux solutions :
-
Spécifier le namespace dans le manifeste : Il est possible de spécifier le namespace dans le fichier YAML du manifeste du pod. Pour cela, il faut ajouter la ligne "namespace:
" dans la section "metadata" du manifeste. -
Utiliser la commande kubectl apply avec l'option -n : Il est également possible de lancer la commande "kubectl apply -f pod.yml -n
" pour appliquer le manifeste d'un pod dans un namespace spécifique.
Pour vérifier que les pods ont bien été créés dans le namespace souhaité, il suffit de lancer la commande "kubectl get pods -n
[node2 ~]$ kubectl get po -n production
Comment créer un NodePort ?
apiVersion: v1
kind: Service
metadata:
name: service-nodeport-web
spec:
type: NodePort
#selector du label
selector:
app: web
ports:
- protocol: TCP
port: 8080
targetPort: 8080
#port exposé
nodePort: 30008
Et vous connaissez la chanson, si nous voulons déployer notre service, mais en précisant le namespace :
[node2 ~]$ kubectl apply -f service-nodeport-web.yml -n production
Comment vérifier nodeport fonctionne bien :
[node1 ~]$ kubectl -n production describe svc service-nodeport-web
Name: service-nodeport-web
Namespace: production
Labels:
Annotations:
Selector: app=web
Type: NodePort
IP: 10.100.84.248
Port: 8080/TCP
TargetPort: 8080/TCP
NodePort: 30008/TCP
Endpoints:
Session Affinity: None
External Traffic Policy: Cluster
Events:
Il existe un autre moyen d'exposer les services dans Kubernetes, qui est Ingress. Contrairement à NodePort qui permet d'exposer les services en utilisant une adresse IP, Ingress permet d'exposer les services directement à l'extérieur du cluster Kubernetes, en utilisant une adresse URL personnalisée (par exemple posos.com).
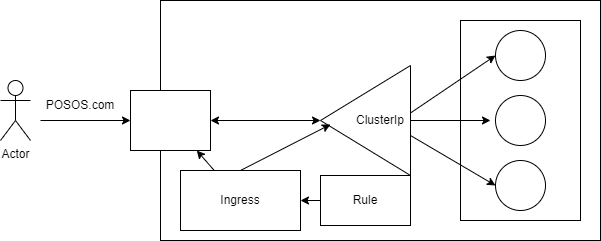
Ingress agit comme un reverse proxy et permet de router les requêtes entrantes vers les services appropriés en fonction de règles de routage définies. Il prend en charge la terminaison SSL et permet de configurer des politiques de sécurité pour protéger les services exposés.
Pour utiliser Ingress, il faut d'abord installer un contrôleur Ingress, qui est un composant qui surveille les ressources Ingress et configure le reverse proxy en conséquence. Il existe plusieurs contrôleurs Ingress disponibles, tels que Nginx, Traefik, ou encore Istio.
Une fois que le contrôleur Ingress est installé, il est possible de définir des règles de routage pour les services à exposer à l'extérieur du cluster en utilisant les annotations Ingress dans le manifeste du service. Ces annotations permettent de spécifier les règles de routage, ainsi que les politiques de sécurité pour chaque service.
La gestion du stockage
Lorsque des conteneurs sont utilisés pour exécuter des applications, la persistance des données est un problème crucial. En effet, en général, lorsque l'un des conteneurs disparaît ou est supprimé, toutes les données stockées dans ce conteneur sont également perdues. De plus, les conteneurs ne peuvent pas communiquer leurs données entre eux de manière native.
Pour résoudre ces problèmes, il est possible d'utiliser des volumes. Les volumes sont des mécanismes de stockage de données qui permettent aux conteneurs de partager et de persister les données. Les volumes peuvent être configurés de manière à être associés à un ou plusieurs conteneurs et à être partagés entre eux.
L'utilisation de volumes permet aux conteneurs de persister leurs données même si le conteneur est supprimé ou redémarré. De plus, les volumes permettent aux conteneurs de communiquer entre eux en partageant des données communes. Cela permet d'améliorer la portabilité des applications et de faciliter la mise en œuvre de architectures basées sur les microservices.
Créons notre premier volume :
apiVersion: v1
kind: Pod
metadata:
name: mysql-volume
spec:
containers:
- image: mysql
name: mysql
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-data
env:
- name: MYSQL_ROOT_PASSWORD
value: password
- name: MYSQL_DATABASE
value: eazytraining
- name: MYSQL_USER
value: eazy
- name: MYSQL_PASSWORD
value: eazy
volumes:
- name: mysql-data
hostPath:
# chemin du dossier sur l'hôte
path: /data-volume
# ce champ est optionnel
type: Directory
On lance ensuite notre volume :
[node2 ~]$ kubectl apply -f mysql-volume.yml
Pour voir le status de notre pod nous pouvons faire un get po :
[node2 ~]$ kubectl get po
Nous savons montez le volume, c'est bien mais allons plus loin en utilisant le volume de persistence :
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data-pv"
Ici l'on fait une stockage local, l'on peut bien entendu faire du stockage de volumes dans d'autre environnements cloud. Nous avons maintenant du PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
Il est important d'avoir le même storageClassName que le PV Il est important d'avoir le même accessModes que le PV On un PVC pour un PV ! Pas plus si l'allocution de la mémoire n'est pas bonne vous perdez cette mémoire Le stockage sera valade si tout les clusters Créons maintenant le volume pour ce PVC :
apiVersion: v1
kind: Pod
metadata:
name: mysql-pv
spec:
containers:
- image: mysql
name: mysql
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-data
env:
- name: MYSQL_ROOT_PASSWORD
value: password
- name: MYSQL_DATABASE
value: eazytraining
- name: MYSQL_USER
value: eazy
- name: MYSQL_PASSWORD
value: eazy
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: pvc
Grâce au PVC, il est possible de créer un lien entre un volume et un conteneur de manière à ce que le volume soit automatiquement monté dans le conteneur lorsqu'il est créé ou redémarré. Cela permet de garantir la persistance des données stockées dans le volume, même si le conteneur est supprimé ou redémarré.
Ainsi, en utilisant le PVC, le volume devient persistent et est disponible pour tous les pods qui y sont associés. Cela facilite la gestion des volumes de stockage dans les environnements Kubernetes, notamment dans les architectures basées sur les microservices.
HELM
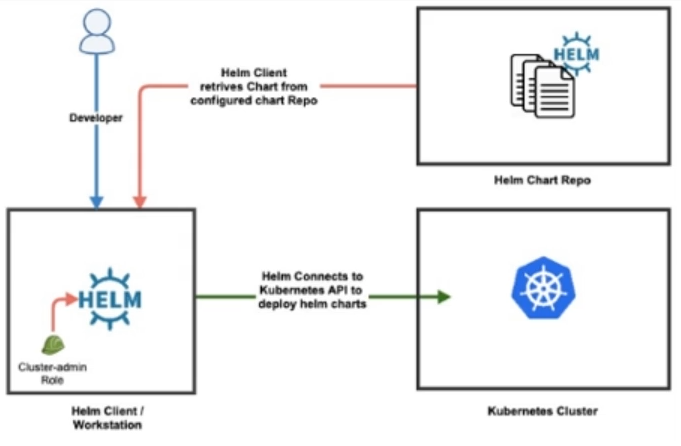
Helm est un outil qui permet de gérer les applications Kubernetes de manière efficace. Les charts Helm sont des packages pré-configurés qui facilitent la définition, l'installation et la mise à niveau des applications Kubernetes, même les plus complexes.
Les charts Helm sont faciles à créer, à versionner, à partager et à publier. Ils permettent aux utilisateurs de Kubernetes de standardiser leurs déploiements en utilisant des fichiers YAML qui contiennent des informations sur les ressources à déployer, les configurations à appliquer et les dépendances à installer.
L'utilisation des charts Helm permet également de versionner Kubernetes pour différents environnements, en utilisant des charts différents pour chaque environnement. Cela permet de faciliter la gestion des environnements de développement, de test et de production, en garantissant que chaque environnement est configuré de manière cohérente et réutilisable.
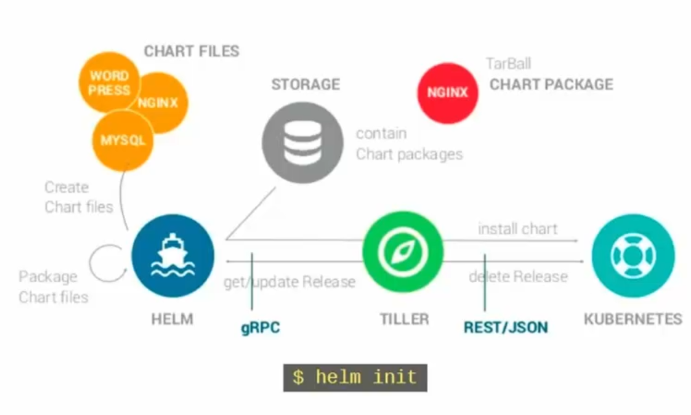
Mais à quoi ressemblent ces fameuses charts :
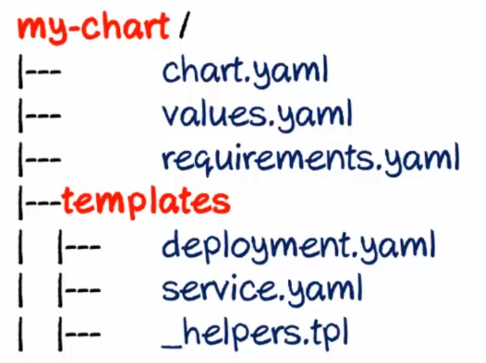
- values.yaml : contiens l'ensemble des variables par défaut
- requirement.yaml: ensemble des charts nécessaire comme dépendances
- templates: templatise les fichiers kubernetes
Installation de HELM
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
yum install openssl -y
./get_helm.sh
Le repository de bitnami permet d'ajouter des repositories de charts :
[node2 ~]$ helm repo add bitnami https://charts.bitnami.com/bitnami
Ainsi si je veux installer wordpress par exemple :
helm install wordpress bitnami/wordpress -f
Je n'ai juste qu'à puller le repository qui lui correspond et ensuite l'installer ! HELM se comporte comme maven, npm, gradle, conda, pip pour installer vos packages
Tekton
Tekton est un projet open-source de la Cloud Native Computing Foundation (CNCF) qui fournit des outils pour créer et gérer des pipelines de développement d'applications Kubernetes. Tekton permet de créer des pipelines de manière modulaire en utilisant des tâches et des ressources réutilisables.
Les tâches dans Tekton sont des actions atomiques, telles que la compilation, la construction d'images, les tests ou le déploiement, qui peuvent être réutilisées dans plusieurs pipelines. Les ressources sont des objets Kubernetes tels que les images Docker, les sources de code, les configurations et les outils, qui peuvent être utilisés dans les tâches.
Tekton fournit également un ensemble d'APIs pour gérer les pipelines et les exécuter. Les pipelines peuvent être définis en utilisant des fichiers YAML, qui spécifient les tâches à exécuter, les ressources à utiliser et les paramètres de configuration. Les pipelines peuvent être déclenchés automatiquement en réponse à des événements tels que des changements de code ou des demandes de fusion de code.
Tekton est conçu pour être extensible et compatible avec d'autres outils de développement et de déploiement d'applications Kubernetes, tels que Helm, Istio et Knative. Cela permet aux utilisateurs de personnaliser leur environnement de développement d'applications et de créer des pipelines qui répondent à leurs besoins spécifiques.
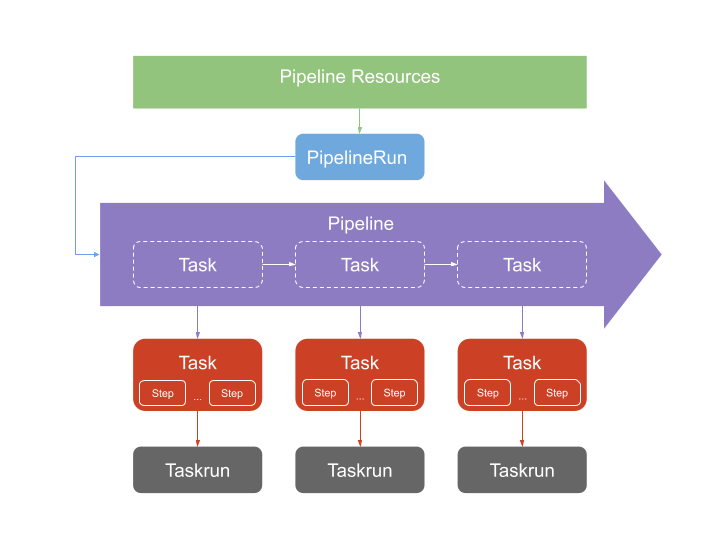
- On récupère nos ressources, qui sont nos ressources (dockerfiles) que l'on veut pousser vers le cluster
- On a ensuite une task, qui permet le modèle de la tache que l'on souhaite exécuter (récupération de l'image, push de l'image)
- On exécute cette task avec un Taskrun, on instancie donc la tache, en fournissant un certain nombre de paramètres.
- L'ensemble de ces tasks sont manager par une pipeline : C'est un modèle de taches à exécuter, il faut référence aux différentes taches. On est sur un modèle de référence.
- Pour exécuter cette pipeline : PipelineRun. Permets d'instancier la pipeline directement.
Définir une task :
Il est nécessaire de préciser l'emplacement de notre ressource en utilisant le fichier Docker. En utilisant des paramètres, nous pouvons rendre cette spécification générique et éviter les répétitions de données codées en dur.
La section "resources" permet de définir l'emplacement des ressources à récupérer (inputs) ainsi que des résultats générés (outputs).
Dans ce cas, nous allons créer des images à partir desquelles nous pourrons déployer des conteneurs dans le cluster. Cependant, le processus de déploiement ne sera pas couvert dans le fichier suivant.
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: build-docker-image-from-git-source
spec:
params:
- name: pathToDockerFile
type: string
description: The path to the dockerfile to build
default: $(resources.inputs.docker-source.path)/Dockerfile
- name: pathToContext
type: string
description: |
The build context used by Kaniko
(https://github.com/GoogleContainerTools/kaniko#kaniko-build-contexts)
default: $(resources.inputs.docker-source.path)
resources:
inputs:
- name: docker-source
type: git
outputs:
- name: builtImage
type: image
steps:
- name: build-and-push
image: gcr.io/kaniko-project/executor:v0.16.0
# specifying DOCKER_CONFIG is required to allow kaniko to detect docker credential
env:
- name: "DOCKER_CONFIG"
value: "/tekton/home/.docker/"
command:
- /kaniko/executor
args:
- --dockerfile=$(params.pathToDockerFile)
- --destination=$(resources.outputs.builtImage.url)
- --context=$(params.pathToContext)
Le déploiement de cette tache se fait grâce à notre commande kubectl, qui se chargera de déployer l'image précédemment buildée :
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: deploy-using-kubectl
spec:
params:
- name: path
type: string
description: Path to the manifest to apply
- name: yamlPathToImage
type: string
description: |
The path to the image to replace in the yaml manifest (arg to yq)
resources:
inputs:
- name: source
type: git
- name: image
type: image
steps:
- name: replace-image
image: mikefarah/yq:3
command: ["yq"]
args:
- "w"
- "-i"
- "$(params.path)"
- "$(params.yamlPathToImage)"
- "$(resources.inputs.image.url)"
- name: run-kubectl
image: lachlanevenson/k8s-kubectl
command: ["kubectl"]
args:
- "apply"
- "-f"
- "$(params.path)"
Maintenant que notre tache ainsi que son déploiement son fait, l'étape suivante consiste à lancer l'initialisation de cette tache, autrement dit le TaskRun :
apiVersion: tekton.dev/v1beta1
kind: TaskRun
metadata:
name: build-docker-image-from-git-source-task-run
spec:
serviceAccountName: simple-webapp-docker-service
taskRef:
name: build-docker-image-from-git-source
params:
- name: pathToDockerFile
value: Dockerfile
- name: pathToContext
value: $(resources.inputs.docker-source.path)/
resources:
inputs:
- name: docker-source
resourceRef:
name: simple-webapp-docker-git
outputs:
- name: builtImage
resourceRef:
Le paramètre "ServiceAccountName" permet de spécifier le nom du service à déployer. Il existe une série de paramètres et de ressources qui permettent de surcharger l'instance.
Il n'est pas toujours nécessaire d'utiliser "TaskRun", car la "pipeline" peut elle-même se charger de transmettre les paramètres nécessaires.
Une fois que la "TaskRun" est définie, nous pouvons passer à la partie qui lancera l'ensemble des tâches : la "pipeline".
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: simple-webapp-docker-pipeline
spec:
resources:
- name: source-repo
type: git
- name: web-image
type: image
tasks:
- name: build-simple-webapp-docker-web
taskRef:
name: build-docker-image-from-git-source
params:
- name: pathToDockerFile
value: Dockerfile
- name: pathToContext
value: /workspace/docker-source/ #configure: may change according to your source
resources:
inputs:
- name: docker-source
resource: source-repo
outputs:
- name: builtImage
resource: web-image
- name: deploy-web
taskRef:
name: deploy-using-kubectl
resources:
inputs:
- name: source
resource: source-repo
- name: image
resource: web-image
from:
- build-simple-webapp-docker-web
params:
- name: path
value: /workspace/source/kubernetes/deployment.yml #configure: may change according to your source
- name: yamlPathToImage
value: "spec.template.spec.containers[0].image"
Dans la section "Tasks", nous appelons notre tâche (dans notre cas : une seule tâche a été définie précédemment) en lui transmettant les paramètres nécessaires pour créer une "TaskRun". Autrement dit, une grande partie de ce que nous avons défini dans notre "TaskRun" peut également être définie ici.
Nous utilisons le résultat obtenu par l'exécution de la tâche pour lancer le déploiement.
Maintenant que la "pipeline" est définie, nous pouvons instancier cette dernière à l'aide de la "PipelineRun", qui lancera l'exécution de la "pipeline".
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: simple-webapp-docker-pipeline-run-1
spec:
serviceAccountName: simple-webapp-docker-service
pipelineRef:
name: simple-webapp-docker-pipeline
resources:
- name: source-repo
resourceRef:
name: simple-webapp-docker-git
- name: web-image
resourceRef:
name: simple-webapp-docker-image
La "PipelineRun" prend comme référence la "pipeline" que nous avons définie précédemment, ainsi que les ressources et paramètres à utiliser pour l'exécution.
Maintenant que nos fichiers sont prêts, nous pouvons procéder à l'installation de Tekton.
kubectl apply --filename https://storage.googleapis.com/tekton-releases/pipeline/latest/release.yaml
On doit ensuite créer nos crédentials :
kubectl create secret docker-registry regcred \
--docker-server="https://index.docker.io/v1/" \
--docker-username=dirane \
--docker-password="mypassword" \
--docker-email=youremail@email.com
On créé ensuite notre service account :
kubectl apply -f https://link-to.simple-webapp-docker-service.yml
Notre service est maintenant appliqué, on créé ensuite notre clusterRole pour définir l'ensemble des droits :
kubectl create clusterrole simple-webapp-docker-role \
--verb=* \
--resource=deployments,deployments.apps
kubectl create clusterrolebinding simple-webapp-docker-binding \
--clusterrole=simple-webapp-docker-role \
--serviceaccount=default:simple-webapp-docker-service
Nous avons créé un "ClusterRole" pour notre déploiement ainsi qu'un "ClusterRoleBinding", chacun accordant différents droits.
Après cela, nous installons notre "Pipeline". Mais avant cela, il est important de créer la ressource "Git" ainsi que son image.
kubectl apply -f code-resource.yml
kubectl apply -f image-resource.yml
On créé notre task et notre taskrun pour automatiser notre build d'image :
kubectl apply -f task.yml
kubectl apply -f taskrun.yml
kubectl get tekton-pipelines
kubectl describe taskrun build-docker-image-from-git-source-task-run
Avant de continuer, on vérifié que le taskrun fonctionne bien, nous pouvons vérifier que l'image est poussé sur notre dockerrhup rep. Passons à la création de la pipeline qui va builder et déployer notre application :
kubectl apply -f deploy-using-kubectl.yml
kubectl apply -f pipeline.yml
kubectl apply -f pipelinerun.yml
kubectl get tekton-pipelines
kubectl describe pipelinerun.tekton.dev/simple-webapp-docker-pipeline-run-1
Vérifions que notre application est déployé et basé sur notre fichier de déployement :
kubectl get pod
On vérifie que le pod est un nouveau créé et l'on vérifie que l'application répond bien :
kubectl port-forward $(kubectl get po -l app=simple-webapp-docker -o=name) 8080:8080 --address 0.0.0.0
Pour confirmer que l'application a été déployée en utilisant le fichier de déploiement, vous pouvez vérifier si un nouveau pod a été créé en utilisant la commande "kubectl get pod". De plus, vous pouvez vous assurer que l'application fonctionne correctement en exécutant la commande "kubectl port-forward $(kubectl get po -l app=simple-webapp-docker -o=name) 8080:8080 --address 0.0.0.0" pour rediriger le port de l'application et vérifier qu'elle répond correctement.





