 Français
FrançaisIntroduction
Les réseaux de neurones à convolution (CNN) sont une classe de réseaux de neurones profonds largement utilisés pour la reconnaissance d'images, la vision par ordinateur, la reconnaissance de la parole et le traitement du langage naturel. Les CNN ont révolutionné la façon dont les ordinateurs traitent les images en leur permettant de reconnaître et de classer les objets dans les images avec une grande précision. Leur architecture est basée sur des couches de convolution qui permettent d'extraire les caractéristiques des images de manière automatique, suivi de couches de sous-échantillonnage qui réduisent la dimensionnalité des données et enfin des couches de classification qui permettent de prédire la classe d'une image. Dans cet article, nous allons explorer les principes de base des CNN et leur application dans différents domaines.
Comment cela fonctionne
Les réseaux de neurones à convolution, ou CNN, sont une technique d'intelligence artificielle qui permet de comprendre des images à l'aide d'un algorithme. Le fonctionnement de cette technique est simple à comprendre.
Premièrement, on envoie une image dans le réseau de neurones. Celui-ci la traite en plusieurs étapes. Tout d'abord, il identifie les formes de base présentes dans l'image, comme les bords et les angles. Ensuite, il combine ces formes pour en extraire des caractéristiques plus complexes, comme des motifs ou des textures. Finalement, il utilise ces caractéristiques pour déterminer ce que représente l'image.

Pour faciliter cette extraction de caractéristiques, le réseau de neurones utilise des filtres qui passent sur l'image à différentes échelles. Ces filtres sont les couches de convolution. Ensuite, pour réduire la taille des données et en garder l'essentiel, les couches de sous-échantillonnage sont utilisées. Enfin, les couches de classification permettent de prédire la classe de l'image.
Pour que le réseau de neurones puisse lire une image, il faut d'abord l'entraîner. Cela signifie que nous lui présentons des images et lui indiquons les catégories auxquelles elles appartiennent. Le réseau apprend alors à reconnaître les caractéristiques qui différencient les différentes catégories.
Une fois que le réseau a été entraîné, il peut être utilisé pour prédire la catégorie d'une nouvelle image. Cependant, il est important de noter que les prédictions ne sont pas toujours fiables à 100%. Il peut y avoir des erreurs ou des imprécisions.
Mais comment le réseau de neurones arrive-t-il à lire une image ?
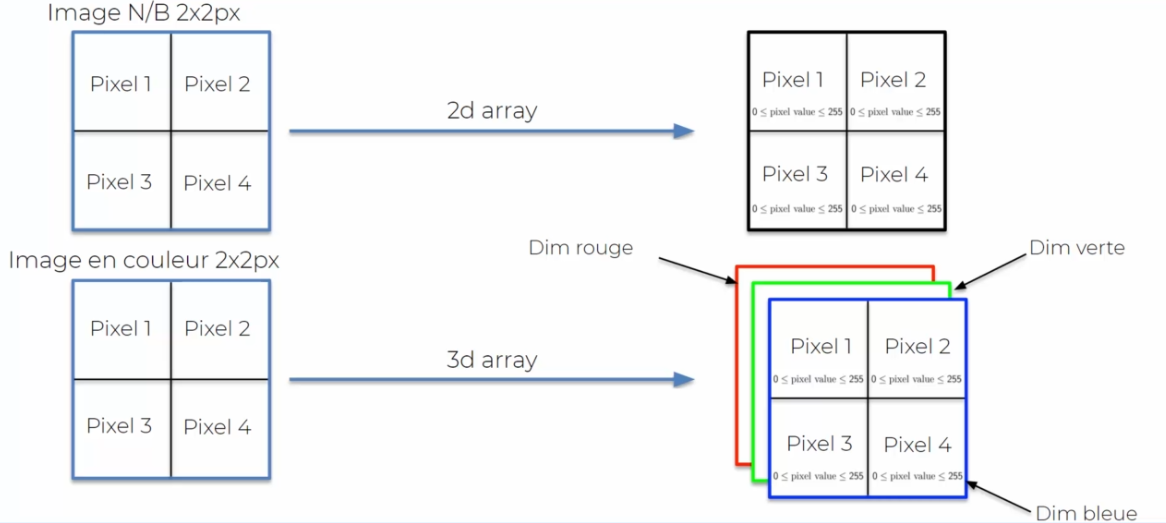
Tout d'abord, il faut savoir qu'une image est composée d'un amas de pixels. Chaque pixel a une valeur de 0 à 255 pour le noir et blanc, ou de 0 à 255 pour chaque canal de couleur (rouge, vert et bleu) dans le cas d'une image en couleur. Le réseau de neurones peut donc lire l'image en la décomposant en un tableau de pixels. Il utilise ensuite des couches de convolution pour identifier les caractéristiques de l'image, telles que les bords, les motifs ou les textures. Ces caractéristiques sont ensuite combinées et utilisées pour prédire la catégorie de l'image.
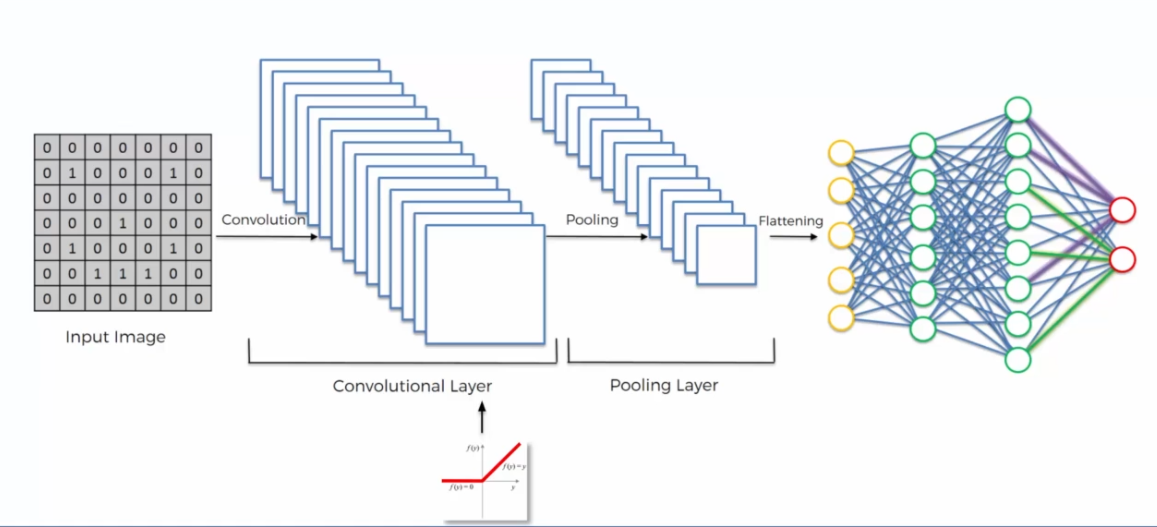
Convolution
Prenons maintenant le cas d'une image en pixels. Comme mentionné précédemment, une image est un amas de pixels:
Pour traduire une image en une chaine de caractères, nous avons besoin d'un détecteur de caractéristiques. Ce détecteur va permettre de détecter les caractéristiques de l'image qui sont importantes pour la classification.
Le détecteur de caractéristiques est un petit tableau de nombres appelé "filtre" ou "noyau". Le filtre est appliqué à l'image en multipliant ses valeurs par les valeurs des pixels de l'image correspondantes. Cette opération est appelée "convolution".
La convolution produit une nouvelle image, appelée carte de caractéristiques. Cette carte de caractéristiques est une représentation de l'image qui met en évidence les caractéristiques détectées par le filtre. Par exemple, si le filtre détecte des bords horizontaux, la carte de caractéristiques mettra en évidence les bords horizontaux présents dans l'image.
Le détecteur de caractéristiques peut être entraîné sur de nombreuses images pour détecter différentes caractéristiques. Plusieurs détecteurs de caractéristiques peuvent également être combinés pour détecter des caractéristiques plus complexes.
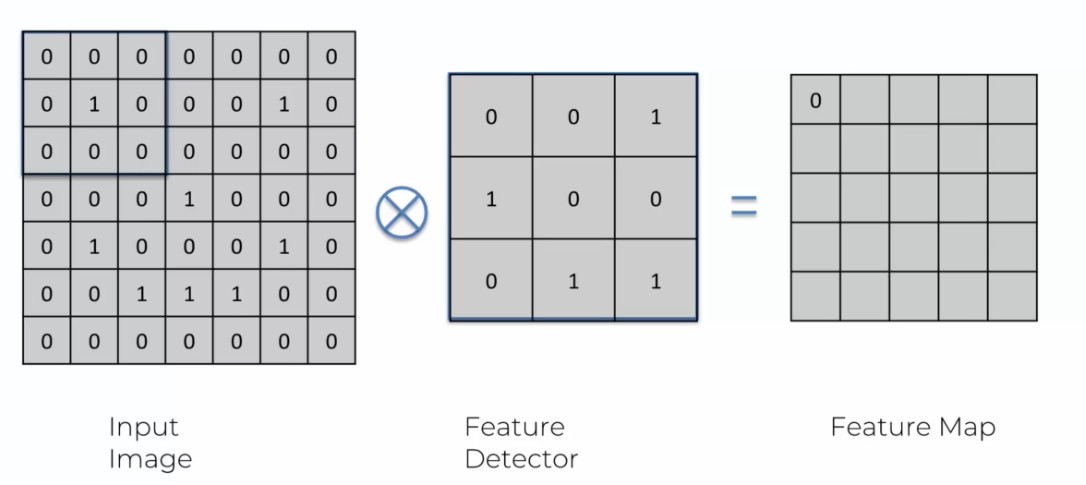
Pour illustrer le fonctionnement de la convolution, prenons l'exemple d'un détecteur de caractéristiques de taille 3x3 appliqué à une image de même taille.
Pour commencer la convolution, on place le détecteur sur le coin supérieur gauche de l'image. On multiplie ensuite les valeurs du détecteur par les valeurs correspondantes de l'image, puis on additionne les résultats. Cela donne un seul nombre qui représente la valeur de cette zone de l'image. Ce processus est répété pour chaque zone de l'image.
Si le détecteur ne détecte pas de caractéristique dans cette zone de l'image, la valeur obtenue sera proche de zéro. Si le détecteur détecte une caractéristique, la valeur obtenue sera plus grande. Cette opération est répétée pour chaque zone de l'image, créant ainsi une nouvelle image appelée "carte de caractéristiques" ou "feature map".
Dans l'exemple ci-dessus, si l'ensemble du détecteur de caractéristiques est multiplié par la partie de l'image correspondante, la réponse obtenue sera constamment 0. Cela signifie que cette zone de l'image ne contient pas la caractéristique que le détecteur est conçu pour trouver.
Pour continuer la convolution, on déplace le détecteur vers la droite et on répète le processus. On continue à déplacer le détecteur de gauche à droite jusqu'à ce que la fin de la ligne soit atteinte. Ensuite, on déplace le détecteur vers le bas d'une rangée et on recommence le processus. On répète ce processus pour chaque zone de l'image.
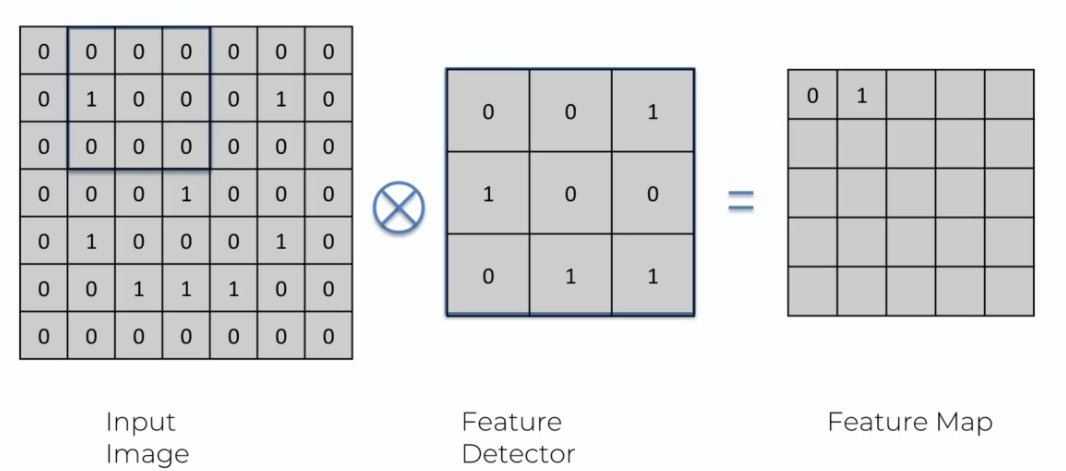
Lors de la convolution, il est possible d'obtenir plusieurs réponses positives pour une même caractéristique. Dans ce cas, chaque réponse positive est inscrite dans la feature map. Pour cela, on place une marque (un 1 dans l'exemple ci-dessous) sur chaque emplacement où la caractéristique est détectée.
Si l'on détecte plusieurs occurrences de la même caractéristique, on additionne les marques pour obtenir la valeur finale pour cette zone de la feature map.
Bien entendu, nous pouvons utiliser des détecteurs plus grands, mais le 3X3 est un standard utilisé qui offre de bonnes performances. Il sera plus couteux en temps, car on traverse l'image, mais permet une analyse précise de cette image. À la fin de notre convolution dans cet exemple, nous obtenons ce résultat:
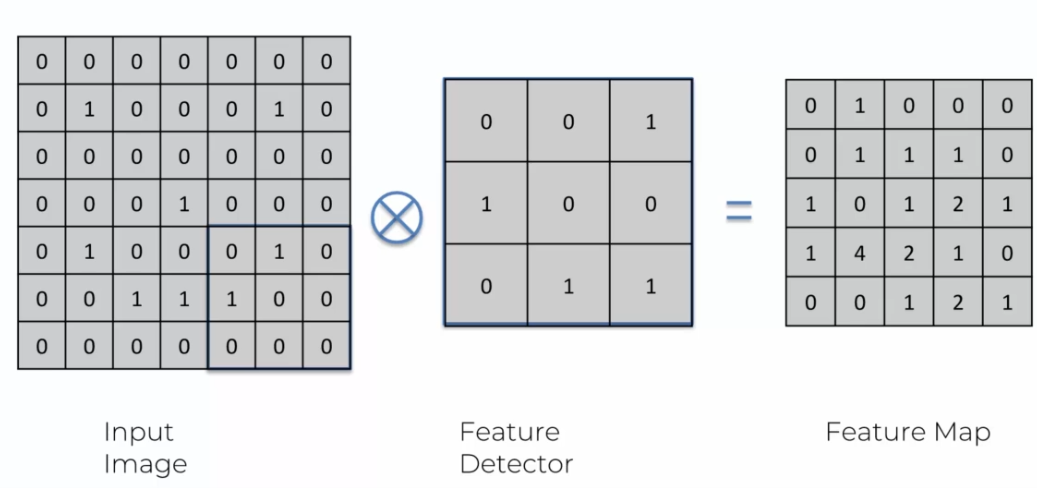
Nous avons donc réduit notre image qui était de 7X7 à 5X5, on créé alors une feature map qui nous permet d'identifier l'image plus facilement.
La fonction Relu
Maintenant que nous avons créé notre feature map en appliquant la convolution à l'image, il est temps d'appliquer une fonction redresseur. La fonction la plus couramment utilisée pour cela est la fonction Relu.
La fonction Relu est importante car elle rend les résultats de la convolution non linéaires. En effet, les contours et les détails d'une image ne sont pas linéaires. La fonction Relu permet donc de les accentuer et de mettre en évidence les caractéristiques les plus importantes de l'image.
La fonction Relu permet également de supprimer les valeurs négatives dans la feature map. Les valeurs négatives sont souvent associées à la couleur noire dans l'image. En retirant ces valeurs, la fonction Relu simplifie l'image en la rendant plus facile à interpréter par le réseau de neurones.
Cette fonction mathématique s'applique à chaque élément de la feature map produite par la convolution. Elle est définie comme suit :
$$Relu(x) = max(0,x)$$
Relu retourne 0 si l'entrée est négative et l'entrée elle-même si elle est positive ou nulle. Cette fonction a l'avantage d'être très simple et très rapide à calculer.
La fonction Relu présente également un autre avantage important : elle ne modifie pas la taille de la feature map. En effet, elle ne fait que remplacer les valeurs négatives par des zéros. Cela permet de conserver la taille de la feature map et de faciliter le calcul de la convolution sur les couches suivantes du réseau de neurones.
Le pooling
Une image peut être orientée à l'envers, montrer une personne dans une position différente ou montrer une partie différente de la personne. Cela peut sembler compliqué car il existe de nombreuses possibilités, mais notre cerveau est capable de reconnaître une personne dans toutes ces situations.
Pour que les modèles de reconnaissance d'images fonctionnent, ils doivent être capables de s'adapter à toutes ces situations. Pour cela, on utilise une technique appelée "max pooling". Cette technique ressemble beaucoup à l'étape de convolution vue précédemment, mais en prenant toujours le maximum des valeurs des carrés 2 par 2 de la feature map.
Le max pooling permet de simplifier l'image tout en conservant les caractéristiques importantes. En prenant le maximum des valeurs de chaque carré, on garde les caractéristiques les plus importantes de la feature map tout en réduisant sa taille. Cela permet également de rendre le modèle plus robuste en éliminant les petites variations d'une feature qui pourraient être dues au bruit dans l'image.
Exemple
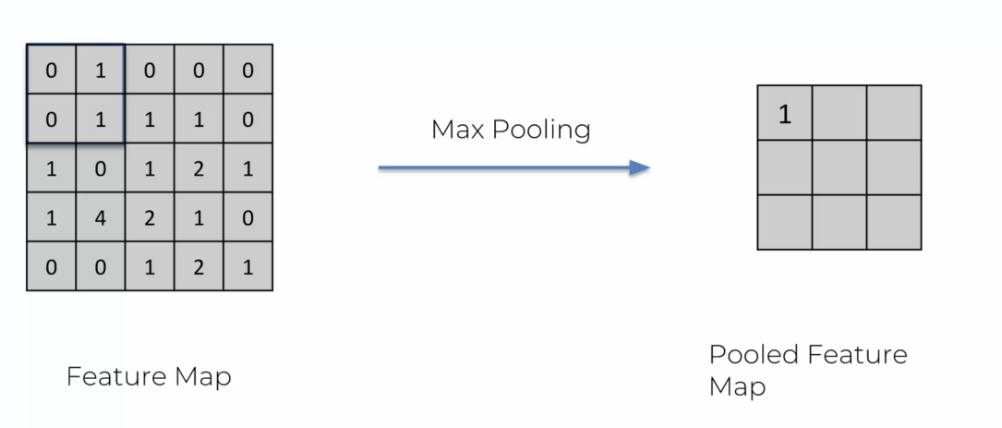
Nous nous déplaçons constamment vers la droite, mais contrairement à la convolution, nous prenons une matrice plus petite. Lorsque nous nous déplaçons vers la droite, nous ne nous arrêtons pas pour passer à la ligne. Au lieu de cela, nous lisons la valeur en prenant en compte que nous avons seulement deux éléments au lieu de quatre.
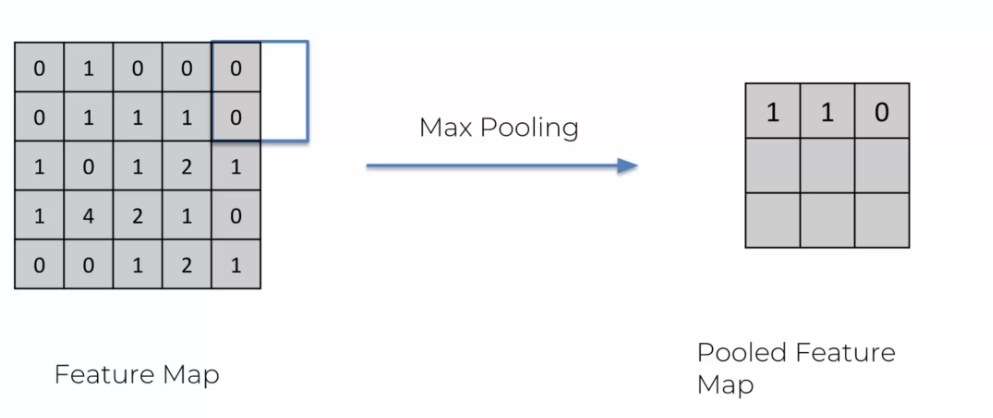
On continue alors jusqu'à obtenir une matrice totalement remplie:
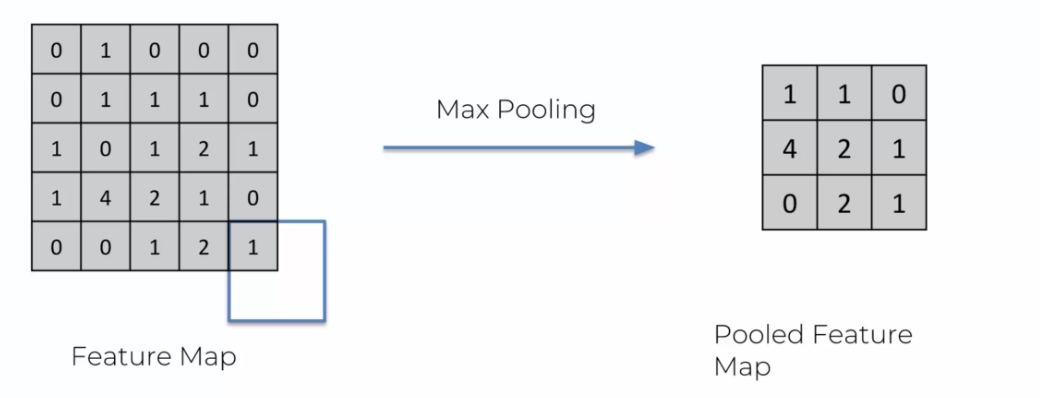
En retirant de l'information, nous constatons que le nombre de zéros diminue. Cependant, cette information retirée n'est pas nécessaire pour notre modèle. En effet, il est possible de déterminer un visage sans avoir besoin de voir le paysage en arrière-plan, ou de deviner la personne sans connaître ses habits. Par conséquent, en retirant ces informations, nous évitons le surapprentissage et obtenons un modèle plus performant.
La couche d'aplatissement
La couche d'aplatissement est l'étape la plus simple à comprendre après le pooling. Elle consiste à aplatir la matrice en une seule ligne. Cette étape permet de préparer les données pour les passer dans le réseau de neurones.
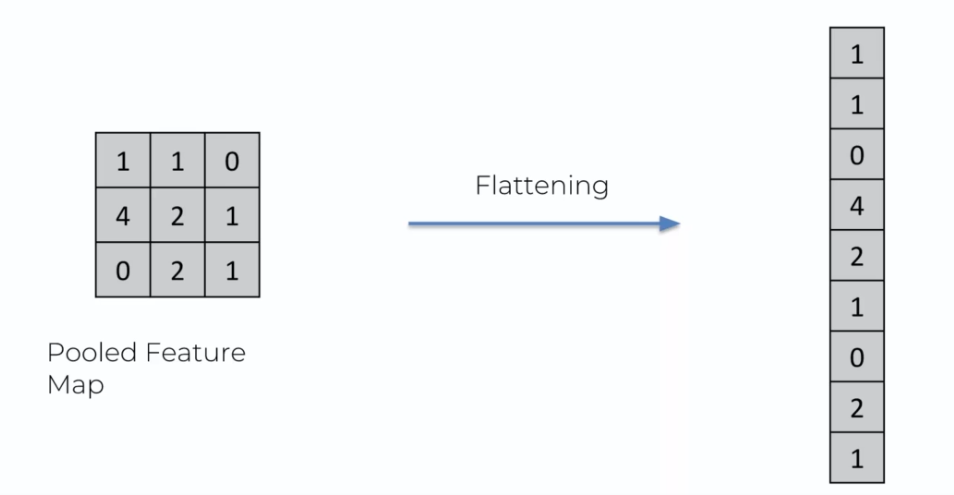
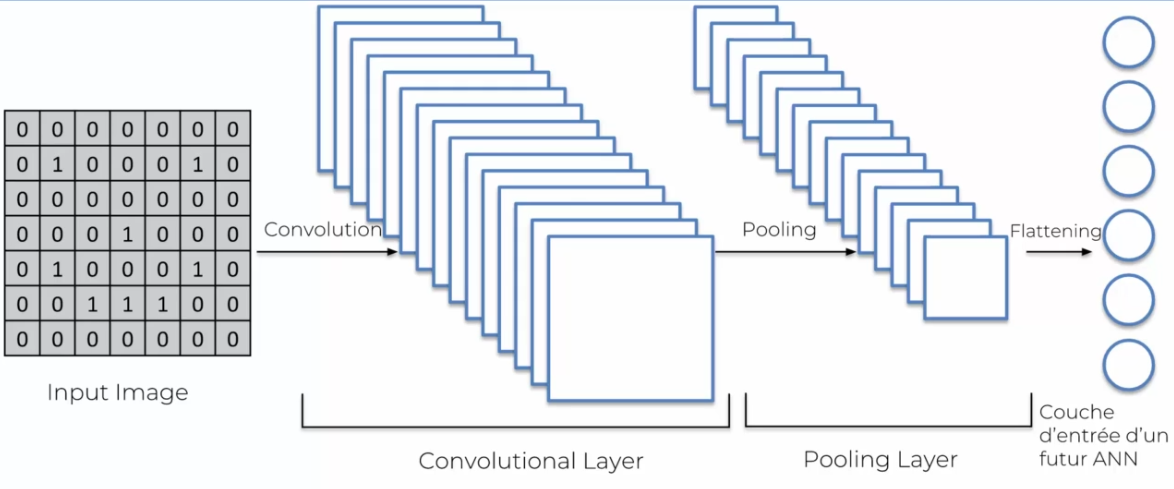
La couche d'aplatissement crée une couche d'entrée pour notre réseau de neurones en transformant l'image aplatit en une ligne de données. En résumé, voici comment notre image est traduite jusqu'à présent dans le réseau :
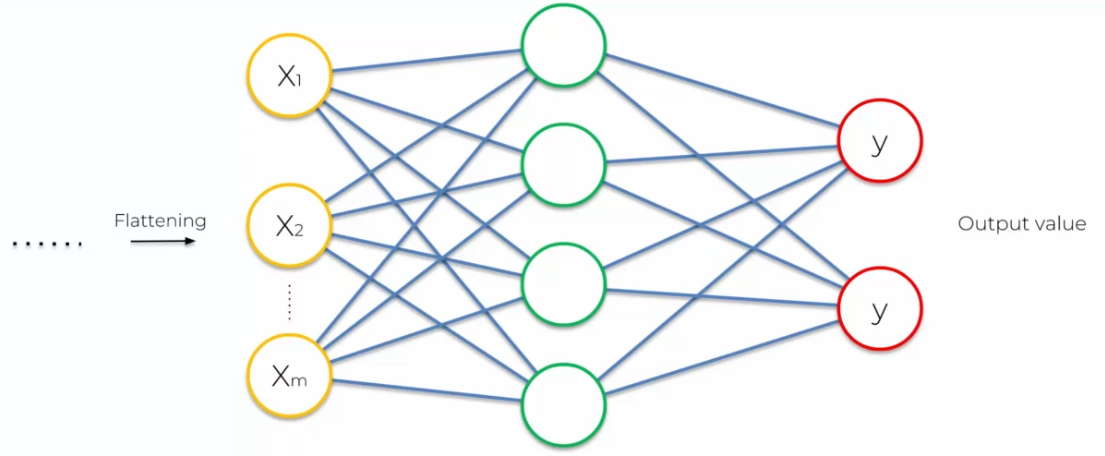
La couche complètement connectée
La dernière étape du processus de traitement d'image consiste à ajouter un réseau de neurones complètement connecté à côté du réseau de neurones à convolution. Cette étape est essentielle pour la classification de l'image, car elle permet au modèle d'apprendre des caractéristiques plus complexes et de prendre des décisions en fonction de ces caractéristiques. Le réseau de neurones complètement connecté est constitué de plusieurs couches de neurones qui sont connectées entre elles. Ces neurones prennent en entrée les données de la couche précédente et produisent des sorties qui sont transmises à la couche suivante. Les sorties de la dernière couche de neurones sont utilisées pour la classification de l'image en fonction des classes prédéfinies. L'ajout de ce réseau de neurones complètement connecté améliore les performances du modèle de traitement d'image et permet d'obtenir des résultats plus précis.
Prenons l'exemple d'un modèle de classification d'image qui doit distinguer entre les images de chats et de chiens:
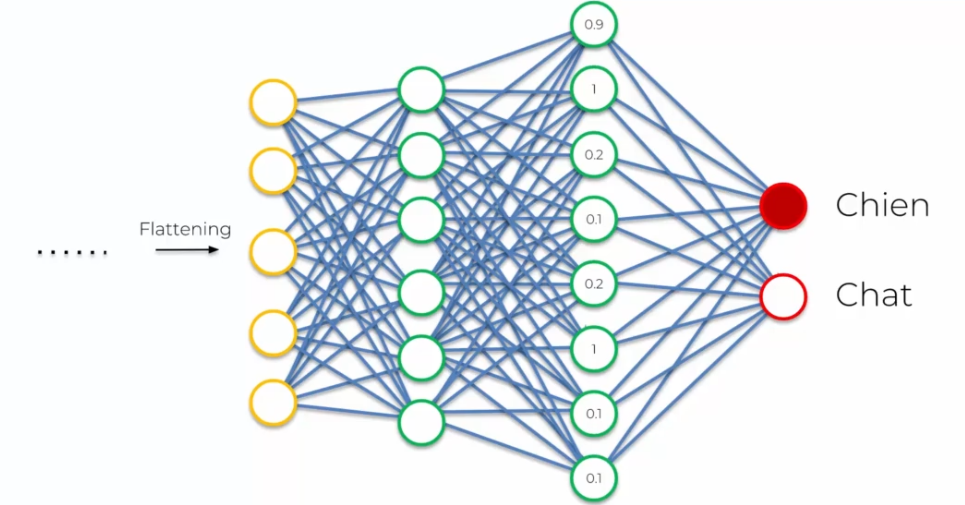
Le modèle commence par appliquer des filtres de convolution pour extraire les caractéristiques des images, telles que les bords, les formes et les textures des différentes parties de l'image. Ensuite, il applique une fonction de pooling pour réduire la taille de l'image tout en conservant les informations importantes.
Après cela, la couche d'aplatissement transforme les données en une ligne de valeurs, qui est ensuite transmise au réseau de neurones complètement connecté. Le réseau de neurones complètement connecté est entraîné à apprendre les caractéristiques des images de chats et de chiens en ajustant les poids de ses neurones. Les poids sont ajustés en fonction de la sortie du modèle pour chaque image, qui indique s'il s'agit d'un chat ou d'un chien.
Lorsque le modèle est testé sur une nouvelle image, il applique les filtres de convolution pour extraire les caractéristiques de l'image, réduit la taille de l'image avec le pooling, puis utilise le réseau de neurones complètement connecté pour déterminer s'il s'agit d'un chat ou d'un chien en fonction des caractéristiques apprises lors de l'entraînement.
Globalement, notre réseau ressemble à :
La fonction softmax et l'entropie croisée
La fonction softmax est souvent utilisée dans le domaine de l'apprentissage automatique et du traitement du langage naturel pour convertir les scores d'un vecteur en probabilités, en particulier pour la classification de données en plusieurs classes. La formule de la fonction softmax est la suivante :
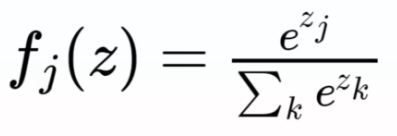
En régression logistique, lorsque l'on doit faire face à un grand nombre de choix possibles, on utilise souvent la fonction de max-pooling qui sélectionne la valeur maximale comme réponse. Cette fonction est souvent utilisée avec l'entropie croisée, une fonction de coût couramment utilisée pour mesurer la différence entre la distribution de probabilité réelle et celle estimée par le modèle. Mathématiquement, l'entropie croisée est définie comme suit :
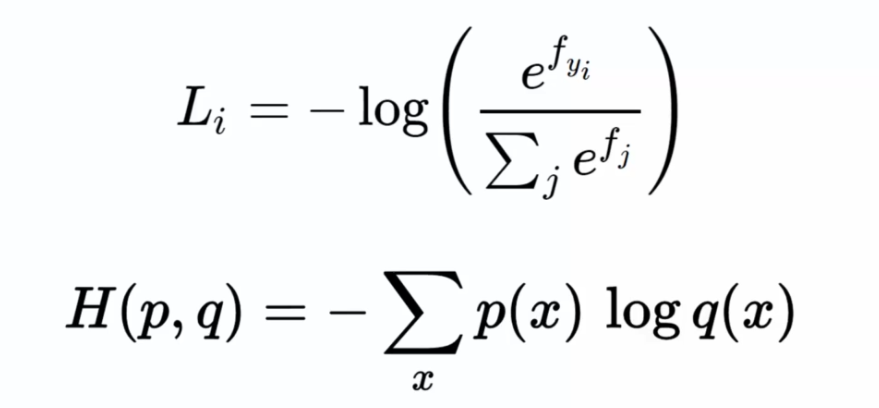
Lorsque l'on crée un réseau de neurones, on doit définir une fonction de coût qui mesure l'écart entre les prédictions du modèle et les vraies valeurs des données. Dans le cas des réseaux de neurones classiques, on utilise souvent l'erreur au carré (différence entre les valeurs réelles Y et les prédictions ^Y). L'objectif est de minimiser cette fonction de coût en ajustant les poids du réseau, à travers une procédure de calcul du gradient.
Cependant, pour les réseaux à convolution, on utilise plutôt l'entropie croisée comme fonction de coût. L'entropie croisée mesure la différence entre la distribution de probabilité réelle des données et celle estimée par le modèle. Elle est particulièrement adaptée aux problèmes de classification, où chaque donnée doit être classée dans une ou plusieurs catégories.
Lors du processus d'entraînement, le réseau de neurones à convolution utilise la méthode de rétropropagation du gradient pour ajuster les poids du réseau de manière à minimiser la fonction de coût. À chaque itération, le réseau calcule la valeur de la fonction de coût et ajuste les poids en fonction du gradient de cette fonction par rapport aux poids. Ce processus est répété jusqu'à ce que la fonction de coût soit suffisamment faible, ou que le nombre d'itérations maximum soit atteint.
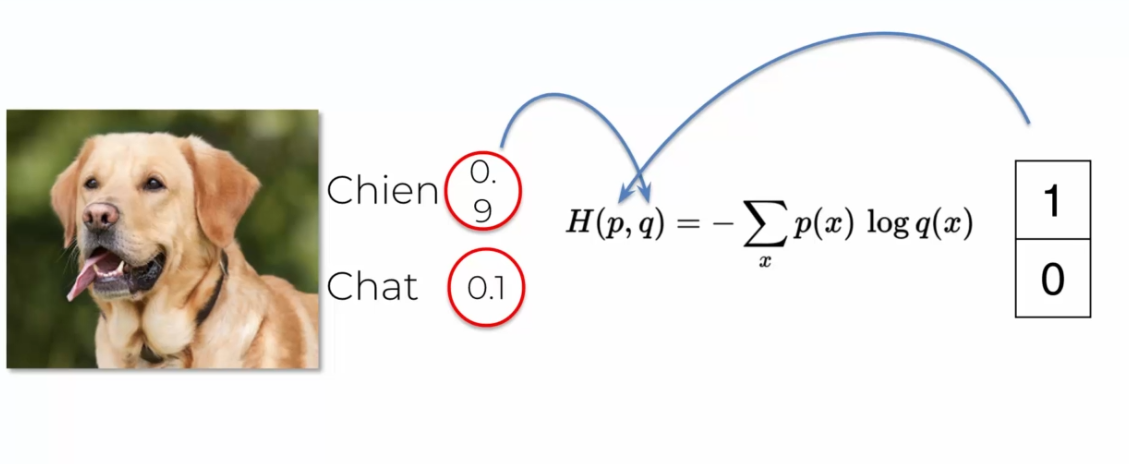
L'utilisation de l'entropie croisée comme fonction de coût dans les réseaux de neurones à convolution présente plusieurs avantages par rapport à d'autres fonctions de coût, telle que l'erreur au carré. L'un des avantages est sa capacité à gérer les problèmes de classification multi-classes.
Prenons l'exemple de deux réseaux de neurones, NN1 et NN2, utilisant respectivement l'erreur au carré et l'entropie croisée comme fonction de coût. Imaginons que nous avons trois images d'un chien, d'un chat et d'un chien bizarre, et que ces deux réseaux de neurones produisent des résultats différents pour l'image du chien bizarre, avec une erreur élevée pour NN1 et une faible erreur pour NN2.
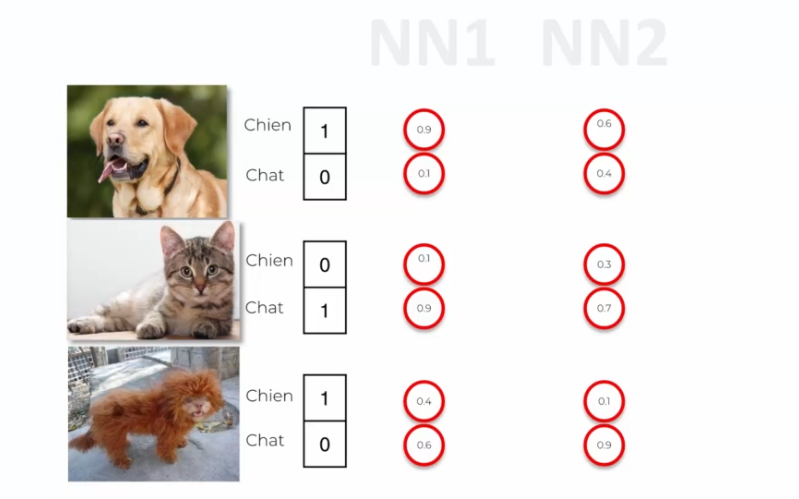
L'un des avantages de l'utilisation de l'entropie croisée dans les réseaux de neurones à convolution est qu'elle peut aider à éviter les problèmes de convergence lente lors de l'entraînement. En effet, si les valeurs de sortie sont initialement très petites par rapport aux vraies valeurs, l'utilisation de l'erreur quadratique moyenne (différence au carré) peut ralentir considérablement le processus d'apprentissage, car le gradient sera également très petit.
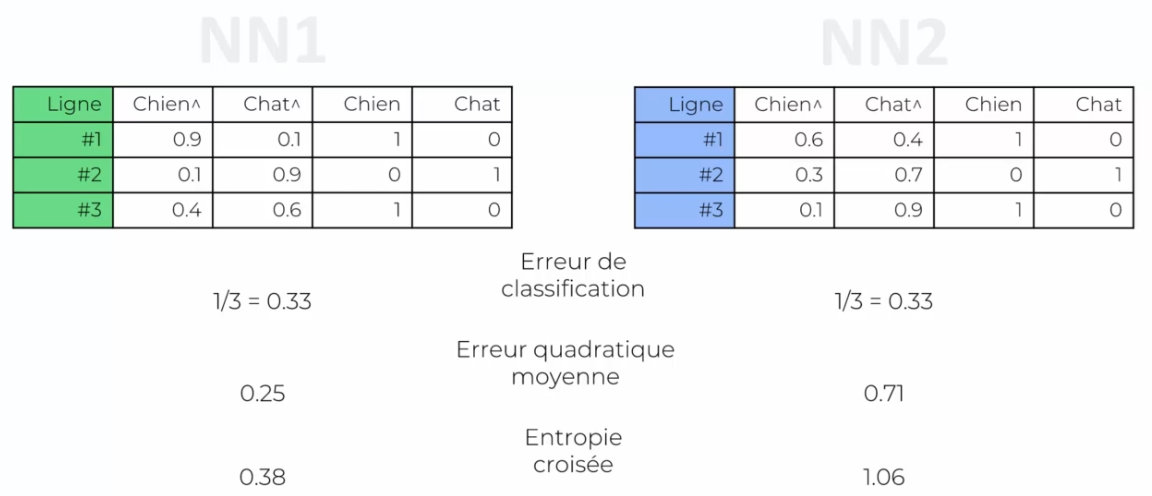
En revanche, l'entropie croisée prend le logarithme de l'erreur, ce qui signifie que les erreurs plus importantes ont un impact plus significatif sur la fonction de coût. Cela permet à l'algorithme du gradient de progresser plus rapidement vers une solution optimale. Ainsi, l'utilisation de l'entropie croisée peut améliorer la vitesse et la stabilité de l'apprentissage dans les réseaux de neurones à convolution.
Améliorer son réseau
L'ajout de couches de convolution peut permettre d'améliorer les résultats et de réduire le surapprentissage dans les réseaux de neurones à convolution. Pour cela, on peut ajouter une couche de convolution après le pooling, ce qui permet de réduire encore la taille de l'image. Après avoir ajouté la couche de convolution, il est également nécessaire d'ajouter une nouvelle couche de pooling. Il est important de noter que le pooling est toujours associé à une couche de convolution, et vice versa.
Une autre solution pour améliorer les résultats est d'augmenter la taille des images durant la convolution, afin d'acquérir plus de détails. Par exemple, on peut passer d'une taille initiale de 64x64 à 150x150.
Pour augmenter la précision du modèle, il est possible d'augmenter le nombre d'époques d'entraînement. Plus le modèle s'entraîne, plus il peut apprendre de motifs dans les données.
Enfin, pour ajouter plus de granularité dans le modèle, on peut ajouter des couches cachées. Cependant, il est important de noter que cela peut augmenter le risque de surapprentissage. Pour éviter cela, on peut utiliser la fonction dropout qui désactive aléatoirement certaines connexions entre les neurones à chaque itération d'entraînement, ce qui permet d'augmenter la robustesse du modèle.





