 Français
FrançaisIntroduction
Lorsque vous visitez des sites de commerce en ligne comme Amazon, des sites de streaming de films comme Netflix ou des applications de livraison de nourriture, ces sites recommandent des produits, des films ou des restaurants en fonction de ce qu'ils pensent que vous pourriez aimer. Pour de nombreuses entreprises, les systèmes de recommandation génèrent une grande partie de leurs ventes, ce qui rend l'économie ou la valeur générée par ces systèmes très importantes. Cet article examinera de plus près le fonctionnement des systèmes de recommandation, en utilisant l'application de la prédiction des notes de films comme exemple.
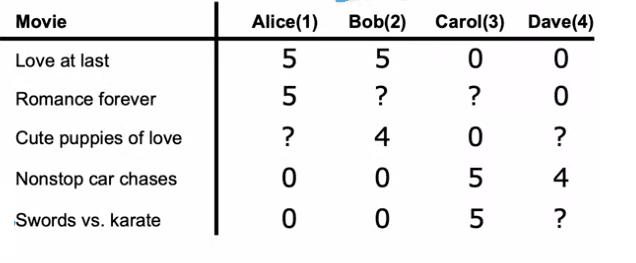
Dans un système de recommandation typique, il y a un ensemble d'utilisateurs et un ensemble de produits que les utilisateurs peuvent évaluer. Par exemple, nous avons quatre utilisateurs - Alice, Bob, Carol et Dave - et cinq films - Love at Last, Romance Forever, Cute Puppies of Love, Nonstop Car Chases et Sword versus Karate.
Nous pouvons dire que :
- Nu : est le nombre d'utilisateur
- Nm: est le nombre de films
Les utilisateurs évaluent les films sur une échelle de un à cinq étoiles et, dans cet exemple, nous avons des utilisateurs qui n'ont pas encore évalué certains films. Pour savoir quels utilisateurs ont évalué quels films, nous définissons r(i,j) comme 1 si l'utilisateur j a évalué le film i et 0 s'il ne l'a pas fait.
Une approche du problème des systèmes de recommandation consiste à prédire comment les utilisateurs évalueraient les films qu'ils n'ont pas encore évalués. Ainsi, le système peut recommander des films aux utilisateurs qu'ils sont plus susceptibles d'évaluer positivement. Cependant, pour faire ces prédictions, le système a besoin d'informations supplémentaires sur les films, telles que celles qui sont des films romantiques ou d'action. Nous développerons un algorithme pour faire ces prédictions dans la prochaine section, en supposant que nous avons accès à ces informations supplémentaires.
Il est important de noter que la même logique derrière les systèmes de recommandation peut s'appliquer à recommander n'importe quoi, des produits aux restaurants ou même des articles de médias sociaux. La notation utilisée dans cet article inclut nu pour désigner le nombre d'utilisateurs et nm pour désigner le nombre de films ou d'articles. De plus, y(i,j) est utilisé pour désigner l'évaluation donnée par l'utilisateur j pour le film i, uniquement si le film a été évalué.
Les features par item
Nous allons explorer comment développer un système de recommandation basé sur les caractéristiques des films. En particulier, nous examinerons un ensemble de données contenant quatre utilisateurs et cinq films, et nous supposerons que nous avons accès à deux caractéristiques pour chaque film : X1, qui mesure le degré de romantisme du film, et X2, qui mesure le degré d'action du film.
Commençons par définir la notation que nous utiliserons tout au long de l'article. Nous utiliserons r(i,j) pour indiquer si l'utilisateur j a noté le film i (r(i,j) = 1) ou non (r(i,j) = 0). Nous utiliserons y(i,j) pour indiquer la note donnée par l'utilisateur j pour le film i. Nous utiliserons w(j) et b(j) pour désigner les paramètres pour l'utilisateur j, que nous apprendrons à l'aide de notre système de recommandation. Enfin, nous utiliserons X(i) pour désigner le vecteur de caractéristiques pour le film i, qui se compose de X1 et X2.
Pour prédire comment un utilisateur j pourrait évaluer un film i en fonction des caractéristiques du film X(i), nous pouvons utiliser un modèle de régression linéaire. Plus précisément, nous pouvons prédire la note comme w(j).X(i)+b(j), où w(j) et b(j) sont les paramètres pour l'utilisateur j.
Pour apprendre les paramètres w(j) et b(j) pour chaque utilisateur, nous pouvons utiliser une fonction de coût qui mesure la différence entre la note prédite et la note réelle donnée par l'utilisateur. Nous utiliserons l'erreur quadratique moyenne comme fonction de coût, qui est définie comme suit :
J(w(j), b(j)) = (1/2m(j)) * sum(i:r(i,j)=1) [(w(j).X(i)+b(j) - y(i,j))^2] + (lambda/2m(j)) * sum(k=1 to n) (w(j,k))^2
Dans cette équation, m(j) est le nombre de films que l'utilisateur j a évalués, n est le nombre de caractéristiques (dans notre cas, n=2), et lambda est le paramètre de régularisation. Le premier terme dans l'équation mesure la différence entre la note prédite et la note réelle, sommée sur les films que l'utilisateur j a évalués. Le deuxième terme dans l'équation est le terme de régularisation, qui pénalise les valeurs de paramètre importantes pour éviter le surapprentissage.
Pour apprendre les paramètres pour tous les utilisateurs, nous pouvons utiliser un algorithme d'optimisation tel que la descente de gradient pour minimiser la fonction de coût pour tous les utilisateurs. Plus précisément, nous pouvons définir la fonction de coût globale comme suit :
J(w(1), b(1), ..., w(nu), b(nu)) = (1/nu) * sum(j=1 to nu) J(w(j), b(j))
Dans cette équation, nu est le nombre d'utilisateurs. Nous pouvons ensuite utiliser la descente de gradient ou un autre algorithme d'optimisation pour minimiser cette fonction de coût sur tous les paramètres w(j) et b(j).
Mise en place
La filtration collaborative est une technique populaire dans les systèmes de recommandation, utilisée pour faire des recommandations personnalisées en se basant sur le comportement des utilisateurs passés. Dans cet article, nous allons explorer comment la filtration collaborative peut être utilisée pour apprendre des caractéristiques à partir des évaluations des utilisateurs en utilisant la régression linéaire.
Hypothèses
Supposons que nous disposons d'un ensemble de données d'évaluations de films par des utilisateurs, où chaque film est associé à deux caractéristiques, x1 et x2. Nous pouvons utiliser la régression linéaire pour prédire les évaluations des films en fonction de ces caractéristiques. Cependant, que faire si nous n'avons pas ces caractéristiques pour un film particulier ? Dans ce cas, nous devons trouver des valeurs appropriées pour x1 et x2 à partir des données.
Apprentissage de caractéristiques
Supposons que nous avons appris les paramètres w et b pour les quatre utilisateurs de notre ensemble de données. Nous pouvons utiliser ces paramètres pour faire des estimations raisonnables des vecteurs de caractéristiques x1 et x2 pour les deux premiers films. Nous pouvons ensuite utiliser ces vecteurs de caractéristiques pour prédire les évaluations des autres utilisateurs et essayer de les faire correspondre aux évaluations réelles.
Pour apprendre les caractéristiques x1 et x2 pour un film spécifique, nous pouvons utiliser une fonction de coût qui minimise la différence au carré entre les évaluations prédites et réelles. Nous pouvons ajouter un terme de régularisation pour éviter le surajustement des données. Nous pouvons ensuite additionner cette fonction de coût sur tous les films pour apprendre les caractéristiques de tous les films de l'ensemble de données.
Formulation mathématique
La fonction de coût pour apprendre les caractéristiques x1 et x2 pour un film spécifique est :
J(x1,x2) = (1/2) Σj[r(i,j)=1] (w(j).x(i) - y(i,j))^2 + (λ/2) Σk(x(k,i))^2
où w(j) est le vecteur de paramètres pour l'utilisateur j, x(i) est le vecteur de caractéristiques pour le film i, y(i,j) est l'évaluation réelle de l'utilisateur j pour le film i, λ est le paramètre de régularisation, r(i,j) est une variable binaire indiquant si l'utilisateur j a évalué le film i ou non, et k représente l'indice de caractéristique (1 ou 2) pour le film i.
Le premier terme de la fonction de coût représente la différence au carré entre les évaluations prédites et réelles, sommées sur tous les utilisateurs ayant évalué le film. Le deuxième terme est le terme de régularisation L2, qui pénalise les grandes valeurs de caractéristiques pour éviter le surajustement.
Pour apprendre les caractéristiques x1 et x2 pour tous les films de l'ensemble de données, nous pouvons additionner la fonction de coût sur tous les films :
J = Σi J(x1(i),x2(i))
où J(x1(i),x2(i)) est la fonction de cout pour le film i
Optimisation
Pour minimiser la fonction de coût, nous pouvons utiliser la descente de gradient pour mettre à jour les paramètres w(j), x1(i) et x2(i) de manière itérative. Les dérivées partielles de la fonction de coût par rapport aux paramètres sont :
∂J/∂w(j) = Σi[r(i,j)=1] (w(j).x(i) - y(i,j))x(i) + λw(j)
∂J/∂x(k,i) = Σj[r(i,j)=1] (w(j).x(i) - y(i,j))w(j,k) + λx(k,i)
où w(j,k) est la k-ème composante du vecteur de paramètres w(j).
Nous pouvons mettre à jour les paramètres en utilisant les règles de mise à jour suivantes :
w(j) = w(j) - α∂J/∂w(j)
x(k,i) = x(k,i) - α∂J/∂x(k,i)
où α est le taux d'apprentissage.
Le filtrage collaboratif est une technique puissante pour faire des recommandations personnalisées, surtout lorsque nous n'avons pas d'informations complètes sur les éléments de notre ensemble de données. En apprenant des caractéristiques à partir des évaluations des utilisateurs en utilisant la régression linéaire, nous pouvons faire des prédictions précises pour de nouveaux éléments basées sur le comportement passé des utilisateurs. La fonction de coût que nous avons dérivée dans cet article peut être minimisée en utilisant la descente de gradient pour obtenir les valeurs optimales des paramètres w et x pour notre modèle. Le filtrage collaboratif a de nombreuses applications dans le commerce électronique, les médias sociaux et d'autres domaines où les recommandations personnalisées peuvent aider à améliorer l'expérience et l'engagement des utilisateurs.
Binary labels
Les systèmes de recommandation ou les algorithmes de filtrage collaboratif sont largement utilisés dans de nombreuses applications pour suggérer des articles ou des produits aux utilisateurs en fonction de leur comportement ou de leurs préférences passées. Dans la plupart des cas, les utilisateurs fournissent des évaluations ou des avis qui reflètent leur niveau de satisfaction par rapport à l'article. Cependant, il existe des situations où des étiquettes binaires sont utilisées au lieu des évaluations en étoiles pour indiquer si l'utilisateur a aimé ou n'a pas aimé l'article. Dans cet article, nous explorerons comment les algorithmes de filtrage collaboratif peuvent être généralisés pour fonctionner avec des étiquettes binaires et fournirons quelques astuces de mise en œuvre pour de meilleures performances.
Étiquettes binaires dans le filtrage collaboratif
Dans le filtrage collaboratif, des étiquettes binaires sont utilisées pour indiquer si l'utilisateur a aimé ou s'est engagé avec un article. L'étiquette "1" indique que l'utilisateur s'est engagé avec l'article d'une certaine manière, tel que regarder un film jusqu'à la fin, cliquer sur le bouton "j'aime" ou "favori", ou passer au moins 30 secondes sur l'article. L'étiquette "0" signifie que l'utilisateur ne s'est pas engagé avec l'article, tandis que l'étiquette "?" indique que l'utilisateur n'a pas encore vu l'article.
Généralisation des algorithmes de filtrage collaboratif
Pour généraliser l'algorithme de filtrage collaboratif pour les étiquettes binaires, nous devons modifier la fonction de coût et le modèle de prédiction. Au lieu du modèle de régression linéaire utilisé dans l'algorithme traditionnel, nous utilisons la fonction logistique pour prédire la probabilité que l'utilisateur s'engage avec l'article. La fonction logistique mappe toute entrée réelle à une valeur entre 0 et 1, qui peut être interprétée comme la probabilité de la sortie étant "1". Le modèle de prédiction modifié est donné par :
g(z) = 1 / (1 + e^(-z))
où z = w_j * x_i + b_j est le produit scalaire du vecteur de poids et du vecteur de caractéristiques de l'article i, et b_j est le terme de biais pour l'utilisateur j.
La fonction de coût utilisée dans l'algorithme de filtrage collaboratif est également modifiée pour la fonction de coût de la croix-entropie binaire, qui est couramment utilisée dans les modèles de régression logistique. La fonction de coût modifiée est donnée par :
J = -1/m * sum( y_ij * log(f(x_ij)) + (1 - y_ij) * log(1 - f(x_ij)))
où y_ij est l'étiquette binaire pour l'utilisateur j et l'article i, et f(x_ij) est la probabilité prédite de l'utilisateur j s'engageant avec l'article i.
Astuces de mise en œuvre pour de meilleures performances Bien que la généralisation des algorithmes de filtrage collaboratif pour les étiquettes binaires ouvre de nombreuses nouvelles applications, il existe des astuces de mise en œuvre qui peuvent rendre l'algorithme plus rapide et plus efficace. Voici quelques astuces :
Utiliser des matrices clairsemées : Étant donné que la matrice de notation est généralement très clairsemée, l'utilisation de matrices clairsemées peut économiser une quantité significative de mémoire et de temps de calcul.
Utiliser la régularisation : La régularisation peut aider à éviter le surapprentissage et à améliorer les performances de généralisation de l'algorithme. La régularisation L1 ou L2 peut être utilisée pour réduire les poids du modèle.
Utiliser la descente de gradient par mini-batch : La descente de gradient par mini-batch peut accélérer le processus d'entraînement en mettant à jour les poids sur la base d'un petit sous-ensemble des données d'entraînement à la fois.
Utiliser l'arrêt prématuré : L'arrêt prématuré peut empêcher le modèle de surapprendre les données d'entraînement en arrêtant le processus d'entraînement lorsque l'erreur de validation commence à augmenter.
Normalisation des moyennes
Lors de la construction d'un système de recommandation, il est courant d'utiliser des évaluations numériques, telles qu'une échelle de zéro à cinq étoiles, pour représenter les préférences des utilisateurs pour différents éléments. Cependant, si vous souhaitez que votre algorithme fonctionne plus efficacement et prédise avec précision les évaluations pour les nouveaux utilisateurs qui n'ont pas encore évalué de nombreux éléments, la normalisation des moyennes peut être une technique efficace.
La normalisation des moyennes consiste à ajuster les évaluations pour chaque élément afin qu'elles aient une valeur moyenne cohérente. Pour illustrer cela, prenons un ensemble de données avec cinq films et quatre utilisateurs qui les ont évalués, ainsi qu'un cinquième utilisateur nommé Eve qui n'a pas encore évalué de films. Nous pouvons représenter ces données dans une matrice, où les lignes correspondent aux utilisateurs et les colonnes correspondent aux films. La matrice aura certaines valeurs manquantes car Eve n'a pas encore évalué de films.
Y =
[ 5 5 0 0 ? ]
[ 5 ? 0 ? 2 ]
[ ? 4 0 0 ? ]
[ 0 0 5 5 0 ]
[ ? ? ? ? ? ]
Dans cette matrice, les valeurs manquantes sont représentées par des points d'interrogation. Nous voulons prédire les notes pour l'utilisateur 5, Eve.
Pour effectuer la normalisation des moyennes, nous calculons d'abord la note moyenne attribuée à chaque film. Appelons ce vecteur μ :
μ = [ 2.5, 2.5, 2.0, 2.25, 1.25 ]
Ensuite, nous soustrayons la note moyenne pour chaque film des notes originales données par chaque utilisateur. Ce nouvel ensemble de notes devient nos données d'entrée pour l'algorithme de recommandation. En soustrayant la note moyenne pour chaque film, nous nous assurons que nos prédictions ne seront pas biaisées vers des films très bien notés. Cela nous donne une nouvelle matrice Y_norm :
Y_norm =
[ 2.5 2.5 -2.5 -2.5 ? ]
[ 2.5 ? -2.5 ? -0.25 ]
[ ? 2.0 -2.0 -2.0 ? ]
[-2.25 -2.25 2.75 2.75 -2.25 ]
[ ? ? ? ? ? ]
Une fois que nous avons ajusté les notes en utilisant la normalisation des moyennes, nous pouvons utiliser le même algorithme de filtrage collaboratif qu'auparavant pour prédire les notes pour de nouveaux utilisateurs comme Eve. L'algorithme apprend des paramètres w(j), b(j) et x(i) pour prédire la note pour l'utilisateur j sur le film i. Comme nous avons soustrait la note moyenne pour chaque film, nous devons la rajouter pour nous assurer que nos prédictions se situent dans l'échelle de notation (0 à 5 étoiles, par exemple) :
w(5) = [ 0, 0, 0, 0, 0 ]
b(5) = 0
Pour faire une prédiction pour le film 1, nous prenons le produit scalaire du vecteur de poids w(5) et du vecteur de caractéristiques x(1) pour le film 1, et nous ajoutons le terme de biais b(5) :
w(5).x(1) + b(5) = 0 + 0 = 0
Mais parce que nous avons soustrait la note moyenne pour le film 1 pendant la normalisation des moyennes, nous devons l'ajouter de nouveau pour obtenir la prédiction réelle :
w(5).x(1) + b(5) + μ(1) = 0 + 0 + 2.5 = 2.5
Nous prédisons donc qu'Eve évaluera le film 1 avec 2,5 étoiles. Nous pouvons faire des prédictions similaires pour les autres films. Notez que parce que nous avons initialisé les paramètres pour l'utilisateur 5 à zéro, nous prédisons qu'Eve évaluera tous les films de la même manière, c'est-à-dire avec la note moyenne de tous les utilisateurs.
La normalisation des moyennes présente plusieurs avantages. Premièrement, elle rend l'algorithme plus précis pour les nouveaux utilisateurs qui n'ont pas encore évalué de nombreux éléments. Sans la normalisation des moyennes, l'algorithme pourrait prédire que les nouveaux utilisateurs évalueront tous les éléments très bas ou très haut, en fonction de la distribution globale des notes. En soustrayant la note moyenne pour chaque film, nous pouvons faire des prédictions plus raisonnables pour les nouveaux utilisateurs.
Deuxièmement, la normalisation des moyennes peut également rendre l'algorithme plus rapide. En centrant les notes autour de zéro, nous réduisons le nombre de paramètres que l'algorithme doit apprendre, ce qui peut accélérer le processus d'entraînement.
En pratique, il existe deux façons d'effectuer la normalisation des moyennes : en normalisant les lignes ou en normalisant les colonnes de la matrice. La normalisation des lignes peut être plus utile lorsqu'il s'agit de nouveaux utilisateurs qui n'ont pas encore évalué de nombreux éléments, tandis que la normalisation des colonnes peut être plus utile lorsqu'il s'agit de nouveaux éléments qui n'ont pas encore été évalués. Cependant, pour la plupart des systèmes de recommandation, normaliser uniquement les lignes devrait fonctionner correctement.
En fin de compte, la normalisation des moyennes est une technique efficace pour améliorer la précision et l'efficacité d'un système de recommandation, en particulier pour les nouveaux utilisateurs qui n'ont pas encore évalué de nombreux éléments. En ajustant les évaluations pour avoir une valeur moyenne cohérente, nous pouvons faire des prédictions plus raisonnables et accélérer le processus d'entraînement.
Trouvé des items liés
Le filtrage collaboratif est une approche utilisée dans les systèmes de recommandation qui consiste à apprendre des vecteurs de caractéristiques X pour chaque élément, comme des films, qui sont recommandés aux utilisateurs. Les vecteurs de caractéristiques peuvent aider à identifier des éléments similaires et fournir des recommandations personnalisées aux utilisateurs.
Pour apprendre les vecteurs de caractéristiques X, nous pouvons utiliser une approche de factorisation de matrice qui minimise la somme des carrés des erreurs entre la note prédite et la note réelle. Nous pouvons définir une matrice R, où R[i,j] représente la note que l'utilisateur j a donnée à l'élément i, et une matrice X, où X[i,:] représente le vecteur de caractéristiques pour l'élément i. Nous introduisons également une matrice de paramètres Theta, où Theta[j,:] représente le vecteur de paramètres pour l'utilisateur j. Nous pouvons ensuite utiliser le problème d'optimisation suivant :
minimiser : (1/2) * somme((R[i,j] - X[i,:] * Theta[j,:].T)^2) + (lambda/2) * somme(X[i,:]^2) + (lambda/2) * somme(Theta[j,:]^2)
sous réserve que : Theta[j,:] représente le vecteur de paramètres pour l'utilisateur j lambda représente un paramètre de régularisation
Le problème d'optimisation vise à apprendre les vecteurs de caractéristiques X et les vecteurs de paramètres Theta en minimisant la somme des carrés des erreurs entre la note prédite et la note réelle. Nous ajoutons des termes de régularisation pour éviter le surajustement.
Pour trouver des éléments similaires, nous pouvons calculer la distance au carré entre les vecteurs de caractéristiques de deux éléments i et k à l'aide de l'équation suivante :
distance = somme((X[i,:] - X[k,:])^2)
Si nous voulons trouver les k éléments les plus similaires à l'élément i, nous pouvons calculer la distance entre i et tous les autres éléments, trier les distances par ordre croissant et sélectionner les k meilleurs éléments.
Par exemple, si nous avons une matrice R qui représente les notes données par les utilisateurs aux films, et une matrice X qui représente les vecteurs de caractéristiques des films, nous pouvons utiliser l'approche de filtrage collaboratif pour identifier des films similaires. Supposons que nous voulons trouver les cinq films les plus similaires à un film donné i. Nous pouvons calculer la distance entre le film i et tous les autres films en utilisant l'équation ci-dessus, trier les distances par ordre croissant et sélectionner les cinq meilleurs films.
Le filtrage collaboratif présente certaines limites, telles que le problème de démarrage à froid, où les nouveaux éléments ou les nouveaux utilisateurs ont des données limitées pour fournir des recommandations précises. De plus, le filtrage collaboratif ne prend pas en compte les informations supplémentaires, telles que le genre d'un film ou les informations démographiques d'un utilisateur. Cependant, les algorithmes de filtrage basés sur le contenu peuvent résoudre ces limitations en incorporant des informations supplémentaires.
Conclusion
En conclusion, la généralisation des algorithmes de filtrage collaboratif pour les étiquettes binaires peut considérablement étendre l'ensemble des applications dans lesquelles ces algorithmes peuvent être utilisés. En modifiant la fonction de coût et le modèle de prédiction, nous pouvons prédire la probabilité qu'un utilisateur s'engage avec un élément et recommander des éléments aux utilisateurs en fonction de ces prédictions. L'utilisation d'astuces d'implémentation telles que des matrices clairsemées, la régularisation, la descente de gradient par mini-batch et l'arrêt prématuré peut également améliorer les performances de l'algorithme. À mesure que l'utilisation des étiquettes binaires devient de plus en plus courante dans de nombreuses applications en ligne, il est important de comprendre comment adapter l'algorithme de filtrage collaboratif à ce contexte. Nous espérons que cet article fournira une introduction utile à ce sujet et encouragera une exploration et un développement ultérieurs de ces algorithmes.





