 Français
FrançaisIntroduction
En apprentissage supervisé, nous disposons d'un ensemble de données qui comprend à la fois les caractéristiques d'entrée x et les sorties cibles y. Cela nous permet de mettre en place un algorithme pour apprendre une limite de décision et prédire la sortie cible y. Cependant, en apprentissage non supervisé, nous ne disposons que d'un ensemble de données avec des caractéristiques d'entrée x, mais sans les sorties cibles y. Par conséquent, nous ne pouvons pas dire à l'algorithme quelle est la "bonne réponse" et nous lui demandons plutôt de trouver des structures ou des motifs intéressants dans les données.
Un type populaire d'algorithme d'apprentissage non supervisé est le regroupement (ou clustering en anglais), qui recherche des groupes de points similaires. L'objectif du regroupement est de regrouper les données en clusters qui partagent certaines caractéristiques communes. Par exemple, le regroupement peut être utilisé pour regrouper des articles de presse similaires ou pour regrouper des individus présentant des traits génétiques similaires.
Il existe de nombreuses applications du regroupement dans différents domaines, tels que l'astronomie et l'exploration spatiale. Les astronomes utilisent le regroupement pour regrouper des corps célestes afin de comprendre la structure des galaxies ou pour identifier des structures cohérentes dans l'espace. Une autre application du regroupement est la segmentation de marché, où les entreprises regroupent les clients ayant des habitudes d'achat similaires pour créer des campagnes de marketing ciblées.
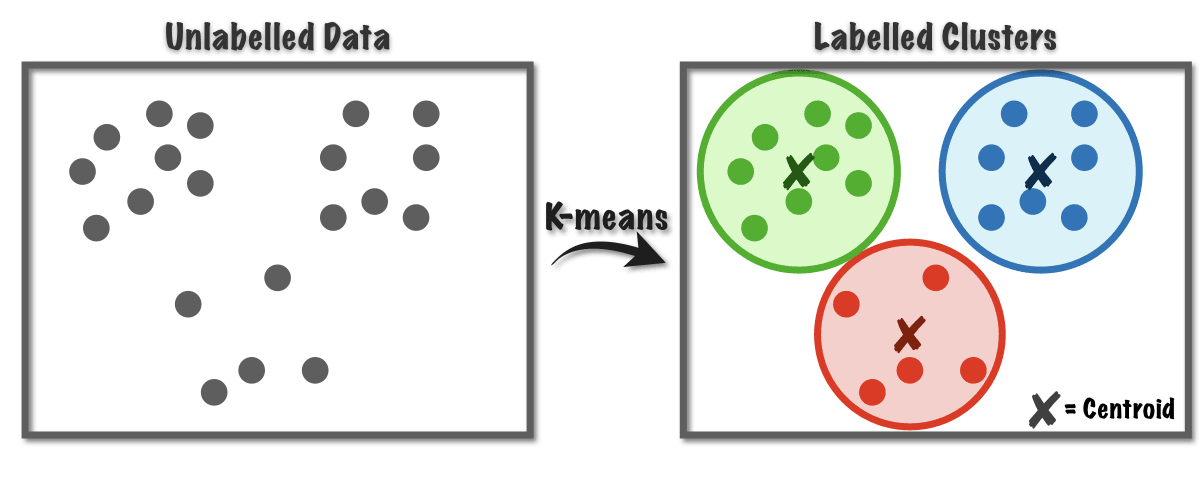
L'algorithme de regroupement le plus couramment utilisé est l'algorithme k-means, qui consiste à trouver un ensemble de k centroides qui définissent les clusters. L'algorithme attribue chaque point de données au centroïde le plus proche et recalcule les centroides jusqu'à la convergence. Dans la prochaine section, nous explorerons l'algorithme k-means et son fonctionnement.
Le regroupement est un algorithme d'apprentissage non supervisé populaire qui peut être utilisé dans différents domaines, notamment la segmentation de marché, l'analyse d'ADN et l'astronomie. L'algorithme k-means est un algorithme de regroupement largement utilisé qui peut aider à identifier des clusters de données avec des caractéristiques communes.
K-means intuition
Pour expliquer le fonctionnement de l'algorithme de regroupement (ou clustering) K-means, voici des exemples mathématiques.
Nous avons un ensemble de données contenant 30 exemples d'entraînement non étiquetés. L'objectif est d'exécuter K-means sur cet ensemble de données. La première étape de l'algorithme de K-means consiste à prendre une supposition aléatoire sur les centres des deux clusters que vous souhaitez trouver. Dans cet exemple, nous essayons de trouver deux clusters. Plus tard, nous verrons comment décider du nombre de clusters à trouver. Mais pour commencer, K-means choisit deux points au hasard, représentés ici par une croix rouge et une croix bleue, pour être les centres de deux clusters différents. C'est une supposition aléatoire et elle n'est pas particulièrement bonne, mais c'est un début.
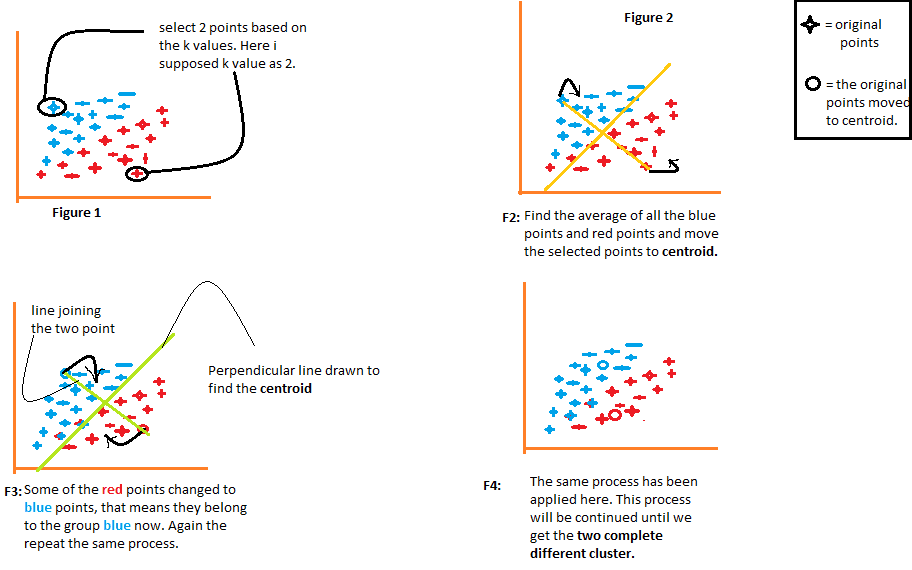
K-means va ensuite effectuer deux actions différentes en boucle. La première action est d'attribuer chaque point à un centroïde de cluster, et la seconde est de déplacer les centroïdes de cluster. Pour attribuer chaque point à un centroïde de cluster, K-means va d'abord déterminer pour chaque point s'il est plus proche de la croix rouge ou de la croix bleue. Ensuite, il va associer chaque point au centroïde de cluster le plus proche. Les points associés à la croix rouge sont peints en rouge et ceux associés à la croix bleue sont peints en bleu. Cela constitue la première des deux étapes que K-means effectue en boucle.
La deuxième étape consiste à déplacer les centres de cluster en calculant la moyenne de tous les points associés à chaque centroïde de cluster. Les centres de cluster sont déplacés vers les nouvelles positions moyennes, et K-means va répéter les deux étapes jusqu'à ce qu'il n'y ait plus de changements. Dans l'exemple, K-means trouve que les points en haut correspondent à un cluster et les points en bas à un autre cluster.
K-means est un algorithme de regroupement qui utilise deux étapes pour regrouper les données. La première étape est d'attribuer chaque point à un centroïde de cluster, et la seconde est de déplacer les centres de cluster en calculant la moyenne de tous les points associés à chaque centroïde. En répétant ces deux étapes, K-means peut trouver des clusters dans les données.
L'algorithme
L'algorithme de clustering K-means implique d'initialiser de manière aléatoire K centroïdes de cluster, qui sont des vecteurs de la même dimension que les exemples d'entraînement. K-means répète ensuite deux étapes: affecter chaque exemple d'entraînement au centroïde de cluster le plus proche et mettre à jour les centroïdes de cluster pour qu'ils soient la moyenne des points assignés à chaque cluster. L'algorithme itère jusqu'à la convergence, qui se produit lorsque les affectations de cluster ne changent plus ou que le changement est inférieur à un certain seuil.
La distance entre un exemple d'entraînement et un centroïde de cluster est calculée en utilisant la norme L2, qui peut être minimisée pour trouver l'indice du centroïde de cluster le plus proche. Pour simplifier le calcul, la distance au carré est souvent utilisée à la place. Si un cluster n'a aucun exemple d'entraînement qui lui est assigné, il est généralement éliminé.
Bien que K-means soit souvent utilisé pour des ensembles de données avec des clusters bien séparés, il peut également être appliqué à des ensembles de données où les clusters ne sont pas clairement séparés. Par exemple, K-means peut être utilisé pour regrouper des personnes par taille et poids afin de déterminer la taille optimale pour des t-shirts.
L'algorithme K-means peut être considéré comme optimisant une fonction de coût spécifique, qui mesure la somme des distances au carré entre chaque exemple d'entraînement et son centroïde de cluster assigné. En minimisant cette fonction de coût, K-means est capable de trouver un regroupement des données qui est relativement serré et compact. L'algorithme converge généralement en pratique, bien qu'il soit possible qu'il reste coincé dans des optima locaux ou qu'il prenne beaucoup de temps pour converger pour de grands ensembles de données.
Optimisation
Cette fonction de coût, J, est une fonction des affectations de points aux clusters et des emplacements des centroïdes de cluster. Pour comprendre la fonction de coût, nous utilisons la notation CI pour représenter l'index du cluster auquel l'exemple d'entraînement XI est actuellement assigné, et mu indice CI pour représenter l'emplacement du centroïde du cluster auquel XI a été assigné. La fonction de coût J est définie comme la moyenne de la distance au carré entre chaque exemple d'entraînement XI et le centroïde mu indice CI auquel il a été assigné. L'algorithme K-means fonctionne en mettant à jour les affectations de points aux clusters et les emplacements des centroïdes de cluster afin de minimiser J.

L'algorithme K-means comporte deux étapes principales. Dans la première étape, il assigne chaque exemple d'entraînement au centroïde le plus proche afin de minimiser J tout en maintenant les emplacements des centroïdes fixes. Dans la deuxième étape, il déplace les centroïdes vers la moyenne des points qui leur sont assignés afin de minimiser J tout en maintenant les affectations de points aux clusters fixes.
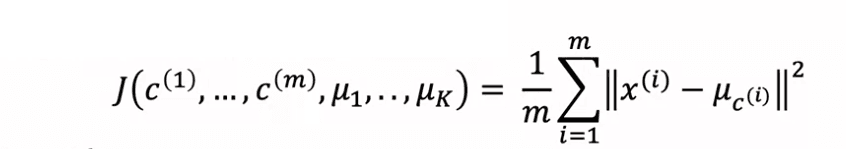
En optimisant la fonction de coût J, l'algorithme K-means est garanti de converger à chaque itération, ce qui signifie que la fonction de coût de distorsion devrait diminuer ou rester la même. Si la fonction de coût de distorsion augmente, cela signifie qu'il y a un bug dans le code. Pour tester si l'algorithme a convergé, nous pouvons vérifier si la fonction de coût a cessé de diminuer. Si la fonction de coût diminue très lentement, nous pouvons choisir d'arrêter l'algorithme car la convergence est suffisante.
La fonction de coût J peut également être utilisée pour tirer parti de plusieurs initialisations aléatoires des centroïdes de cluster. En exécutant l'algorithme K-means avec différentes initialisations aléatoires, nous pouvons comparer les fonctions de coût résultantes pour choisir la meilleure initialisation.
Initialiser l'algorithme

Lors de l'exécution de K-means, le nombre de centroïdes de cluster K doit être inférieur ou égal au nombre d'exemples d'entraînement m. Sinon, il n'y aura pas suffisamment d'exemples d'entraînement pour avoir au moins un exemple d'entraînement par centroïde de cluster.
La méthode la plus courante pour choisir les centroïdes de cluster est de sélectionner au hasard K exemples d'entraînement. Cette méthode initialise les centroïdes de cluster µ K pour être égaux à ces K exemples d'entraînement. L'algorithme est ensuite exécuté jusqu'à convergence, donnant un choix d'affectations de cluster et de centroïdes de cluster.
Cependant, il existe une chance que l'initialisation des centroïdes de cluster puisse donner des optima locaux suboptimaux, ce qui peut entraîner un regroupement médiocre des données. Pour résoudre ce problème, il est recommandé d'exécuter K-means avec de multiples initialisations aléatoires pour lui donner une meilleure chance de trouver le meilleur optimum local.
Pour mettre en œuvre cela, on peut exécuter K-means plusieurs fois en utilisant différentes initialisations aléatoires, telles que 50 à 1000 fois. Après cela, l'ensemble de clusters qui donne la distorsion la plus faible (fonction de coût) est sélectionné. Cette approche peut souvent donner un résultat bien meilleur que si seule une initialisation aléatoire avait été utilisée.
L'algorithme K-means consiste à partitionner les points de données en K clusters distincts. L'initialisation aléatoire est la méthode la plus courante pour choisir les centroïdes de cluster, mais l'exécution de l'algorithme avec de multiples initialisations aléatoires peut souvent conduire à un regroupement des données plus efficace.
Choisir le nombre de cluster
Dans le contexte du clustering, K est le nombre de clusters que vous voulez créer à partir d'un ensemble de données donné. Cependant, déterminer la valeur appropriée de K est souvent ambigu et subjectif. Par exemple, différentes personnes peuvent voir des nombres différents de clusters lorsqu'elles regardent le même ensemble de données.
Pour résoudre ce problème, plusieurs techniques peuvent vous aider à choisir la valeur de K. Une de ces techniques est appelée la méthode du coude. L'idée est de faire fonctionner l'algorithme K-means avec plusieurs valeurs de K et de tracer la fonction de coût ou de distorsion J en fonction du nombre de clusters. Lorsque vous avez peu de clusters, disons un seul cluster, la fonction de coût sera élevée. En augmentant le nombre de clusters, la fonction de coût diminuera. Si la courbe ressemble au coude d'un bras, avec une diminution rapide suivie d'une diminution plus graduelle, la valeur de K qui correspond au coude est généralement choisie comme le nombre approprié de clusters.
Cependant, dans la pratique, la méthode du coude n'est pas toujours la meilleure approche. Les fonctions de coût pour certains ensembles de données peuvent ne pas avoir de coude clair. Dans de tels cas, il est souvent préférable d'évaluer K-means en fonction de ses performances pour l'application prévue en aval. Par exemple, si vous utilisez K-means pour regrouper un ensemble de données de tailles de t-shirts, vous voudrez peut-être tenir compte du compromis entre l'ajustement des t-shirts (en fonction de la présence de trois ou cinq tailles) et les coûts supplémentaires associés à la fabrication et à l'expédition de cinq types de t-shirts au lieu de trois. Dans ce cas, vous pouvez exécuter K-means avec K égal à 3 et K égal à 5, puis comparer les deux solutions en fonction du compromis entre l'ajustement et le coût. Si K=3 alors c(i) peut etre : 1,2 ou 3
Un autre exemple d'application de K-means est la compression d'images. Dans ce cas, il y a un compromis entre la qualité de l'image compressée et la quantité d'espace économisé. En ajustant la valeur de K, vous pouvez décider manuellement de l'équilibre optimal entre ces deux facteurs.
Bien que le choix de la bonne valeur de K pour le clustering puisse être ambigu, il existe plusieurs méthodes pour prendre une décision éclairée, telles que la méthode du coude. En fin de compte, le meilleur choix de K dépend de l'application spécifique et des compromis impliqués.





