 Français
FrançaisLa machine de Boltzmann
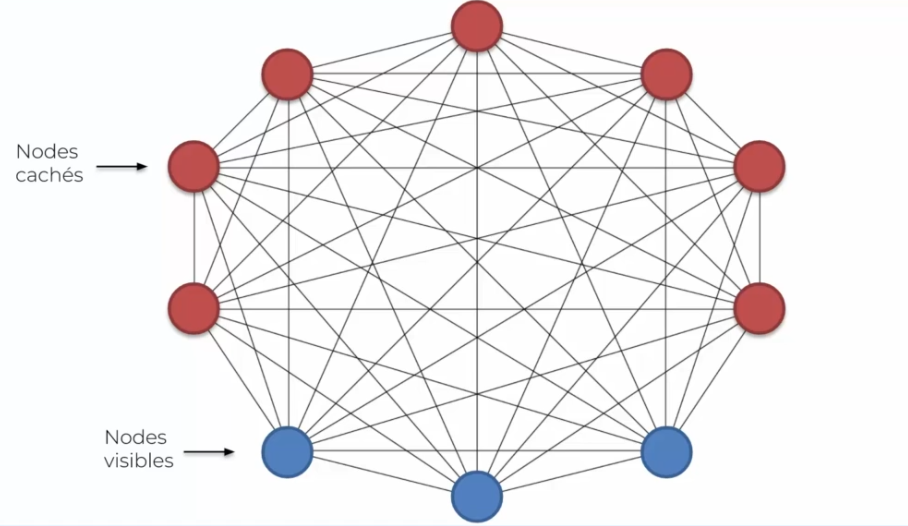
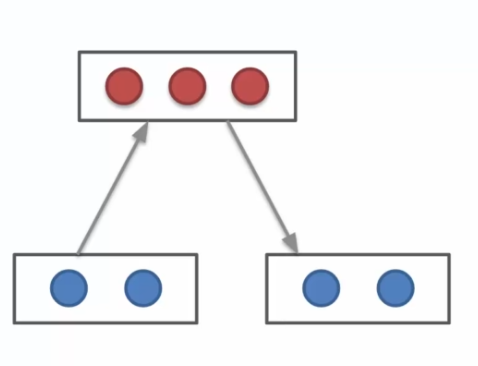
L'une des caractéristiques de ces machines, et qui fait son unicité, est qu'une machine de Boltzmann n'a pas de direction. Ce que l'on remarqué dans la figure plus haute, c'est que tout les neurones sont connectés ensemble. Les neurones d'entrées sont connectés entre eux, tout comme les cachés sont connectés entre eux. On remarque aussi que chaque neurones d'entrées se connecte aussi à chaque neurone cachés. C'est ce qui caractérise la machine de Boltzmann !
Mais par où commencé pour bien comprendre ?
Commençons par les nodes visibles (en bleu) qui bizarrement se connectent entre eux, alors que normalement dans les réseaux de neurones que l'on a observés précédemment, ceux-ci étaient connectés uniquement à des neurones cachés. De plus ces neurones d'entrées, sont des données en entrée qui représentent des données donc quel est l'intérêt de connecter ces données entre elle ? Et bien les machines de Boltzmann sont différentes, elles ne se limitent pas aux données d'entrées, mais elles en génèrent elles mêmes. Un autre point important est que nous faisons une distinction entre les neurones d'entrées et cachées, là où la machine de Boltzmann elle n'en fait pas. Autrement dit, une machine de Boltzmann est capable de créer des états de manière aléatoire, et d'observer l'impact que ces états sur le système pour en apprendre plus. Cette observation est basé sur nos données en entrée, en effet elle va utiliser ces données pour ajuster ses poids. Ces données sont considérées comme les données d'un état stable. On obtient donc sur le long terme, une copie de cette machine, qui a testé plusieurs états et comprends la normalité. Retenons bien ce mot normalité, basé sur nos entrées, qui permettra à la machine de Boltzmann de détecter une anormalité (modèle non supervisé). C'est son unique but, car la machine n'a que des données quand tout va bien et quand on aura des divergences le modèle pourra rapidement le repéré.
Donc c'est normal de ne pas avoir de sortie, car on a pas ici besoin de prédiction, mais d'une alerte en cas d'anormalité.
Le modèle à énergie
On peut représenter mathématiquement la machine de Boltzmann comme ceci :
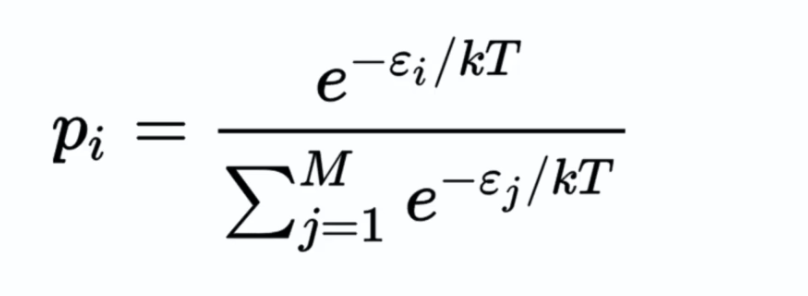
Le modèle à energie désigne une probabilité sur un état dont l'énergie est la plus faible : une goute d'encre dans l'eau ne se propage pas sous forme d'étoile par exemple, dans ce cas l'énergie est élevé car cet état est peu probable et demandera plus d'énergie à être réalisé pour simuler l'état qui n'existe pas. Ce processus permet d'évaluer l'énergie pour chaque état ou simplement les poids sur chaque sinapses, afin de trouver l'état avec l'énergie la plus faible.
On a donc une série d'état, par exemple la diffusion du gaz dans l'air :
- Energie faible : l'état est que le gaz se diffuse dans toute la pièce, c'est un état dit courant
- Energie forte: l'état est que le gaz stagne dans le coin d'une pièce, c'est un état presque improbable
La machine de Boltzmann restreint
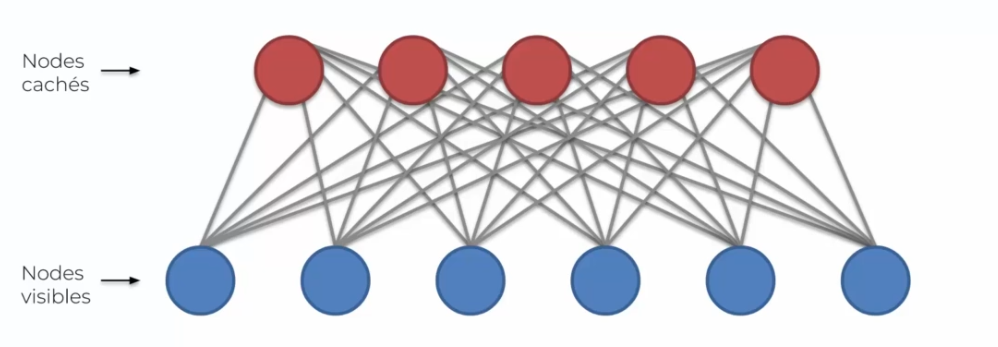
On remarque qu'à la différence de la machine de Boltzmann, vue précédemment, que tous les neurones ne sont plus connectés entre eux. Mais nous n'avons toujours pas de direction, ce qui est l'une des caractéristique de ce modèle. Ici on veut que le système s'adapte à nos données et non plus qu'elle simule des données comme expliqué plus haut.
En entrée l'on pourrait avoir des films :
- Inception
- Batman
- Star wars
- Le seigneur des anneaux
En sortie l'on pourrait avoir des genres :
- Sciences fictions
- Heroique
- Fantastique
Voir des acteurs ;
- Christian Bale
Voir même des réalisateurs :
- Nolan
- George Lucas
Les neurones ne savent pas ce qu'ils représentent, c'est nous qui mettons des noms dessus. L'apprentissage commence en donnant des lignes une par une :
| Movie 1 | Movie 2 | Movie 3 | Movie 4 | Movie 5 | Movie 6 | |
|---|---|---|---|---|---|---|
| User 1 | 1 | 0 | 1 | 1 | 1 | |
| User 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| User 3 | 1 | 1 | 0 | 0 | ||
| User 4 | 1 | 0 | 1 | 1 | 0 | 1 |
| User 5 | 0 | 1 | 1 | 1 | ||
| User 6 | 0 | 0 | 0 | 0 | 1 | |
| User 7 | 1 | 0 | 1 | 1 | 0 | 1 |
| User 8 | 0 | 1 | 1 | 0 | 1 | |
| User 9 | 0 | 1 | 1 | 1 | 1 | |
| User 10 | 1 | 0 | 0 | 0 |
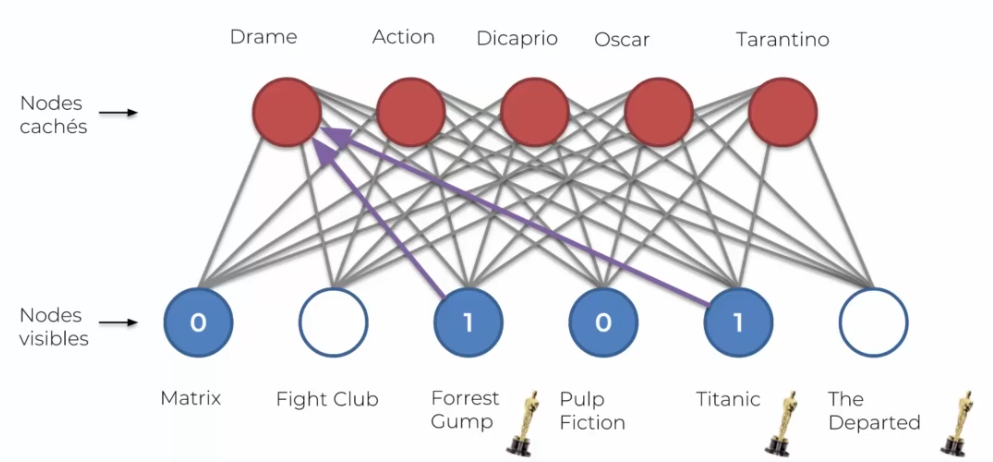
L'avis de l'utilisateur est caractérisé par 0 ou 1 si l'on a aimé, et rien si on ne l'a pas vu. Ainsi on peut avoir des préférences qui vont ensemble : j'ai bien aimé le film 3 et 4 donc peut-être que j'aimerais le film 6. La machine de Boltzmann va identifier cette relation et créé un noeud pour cette préfence, par exemple le genre 1 (toujours une nomination humaine et non machine). On peut représenté l'exécution via ce schéma :
Divergence contrastive
C'est l'algorithme qui permet à notre machine d'apprendre. Dans la plupart des réseaux on avait de la retropropagation que l'on n'a pas avec Boltzmann. Alors comment ca marche ?
- On a des réseaux cachés
- On a des réseaux en entrée
- Au départ chaque neurone commence avec des poids aléatoires
Commençons:
- La première étape est de calculer les nodes cachés
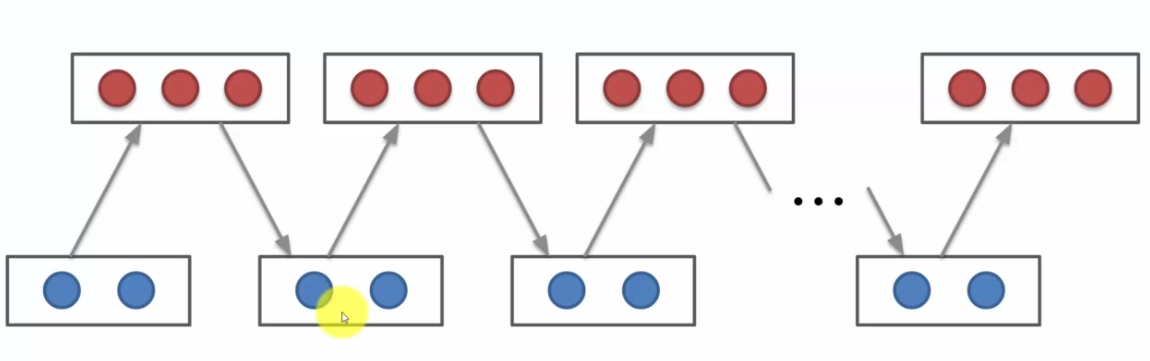
- Une fois calculée, on va réutiliser les mêmes poids pour calculé les node d'entrées, Par contre les nodes qui seront recalculés ne seront plus les mêmes qu'au début ! En effet vu que tout les neurones permettent le recalculent du cout, cela entraine une divervenge sur le node
- On réitère les étapes 1 et 2 jusqu'à la fin, on dit alors que l'on fait un échantillonnage. On alors alors une convergence de l'algorithme, qui permettra au modèle de créer exactement nos données en entrée pour simuler les différents états du système.
Maintenant comment se passe cette mise à jour des poids :
- On va créé en entrée notre gradient
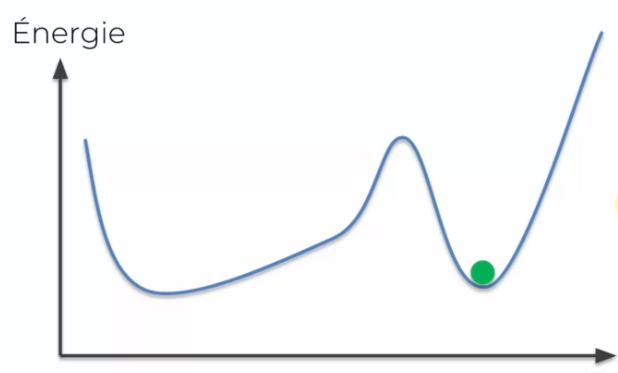
- Ce gradient sera égale à notre énergie au moment de départ (notre point vert) moins notre énergie à la fin
- Peu à peu l'energie va descendre jusqu'à atteindre l'état le plus bas en énergie
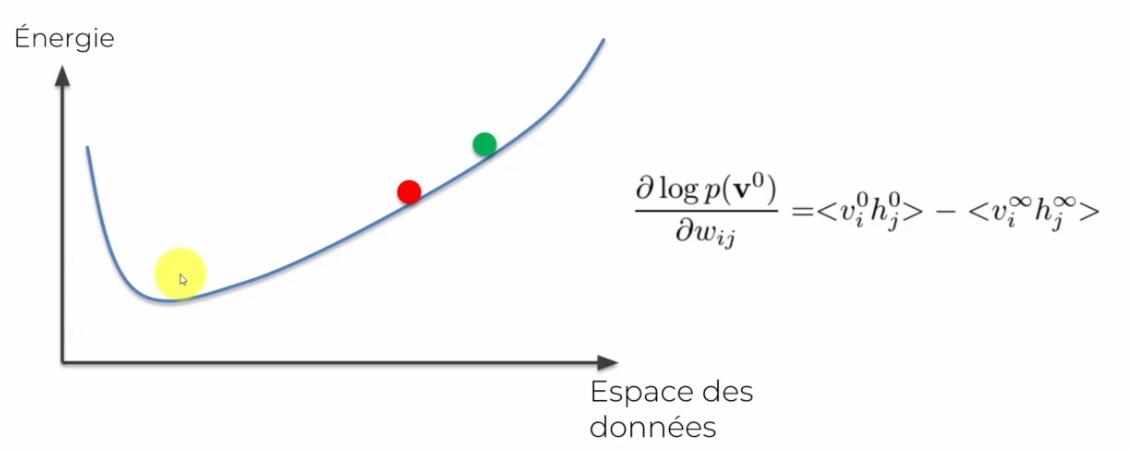
Ici notre énergie minimale est le creux de la courbe, notre poid de depart réprésente le poid vert et le poid rouge est l'évolution de notre poid lors du premier calcul. En gros on veut que notre gradient soit égal à 0, ce qui veut dire que l'on a atteint le minimum.
Si l'on reprend l'explication du début : nos poids sont aléatoire jusqu'à l'échantillonnage, ce qui nous donne la direction dans laquelle nous mettons à jour nos poids :
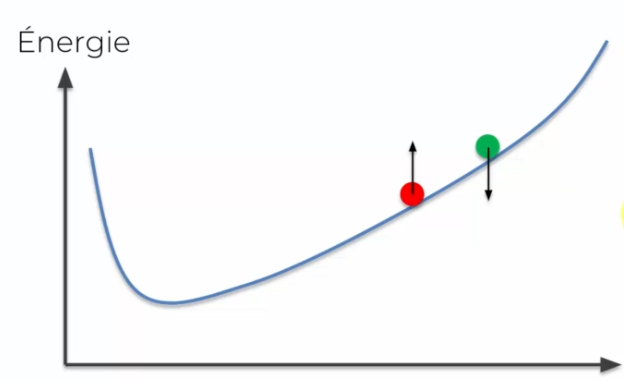
Cette direction va permettre l'ajustement de notre courbe d'énergie, ce qui va nous permettre d'être, en plusieurs mise à jour, à la valeur minimal d'énergie :
Réseau à croyance profondre
Ce réseau est un empillage de machine de Boltzmann où l'on rajoute plusieurs courches cachées. Mais nous avons une autre différence, nous avons la notion de direction qui va de haut en bas.
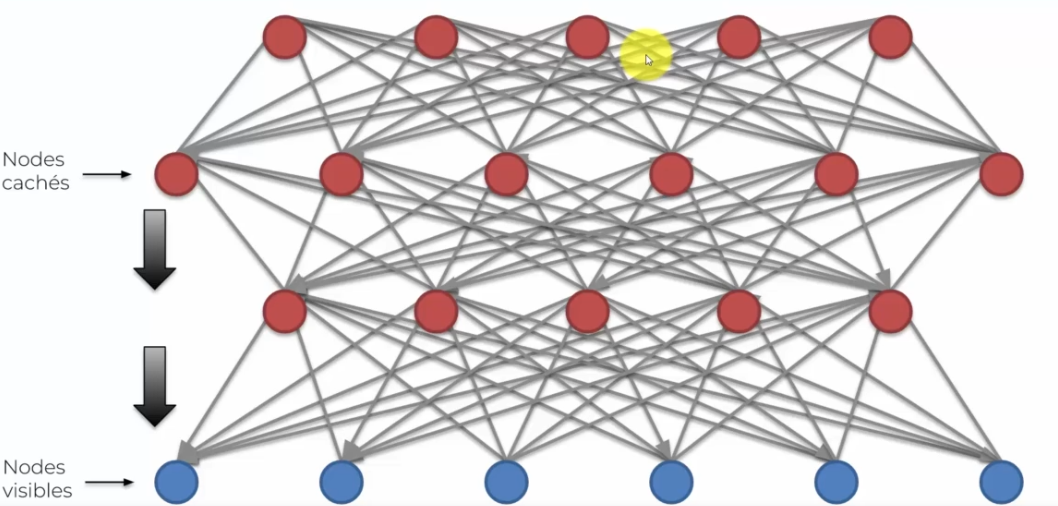
Pour entrainer ce type de réseau on a deux algorithmes :
- Entrainement par couche : On entraine couche par couche, sans notion de direction. C'est seulement au niveau de la prédiction que l'on ajoute les flèches. (Le plus utilisé)
- Entrainement de bas en haut puis de haut en bas.





