 Français
FrançaisIntroduction
Il est courant qu'un modèle d'apprentissage automatique ne fonctionne pas aussi bien que prévu lorsqu'il est d'abord entraîné. La décision de comment améliorer les performances du modèle peut être une tâche difficile, mais la compréhension de la biais et de la variance d'un algorithme d'apprentissage peut vous donner une bonne idée de ce qu'il faut essayer ensuite.
Dans cette section, nous allons examiner ce que signifient la biais et la variance dans le contexte de l'apprentissage automatique et comment elles peuvent être utilisées pour guider le développement d'un modèle. Nous utiliserons un exemple de régression linéaire pour illustrer les concepts de biais et de variance, et montrer comment ils peuvent être utilisés pour diagnostiquer et améliorer les performances d'un modèle.
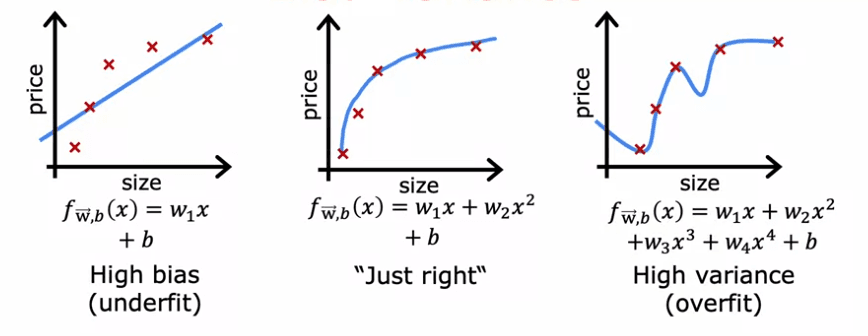
L'exemple que nous utiliserons est un ensemble de données d'une seule caractéristique x, où nous essayons d'ajuster une droite aux données. Si nous ajustons une droite aux données, cela ne fonctionne pas très bien, et nous disons que l'algorithme a un grand biais ou qu'il sous-ajuste l'ensemble de données. Si nous ajustons un polynôme de quatrième degré, l'algorithme a une grande variance ou il sur-ajuste l'ensemble de données. Au milieu, si nous ajustons un polynôme quadratique, cela a l'air assez bien. C'est le modèle "juste".
Lorsque vous avez plus de caractéristiques, il n'est pas aussi facile de visualiser si le modèle fonctionne bien. Au lieu de cela, une manière plus systématique de diagnostiquer si l'algorithme a un grand biais ou une grande variance consiste à regarder les performances de l'algorithme sur l'ensemble d'entraînement et sur l'ensemble de validation croisée.
Pour cela, nous calculons l'erreur d'entraînement, J_train, qui indique comment bien l'algorithme fonctionne sur l'ensemble d'entraînement, et l'erreur de validation croisée, J_cv, qui indique comment bien l'algorithme fonctionne sur des exemples qu'il n'a pas encore vus.
- Un algorithme avec une forte biais, ou un sous-ajustement, aura un J_train élevé et un J_cv élevé.
- Un algorithme avec une forte variance, ou un sur-ajustement, aura un J_train faible et un J_cv élevé.
- Un bon modèle, ou celui qui est "juste", aura un J_train faible et un J_cv faible.
Pour résumer, lorsque le degré du polynôme est 1:
- J_train est élevé et J_cv est élevé, indiquant une forte biais. (Sous apprentissage)
Lorsque le degré du polynôme est 4:
- J_train est faible mais J_cv est élevé, indiquant une forte variance.(Surapprentissage)
Lorsque le degré du polynôme est 2:
- J_train et J_cv sont bas, indiquant un bon modèle.
En conclusion, comprendre la biais et la variance d'un algorithme d'apprentissage automatique peut être un outil puissant dans le développement d'un modèle. En regardant les performances de l'algorithme sur l'ensemble d'entraînement et sur l'ensemble de validation croisée, vous pouvez diagnostiquer si l'algorithme a une forte biais ou une forte variance et prendre les mesures appropriées pour améliorer les performances du modèle.
Régulation
La régularisation est une technique utilisée pour éviter le surapprentissage dans les modèles d'apprentissage automatique. Elle consiste à ajouter un terme de pénalité à la fonction de coût que le modèle essaie d'optimiser. Le paramètre de régularisation, Lambda, contrôle le compromis entre la réduction des paramètres du modèle et l'ajustement aux données d'entraînement. Dans cet article, nous allons explorer comment le choix de Lambda affecte le biais et la variance d'un modèle de régression polynomiale de quatrième ordre, ainsi que la manière de choisir une bonne valeur de Lambda en utilisant la validation croisée.
Lorsque Lambda est fixé à une valeur élevée, le modèle est fortement incité à maintenir les paramètres petits, ce qui entraîne un modèle qui sous-apprend les données d'entraînement. Cela peut être observé dans l'exemple suivant :
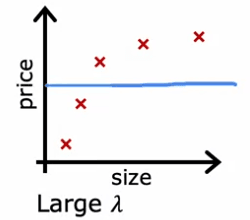
- où Lambda est fixé à 10 000
- où le modèle est approximativement constant
- a un biais élevé et une erreur J_train importante.
D'autre part, lorsque Lambda est fixé à une petite valeur, telle que zéro, il n'y a pas de régularisation, et le modèle surapprend les données. Cela peut être observé dans l'exemple suivant :
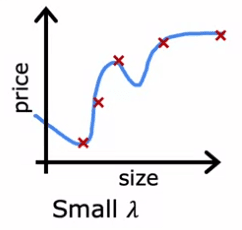
- où Lambda est fixé à 0
- où le modèle est une courbe sinueuse
- a une variance élevée et une erreur J_cv importante.
Le but est de trouver une valeur intermédiaire de Lambda qui donne un modèle qui s'ajuste bien aux données, avec une faible erreur J_train et J_cv. Une façon de procéder est d'utiliser la validation croisée. Le processus consiste à essayer une gamme de valeurs possibles pour Lambda, à ajuster les paramètres en utilisant ces différents paramètres de régularisation, puis à évaluer la performance sur l'ensemble de validation croisée. La valeur de Lambda qui donne la plus faible erreur J_cv est choisie comme valeur optimale.
Dans l'exemple fourni, après avoir essayé différentes valeurs de Lambda, il a été constaté que :
- J_cv de W5, B5 avait la plus faible valeur, et cette valeur de Lambda a donc été choisie.
- Pour estimer l'erreur de généralisation, l'erreur de l'ensemble de test, J_tests de W5, B5, est rapportée.
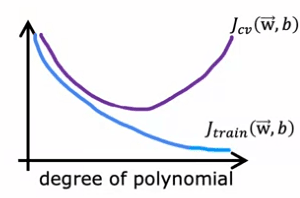
La figure fournie illustre également comment l'erreur d'entraînement et l'erreur de validation croisée varient en fonction du paramètre Lambda. À l'extrême de Lambda égal à zéro, le modèle a une variance élevée et J_train est faible tandis que J_cv est élevée, car le modèle fonctionne bien sur les données d'entraînement mais pas sur l'ensemble de validation croisée.
La régularisation est une technique importante en apprentissage automatique pour éviter le surapprentissage et le paramètre de régularisation Lambda contrôle le compromis entre la réduction des paramètres du modèle et l'ajustement aux données d'entraînement. Le choix de Lambda peut affecter le biais et la variance du modèle et les performances globales. La validation croisée peut être utilisée pour choisir une bonne valeur de Lambda en essayant différentes valeurs possibles et en évaluant les performances sur l'ensemble de validation croisée.
Niveau de performance
La reconnaissance vocale est une technologie cruciale qui permet aux utilisateurs de rechercher sur le Web sur leur téléphone portable en parlant plutôt qu'en tapant sur de petites touches. Le travail des algorithmes de reconnaissance vocale est de transcrire des entrées audio, telles que "Quel temps fait-il aujourd'hui?" ou "Les cafés à proximité", en texte.
Cependant, même avec les meilleurs algorithmes, la reconnaissance vocale n'est pas un processus parfait. Dans cette section, nous allons explorer comment mesurer les performances d'un algorithme de reconnaissance vocale et déterminer s'il a un biais élevé ou une variance élevée.
Une façon de mesurer les performances d'un algorithme de reconnaissance vocale est de calculer l'erreur d'entraînement, qui est le pourcentage de clips audio dans l'ensemble d'entraînement que l'algorithme ne transcrit pas correctement dans son intégralité. Par exemple : Si l'erreur d'entraînement pour un ensemble de données particulier est de 10,8%, cela signifie que l'algorithme transcrit parfaitement l'audio pour 89,2% de l'ensemble d'entraînement, mais fait une erreur dans 10,8% de l'ensemble d'entraînement.
Une autre façon de mesurer les performances de l'algorithme est de calculer l'erreur de validation croisée, qui est le pourcentage de clips audio dans un ensemble de validation croisée séparé que l'algorithme ne transcrit pas correctement dans son intégralité. Par exemple : Si l'erreur de validation croisée pour un ensemble de données particulier est de 14,8%, cela signifie que l'algorithme transcrit correctement l'audio pour 85,2% de l'ensemble de validation croisée, mais fait des erreurs dans 14,8% de l'ensemble de validation croisée.
À première vue, il peut sembler qu'une erreur d'entraînement de 10,8% et une erreur de validation croisée de 14,8% indiquent que l'algorithme a un biais élevé. Cependant, il est également important de considérer le niveau de performance humain lors de l'analyse de la reconnaissance vocale. En d'autres termes, à quel point les humains peuvent-ils transcrire avec précision la parole à partir de clips audio de mauvaise qualité ? Par exemple : Si vous mesurez à quel point les locuteurs fluides peuvent transcrire des clips audio et que vous constatez que la performance humaine atteint une erreur de 10,6%, il devient clair qu'il est difficile d'attendre d'un algorithme d'apprentissage qu'il fasse beaucoup mieux.

Par conséquent, pour juger si l'erreur d'entraînement est élevée, il est plus utile de voir si l'erreur d'entraînement est bien supérieure à un niveau de performance humain. Dans cet exemple, l'erreur d'entraînement de l'algorithme est seulement 0,2 % pire que celle des humains, ce qui n'est pas une différence significative. Cependant, l'écart entre l'erreur d'entraînement et l'erreur de validation croisée est bien plus grand, à 4 %. Cela suggère que l'algorithme a plus un problème de variance qu'un problème de biais.
Lors de l'évaluation des performances d'un algorithme de reconnaissance vocale, il est important d'établir un niveau de performance de référence. Cela peut être fait en mesurant les performances humaines, en les comparant à un algorithme concurrent ou en devinant en fonction de l'expérience antérieure. Une fois qu'un niveau de performance de référence a été établi, les quantités clés à mesurer sont la différence entre l'erreur d'entraînement et le niveau de référence, et l'écart entre l'erreur d'entraînement et l'erreur de validation croisée. Si la première différence est grande, l'algorithme a un biais élevé, et si le deuxième écart est élevé, l'algorithme a une variance élevée.
Courbe d'apprentissage
Les courbes d'apprentissage pour un modèle qui ajuste une fonction quadratique de second ordre peuvent être tracées afin d'analyser la performance du modèle.
La figure aura l'axe horizontal comme la taille de l'ensemble d'entraînement ou le nombre d'exemples, et l'axe vertical sera l'erreur, qui peut être l'erreur de validation croisée (J_cv) ou l'erreur d'entraînement (J_train). Lorsque J_cv est tracé, il est prévu que lorsque la taille de l'ensemble d'entraînement augmente, le modèle apprendra mieux et l'erreur de validation croisée diminuera.
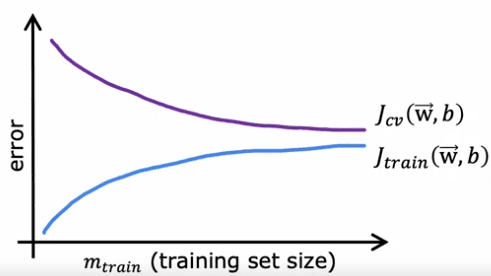
Cependant, lors du traçage de J_train, on observe que lorsque la taille de l'ensemble d'entraînement augmente, l'erreur d'entraînement augmente réellement. C'est parce qu'avec un petit nombre d'exemples d'entraînement, il est relativement facile d'atteindre une erreur d'entraînement nulle ou très faible, mais lorsque la taille de l'ensemble d'entraînement augmente, il devient plus difficile pour la fonction quadratique d'ajuster tous les exemples d'entraînement parfaitement. De plus, l'erreur de validation croisée est généralement plus élevée que l'erreur d'entraînement car le modèle est ajusté à l'ensemble d'entraînement, et il est donc prévu qu'il se comporte mieux sur l'ensemble d'entraînement que sur l'ensemble de validation.
Lors de la comparaison d'un modèle avec un biais élevé (sous-apprentissage) à celui avec une variance élevée (surapprentissage), les courbes d'apprentissage diffèrent également :
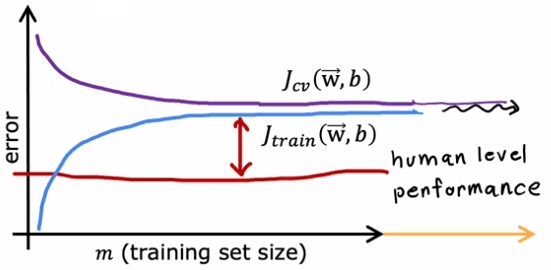
Dans le cas d'un biais élevé, l'erreur d'entraînement augmentera et se stabilisera lorsque la taille de l'ensemble d'entraînement augmentera. C'est parce que le modèle est trop simple et donc, même avec plus d'exemples d'entraînement, il n'y a pas beaucoup de changement. De même, l'erreur de validation croisée diminuera puis se stabilisera.
En revanche, dans le cas d'une variance élevée, l'erreur d'entraînement diminuera alors que l'erreur de validation croisée augmentera à mesure que la taille de l'ensemble d'entraînement augmentera.
L'analyse des courbes d'apprentissage peut donner un aperçu de la performance d'un modèle et de la sous ou sur-apprentissage. De plus, il peut être observé que lorsque la taille de l'ensemble d'entraînement augmente, il devient plus difficile pour le modèle d'atteindre une erreur d'entraînement nulle, et l'écart entre l'erreur d'entraînement et de validation sera un indicateur du compromis biais-variance du modèle.
Décision
Les erreurs d'entraînement et de validation croisée, Jtrain et Jcv, peuvent nous donner une idée de la présence d'un biais élevé ou d'une variance élevée dans notre algorithme d'apprentissage. Dans cet article, nous allons examiner un exemple de régression linéaire régularisée pour prédire les prix des logements et explorer comment nous pouvons utiliser ces informations pour améliorer les performances de notre algorithme.
Lorsque notre algorithme a un biais élevé, cela signifie qu'il ne fonctionne pas bien même sur l'ensemble d'entraînement. Dans ce cas, les principales façons de résoudre ce problème sont d'obtenir plus de données d'entraînement ou d'ajouter des fonctionnalités supplémentaires. D'autre part, lorsque notre algorithme a une variance élevée, cela signifie qu'il surapprend à un très petit ensemble d'entraînement. Pour résoudre ce problème, nous pouvons essayer d'obtenir plus d'exemples d'entraînement ou de simplifier notre modèle en utilisant un ensemble plus restreint de fonctionnalités ou en augmentant le paramètre de régularisation Lambda.
Prenons l'exemple de la régression linéaire régularisée pour prédire les prix des logements. Dans ce cas, nous avons implémenté l'algorithme mais il fait de grandes erreurs dans les prédictions. Pour améliorer les performances de notre algorithme, nous avons plusieurs options telles que :
- Obtenir plus d'exemples d'entraînement
- Essayer un ensemble plus restreint de fonctionnalités
- Ajouter des fonctionnalités supplémentaires
- Ajouter des fonctionnalités polynomiales
- Diminuer Lambda
- Augmenter Lambda
La première option, obtenir plus d'exemples d'entraînement, aide à résoudre un problème de variance élevée. Si notre algorithme a un biais élevé, obtenir plus de données d'entraînement par lui-même ne sera probablement pas très utile. Cependant, si notre algorithme a une variance élevée, obtenir plus d'exemples d'entraînement aidera beaucoup.
Essayer un ensemble plus restreint de fonctionnalités peut également aider à résoudre un problème de variance élevée. Parfois, si notre algorithme d'apprentissage a trop de fonctionnalités, il donne à l'algorithme une flexibilité trop importante pour ajuster des modèles très compliqués. Éliminer ou réduire le nombre de fonctionnalités aidera à réduire la flexibilité de notre algorithme pour surapprendre les données.
D'autre part, l'ajout de fonctionnalités supplémentaires aide à résoudre un problème de biais élevé. Si nous essayons de prédire le prix d'une maison en fonction de sa taille, mais il s'avère que le prix d'une maison dépend également beaucoup du nombre de chambres et du nombre d'étages, alors notre algorithme ne réussira jamais à moins que nous ajoutions ces fonctionnalités supplémentaires.
L'ajout de fonctionnalités polynomiales est similaire à l'ajout de fonctionnalités supplémentaires. Si nos fonctions linéaires ne correspondent pas bien à l'ensemble d'entraînement, l'ajout de fonctionnalités polynomiales supplémentaires peut nous aider à mieux faire sur l'ensemble d'entraînement.
La diminution de Lambda signifie utiliser une valeur plus faible pour le paramètre de régularisation. Cela donnera moins d'importance à ce terme et plus d'importance à ce terme pour essayer de mieux faire sur l'ensemble d'entraînement. Cela aide à résoudre un problème de biais élevé.
Inversement, l'augmentation de Lambda aide à résoudre un problème de variance élevée. Si nous surapprenons l'ensemble d'entraînement, l'augmentation de Lambda forcera l'algorithme à ajuster une fonction plus lisse et l'utiliser pour résoudre un problème de variance élevée.
Lorsque notre algorithme présente un biais élevé, nous pouvons essayer d'obtenir plus de données d'entraînement ou ajouter des fonctionnalités supplémentaires. Lorsque notre algorithme présente une variance élevée, nous pouvons essayer d'obtenir plus d'exemples d'entraînement ou simplifier notre modèle en utilisant un ensemble de fonctionnalités plus petit ou en augmentant le paramètre de régularisation Lambda. En examinant les erreurs d'entraînement et de validation croisée, Jtrain et Jcv, nous pouvons prendre de meilleures décisions sur ce qu'il faut essayer ensuite pour améliorer les performances de notre algorithme d'apprentissage.
Nous pouvons conclure que:
- obtenir plus d'exemples d'entraînement: corrige la variance élevée
- essayer un ensemble de fonctionnalités plus petit: corrige la variance élevée
- ajouter des fonctionnalités supplémentaires: corrige le biais élevé
- ajouter des fonctionnalités polynomiales: corrige le biais élevé
- diminuer Lambda: corrige le biais élevé
- augmenter Lambda: corrige la variance élevée
Appliquer avec les réseaux neuronaux
Le compromis biais-variance est un concept fondamental en apprentissage automatique et est souvent discuté par les ingénieurs lorsqu'ils développent des algorithmes. Un biais élevé ou une variance élevée peuvent tous deux avoir un impact négatif sur les performances d'un algorithme, et trouver un équilibre entre les deux est crucial pour obtenir des résultats optimaux. Cependant, avec l'avènement des réseaux neuronaux et l'idée de big data, nous avons maintenant de nouvelles façons de résoudre ce compromis.
Un exemple du compromis biais-variance est lorsque l'on ajuste différents polynômes d'ordre à un ensemble de données. Un modèle linéaire a une structure simple et peut présenter un biais élevé. D'un autre côté, un modèle complexe avec un degré de polynôme élevé peut souffrir d'une variance élevée. Traditionnellement, les ingénieurs en apprentissage automatique devaient équilibrer la complexité d'un modèle en ajustant le degré de polynôme ou le paramètre de régularisation afin de réduire à la fois le biais élevé et la variance élevée.
Mais avec les réseaux neuronaux, nous avons une nouvelle façon de résoudre ce dilemme. Les grands réseaux neuronaux, lorsqu'ils sont entraînés sur des ensembles de données de petite à moyenne taille, peuvent être des machines à faible biais. Cela signifie que si nous rendons nos réseaux neuronaux suffisamment grands, nous pouvons presque toujours bien ajuster notre ensemble d'entraînement, tant que l'ensemble d'entraînement n'est pas énorme. Cela nous donne une nouvelle recette pour réduire le biais ou la variance selon les besoins sans avoir à faire de compromis entre les deux.
La recette est simple : tout d'abord, entraînez votre algorithme sur votre ensemble d'entraînement, puis vérifiez s'il fonctionne bien sur cet ensemble. S'il ne fonctionne pas bien, vous avez un problème de biais élevé et l'une des façons de réduire ce biais est d'utiliser un réseau de neurones plus grand avec plus de couches cachées ou plus d'unités cachées par couche. Continuez à suivre cette boucle jusqu'à ce que l'algorithme fonctionne bien sur l'ensemble d'entraînement. Ensuite, vérifiez s'il fonctionne bien sur l'ensemble de validation croisée. S'il ne fonctionne pas bien, vous avez un problème de variance élevée et l'une des façons de réduire cette variance est d'obtenir plus de données et de réentraîner le modèle. Continuez à suivre cette boucle jusqu'à ce que l'algorithme fonctionne bien sur l'ensemble de validation croisée. Maintenant, vous avez un modèle qui devrait bien généraliser pour de nouveaux exemples.
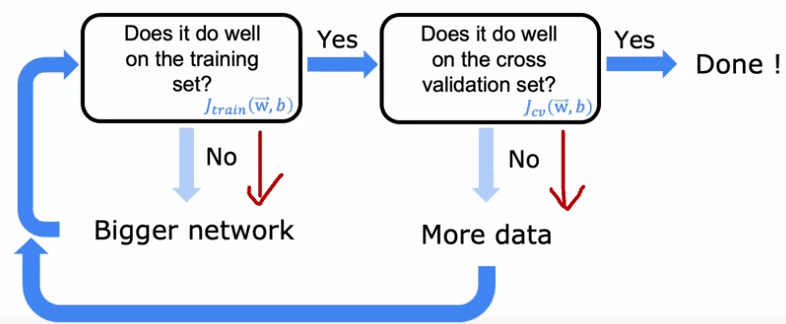
Il y a des limites à cette recette, comme le coût de l'entraînement de réseaux de neurones plus grands et la disponibilité de plus de données. Cependant, l'avènement des réseaux de neurones a été facilité par l'essor de l'informatique rapide, y compris les GPU, qui ont été utiles pour accélérer le processus d'entraînement. Cette recette explique également l'essor de l'apprentissage en profondeur ces dernières années, car il a été fructueux dans des applications où beaucoup de données sont disponibles.
Le compromis biais-variance est un concept fondamental en apprentissage automatique et les réseaux de neurones offrent une nouvelle façon de résoudre ce dilemme. En entraînant de grands réseaux de neurones sur des ensembles de données de taille modérée, nous pouvons réduire le biais ou la variance selon les besoins sans avoir à faire de compromis entre les deux. Cependant, cette recette a ses limites et il est essentiel de garder à l'esprit que, pendant le développement d'un algorithme d'apprentissage automatique, le biais et la variance peuvent changer, et il est important de les surveiller en permanence.





