 Français
FrançaisCloud Storage
Cloud storage is a model of storing computer data in which digital data is stored in a logical grouping. There are three categories of storage:
Block Storage
Data is stored in blocks on one or more locally attached disks. This type of storage is used for databases, ERPs, etc. Data is divided into blocks to facilitate data management.
File Storage
Data is stored as files in folders belonging to a hierarchy through a network share (NAS).
Object Storage
Data is stored as an object identified by a key and a flat file. These data are accessed via an API by targeting a key.
Amazon's cloud storage services include:
- Amazon RDS: relational database service (Amazon Elastic Block Store)
- Amazon Glacier: cold storage service for archives (Amazon S3)
- Amazon CloudFront: moves objects closer to users (Amazon S3)
Amazon Elastic Block Store
Amazon Elastic Block Store (EBS) is a block mode storage directly attached to the server. This service offers extremely low latency required for high-performance workloads. EBS features include:
- Data is divided into fixed-size blocks (4KB)
- An allocation table is required to locate data
- Read and write is done at the block level
- Use of protocols: HDD SAS, ISCSI, FC, FCoE
- Persistent, consistent, low-latency accessible data: EBS volumes
- Data replicated in a single availability zone
- Backup in the form of snapshots or snapshots at a given time
- Real-time encryption (AES-256)
- Dynamically scalable size
- One volume per instance, but multiple volumes for an instance
The advantages of EBS are:
- Performance for any workload, meets almost all needs
- EBS volumes are 20 times more reliable than traditional disk drives (durability)
- Our disk scaling is almost unlimited
- Easy to use via Web CLI
- Pay-per-use: we pay for our provision, if we take 16 TB, those are our resources. That's what we'll pay for
- Elasticity: we take 500 GB, then we want to extend the elasticity of this volume
- Secure: data can be encrypted, through the layers...
- 5 GB/s
- Independent of an instance, can be detached and attached to another instance hot
EBS use cases are:
- Business continuity
- Enterprise applications
- NoSQL databases
- Big Data analysis engines
- Relational databases
- File systems and streams
Amazon Elastic File System
Cloud file storage is a method of storing data that allows servers and applications to access data via shared file systems. Data is stored as files in a hierarchical storage system (with a tree structure). This data is accessible through shared data access. Many instances can simultaneously access the EFS volume and apply CRUD actions on files at the same time. NTSv4 protocol is used, which allows files to be presented to users.
Advantages
- POSIX-compliant shared file storage: standard that allows access to users, groups, regions, etc. This applies at the file and folder level.
- Scalable performance: up to 500,000 IOPS.
- Fully managed service: we just need to enjoy the service, the rest is managed by AWS.
- Security and compliance.
- Consumption on demand: this is done according to the amount of data provided.
- MAX IO (up to 500,000 IOPS, for applications requiring maximum bandwidth) and General modes.
- Possible migration with EFS File Sync, which allows copying to be parallelized and data to be optimized.
- No fees for data access and requests.
- Throughput up to 10 GB/s.
Use cases
- Container storage: we can provision usage based on usage, which makes Kubernetes use.
- Media and entertainment.
- Analysis and machine learning: big data, analysis on large amounts of data.
- Database backups.
- Web services and content management.
- Move to managed file systems.
⚠️ Note: EFS is not supported for Amazon Windows, use EFSX. The NFS client for Linux is required to mount the EFS target!
Amazon Simple Storage Service
Object storage is ideal for building end-to-end modern applications that demand scaling and flexibility. S3 allows importing existing data stores for analysis, as well as for backup or archiving. A non-hierarchical flat structure is used, with the ability to use buckets and keys as a hierarchy. However, in the actual data structure, they are all at the same level. This approach is very effective for "Cloud Native" applications, which are DevOps-type applications, or in other words, applications that are decoupled (microservices). In this hierarchy, all buckets are of course secured with access management. There are advanced storage classes:
- S3 Standard: provides fast access to data.
- S3 IA: allows for storing less frequently accessed data.
- Glacier: which is an archive, whose data is never accessed. We can therefore create intelligent lifecycle policies that manage access to resources. Thus, if data is not accessed for a certain time, it means that we can archive that data.
In S3, there is no region, it is a so-called global service. However, it is included in a bucket that we name.
Regarding data deposit, it is important to migrate this data. Sometimes to retrieve data or upload data, we have to wait a long time. To speed up this waiting time, we can use a Snowball, which is a military-grade secure server. This server is sent to you, you retrieve the data that you then send back to AWS with your copies of data that AWS will put on your S3. To access our data, this is done via a key value, where the maximum size of an object is 5 TB.
Avantages
- Performance, scalability, and availability.
- Durability of 99.999999% thanks to replication across 6 availability zones.
- Intelligent tiering and access points: data can be moved to progressively cheaper storage.
- Security capabilities (data encryption with SSE), compliance, and auditing.
- Easy data management and access control.
- On-premises query services for analysis: S3 allows tools to directly connect and apply processing to objects.
- Most widely supported cloud storage service.
- No storage limit.
- Data consistency: when I copy data, we're sure it's in the correct version, but there may be a time delta in case of updates.
- S3 Transfer accelerates transfer speeds.
- S3 Inventory and Tag: allow for easy searching of objects.
Cas d'utilisation
- Data lakes and Big Data analysis.
- Cloud-native application data: if we want users to upload images, for example.
- Hybrid cloud storage: we use a service that works with S3, whose need is to accelerate processing through synchronization between services.
- Backup and restore.
- Disaster recovery.
- Archiving.
An important point is that versioning allows multiple versions of an object to be stored, but this is not always cost-effective. Indeed, we are billed on the total occupied volume, several versions of several heavy objects can be expensive.
It is important to note that to access S3, it is necessary to have an access key and a user ID. In addition, to protect the data stored in S3, it is recommended to use AWS SSE (Server-Side Encryption) encryption. This protects data both when it is stored and when it is in transit.
Amazon S3 is a highly performant, scalable, and globally available object storage service. It offers benefits such as durability, security, compliance, and auditing, as well as on-premises query capabilities for data analysis. It is used in many use cases such as data lakes, Big Data analytics, cloud-native application data, backup and restore, disaster recovery, and archiving.
Storing Databases in AWS (RDS / DynamoDb)
There are two major services:
- RDS: Relational Database Service (relational databases)
- DynamoDB: NoSQL
The big difference is represented by the schema:
- With a SQL schema, we use a structured query language. The structure and data type are rigid, they cannot be modified and are fixed in advance.
- With NoSQL, we store file structures representing our data.
DMS
The major advantages of RDS:
- Usage-based pricing: we can set up a database in a few clicks.
- Shared management model: AWS manages all the time-consuming and complex tasks.
- Support for major industry players (Aurora, PostgreSQL, MySQL, MariaDB, Oracle, SQL Server).
- Allows us to retain the use of familiar tools.
- Accelerates performance and service continuity.
- Allows customers to focus on their businesses.
- Replication and backup.
- Allows for database exports.
- High availability: we have an application switch in case of unavailability.
- Read replicas: unexpected growth in read is not a problem.
- Encryption with KMS or CloudHSM keys.
- Access management with IAM, while access to instances is via dedicated basic security groups.
Note that we have several services.

💡 Amazon Redshift is 65% cheaper and strongly encouraged by AWS to be used.
DynamoDB
Key-value databases are optimized for common access patterns, typically for storing and retrieving large volumes of data. These databases provide fast response times, even when processing extremely large volumes of concurrent requests. Since 2009, NoSQL databases have been in high demand and usage, particularly in the gaming industry, which brings enormous write and load performance.
💡 If you hear about serverless databases, DynamoDB will be the one for important tasks.
Amazon Elasticache (in memory)
In-memory databases are used for applications that require real-time access to data. By storing data directly in memory, these databases provide microsecond latency to applications for which millisecond latency is not sufficient. There are two types:
- Elasticache for Redis
- Elasticache for Memcached
💡 If we talk about microseconds or latencies below the millisecond, we talk about in-memory Elasticache.
Database Migration Service (DMS)
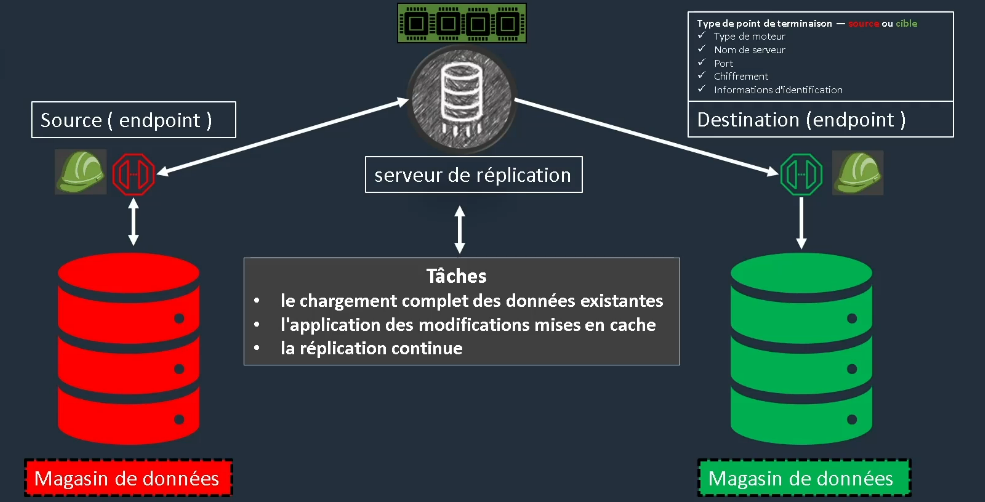
There's nothing really magical about DMS. We will have a replication server, surrounded by two endpoints. Each endpoint includes:
- The engine type
- The server name
- The port
- Encryption
- Credentials
Database migration with DMS
The goal of DMS is to migrate a database to the cloud. To do this, we start with a database on each side, and then we make a symmetry so that the two databases are identical. We then replicate the production database to the cloud, allowing migration.
You will need to provide a role in IAM for the users who will perform this migration. Once that is done, the registration process will establish a link to the first data store to replicate it to a second data center on a dedicated instance. There are then 3 distinct tasks:
- Full loading of existing data
- Application of cached changes
- Continuous replication
CloudFront
CloudFront is a service that allows providing content to end-users with lower latency by leveraging a global network of 216 points of presence, deployed in 84 cities across 42 countries, increasing availability. It offers protection against network and application layer attacks by increasing the surface area to allow users to interact with different edges. Security is also ensured by SSL/TLS encryption and HTTPS, as well as access control with signed URLs and cookies. In terms of security, CloudFront covers all compliance needs, making the service even more attractive.
Redundancy can be enabled for origins, optimizing service continuity. In other words, when a resource stops working, we have the option of using another edge.
As a scalable service, it offers tools to provide availability of large resources such as:
- Large libraries
- Media resources
- Streaming
You only pay for what you consume! There are also other tools such as:
- Complete APIs
- DevOps tools
Storage Gateway
Storage Gateway is a hybrid service that allows connecting your existing on-premises environments to the AWS cloud to increase performance. It stores data locally, but replicates it quickly. It offers:
- A file gateway, which provides a file interface for storing files as objects in S3.
- A tape gateway that presents a virtual tape library (VTL) to our existing backup application.
- A volume gateway that displays your application's block storage volumes using the iSCSI protocol. We'll take snapshots of volumes, but also replicate these volumes.
Services Analytics
EMR
EMR is a leading cloud-based Big Data platform for processing large amounts of data using open source tools based on Hadoop technology:
- Apache Spark
- Apache Hive
- Apache HBase
- Apache Flink
- Apache Hudi
- Presto
We can then provision a Hadoop cluster to work together on all of these machine learning and data indexing tasks, etc. The platform is very economical because it provisions only according to the tasks.
Kinesis
Kinesis makes it easy to collect, process, and analyze real-time streaming data, to quickly obtain strategic insights and respond rapidly. Kinesis will create streams and channels simultaneously. We can access data through APIs and say that queries are streamed into a Kinesis stream.
The service can then receive hundreds of thousands of data points, and we can select only the data that interests us. So, we do real-time Big Data.
Athena
Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL syntax. Athena works without a server, there is no infrastructure to manage and you pay only for the queries you execute. It's a serverless service, which is fully managed and secured by IAM! The goal is to fetch our data and pay only for our queries.





