 Français
FrançaisIntroduction
Node a bouleversé le monde des applications Web. L'une des raisons est la légèreté des spécifications matérielles nécessaires pour exécuter un serveur Web Node. Les moteurs de serveur Web traditionnels tels qu'Apache ou le serveur Web IIS de Microsoft avaient besoin de serveurs assez puissants pour gérer des milliers de requêtes HTTP par seconde.
Node utilise une architecture à un seul thread, où chaque instruction qui doit attendre est placée dans une file d'attente pour être traitée plus tard. Le serveur n'exécute donc qu'un seul thread d'exécution à la fois, mais peut gérer de nombreuses requêtes simultanées avec une quantité très faible de CPU ou de RAM. En conséquence, de nombreux serveurs Web Node peuvent être exécutés sur un seul matériel physique, comparé aux autres serveurs Web traditionnels.
De nombreux services cloud ont poussé ce concept plus loin en offrant la possibilité d'exécuter du code sans avoir besoin d'un serveur. Le code est fourni avec un environnement d'exécution qui possède toutes les dépendances dont nous pourrions avoir besoin. Par exemple, avec Node, tant que les modules de base de Node sont disponibles au moment de l'exécution, la configuration du code pour gérer une seule requête Web ne nécessite que quelques lignes de code.
Cette architecture d'exécution de code pour gérer les demandes est connue sous le nom d'architecture serverless. Nous n'avons pas à nous soucier de la maintenance d'un serveur pour traiter une demande particulière ; le fournisseur de services cloud s'en occupe pour nous.
Serverless
Avant de créer notre première fonction Lambda, nous allons explorer les différents éléments de l'architecture AWS que nous utiliserons pour répondre à une requête Web. Ces éléments sont représentés dans le schéma ci-dessous :

Le diagramme représente les différents éléments architecturaux utilisés pour répondre à une demande client via une requête HTTP GET sur le point de terminaison /users de l'API.
- Le premier élément architectural est Amazon API Gateway, qui fournit l'infrastructure nécessaire pour les appels HTTP et WebSocket aux clients.
- Nous avons configuré un gestionnaire GET pour le point de terminaison /users pour appeler une fonction AWS Lambda nommée users-get.js, qui a besoin d'accéder à une table Amazon DynamoDB.
- Pour permettre l'accès des fonctions Lambda à la table DynamoDB, nous utiliserons le service IAM pour fournir les autorisations appropriées.
- Amazon propose une API de configuration pour automatiser ces processus, ainsi qu'une interface en ligne de commande appelée AWS CLI et une autre interface appelée AWS SAM CLI, qui utilise des fichiers modèles YAML ou JSON pour configurer les composants architecturaux.
Nous utiliserons AWS SAM CLI pour configurer et déployer nos fonctions Lambda et tables DynamoDB, ce qui nous permettra de créer des applications sans serveur.
Installation du CLI SAM
Avant de commencer à utiliser AWS SAM, il est nécessaire d'installer les composants suivants :
- AWS CLI : l'interface de ligne de commande d'AWS, utilisée par l'AWS SAM CLI pour certaines de ses fonctions.
- Docker : le conteneur virtuel qui simule l'environnement Lambda dans lequel les fonctions seront exécutées.
- Homebrew (pour les systèmes macOS) : le gestionnaire de packages utilisé par l'AWS SAM CLI pour l'installation sur les systèmes macOS.
- AWS SAM : l'option de ligne de commande AWS spécifique pour travailler avec des applications sans serveur.
Il est également nécessaire d'avoir un compte AWS actif pour créer des ressources au sein d'AWS. Heureusement, il est possible de créer un compte gratuit et d'utiliser gratuitement un grand nombre de services AWS en utilisant le niveau gratuit des services.
Vous pouvez trouver le guide d'installation pour votre système d'exploitation sur le site web d'AWS. Une fois installé, vous pouvez vérifier que SAM est bien installé en exécutant la commande sam --version dans votre terminal.
sam --version
SAM CLI, version 1.64.0
Avant de pouvoir utiliser l'interface de ligne de commande SAM à partir de la ligne de commande, il est nécessaire de s'assurer que les informations d'identification ont été correctement configurées pour l'AWS CLI.
Pour configurer les informations d'identification que nous utiliserons à partir de la ligne de commande pour nous connecter à AWS, nous utilisons la commande aws configure, qui est utilisée pour configurer l'AWS CLI. Cette commande demande les clés d'identification d'accès et la région par défaut pour l'AWS CLI. Ces informations sont stockées dans le fichier ~/.aws/credentials et le fichier ~/.aws/config sur notre ordinateur local.
~/.aws$ aws configure
AWS Access Key ID [None]: [ paste enter access key ]
AWS Secret Access Key [None]: [ paste secret access key ]
Default region name [us-east-1]:
Default output format [None]:
Une fois que les informations d'identification ont été correctement configurées, nous pouvons utiliser l'interface de ligne de commande SAM pour créer et gérer des applications sans serveur sur AWS.
Initialisation d'une application SAM
Après avoir configuré les informations d'identification pour l'AWS CLI, nous pouvons initialiser une application SAM en utilisant la commande sam init suivie de l'option --name pour nommer l'application.
Par exemple, pour créer une application nommée "api-app", nous exécutons la commande suivante :
sam init --name api-app
Cela lance la routine d'initialisation qui pose plusieurs questions sur la ligne de commande, telles que le type de package à utiliser (zip ou image), le runtime pour les fonctions Lambda (par exemple, nodejs14.x ou python3.8), et le modèle de démarrage rapide à utiliser pour l'application (par exemple, hello-world ou Step Functions Sample App).
Voici les exemples des questions posées par la commande sam init :
What package type would you like to use?
1 - Zip (artifact is a zip uploaded to S3)
2 - Image (artifact is an image uploaded to an ECR image repository)
Package type:
Ici, nous pouvons choisir l'option 1 pour utiliser des artefacts Zip téléchargés via un compartiment S3.
Which runtime would you like to use?
1 - nodejs14.x
2 - python3.8
3 - java11
4 - go1.x
5 - dotnetcore3.1
Runtime:
Ici, nous choisissons l'option 1 pour utiliser le runtime nodejs14.x. Il existe plusieurs autres options de runtime disponibles, telles que python3.8, java11, go1.x et dotnetcore3.1
AWS quick start application templates:
1 - Hello World Example
2 - Step Functions Sample App (Stock Trader)
3 - Quick Start: From Scratch
4 - Quick Start: Scheduled Events
5 - Quick Start: S3
6 - Quick Start: SQS
7 - Quick Start: IoT
8 - Quick Start: Web Backend
9 - Quick Start: Web Frontend
Template selection:
Ici, nous choisissons le modèle "Hello World Example". Il existe également d'autres modèles de démarrage rapide disponibles, tels que Step Functions Sample App (Stock Trader), Quick Start: Scheduled Events, Quick Start: S3, Quick Start: SQS, Quick Start: IoT, Quick Start: Web Backend et Quick Start: Web Frontend.
-----------------------
Generating application:
-----------------------
Name: api-app
Runtime: nodejs14.x
Dependency Manager: npm
Application Template: hello-world
Output Directory: .
Next steps can be found in the README file at ./api-app/README.md
Structure
Fichiers et dossiers créés par la CLI SAM
Lorsque nous avons initialisé notre application avec la CLI SAM, plusieurs fichiers et dossiers ont été créés pour nous. Voici une description de ces fichiers et dossiers :
.
└── api-app
├── template.yaml
├── README.md
├── hello-world
│ ├── tests
│ │ ├── unit
│ │ │ └── test-handler.js
│ ├── package-lock.json
│ ├── package.json
│ └── app.js
└── events
└── event.json
- Le répertoire
api-appcorrespond au nom que nous avons utilisé lors de l'initialisation de l'application. - Le fichier
template.yamlest utilisé pour décrire tous les éléments AWS dont nous aurons besoin dans notre application. Cela inclut les noms de point de terminaison qu'Amazon API Gateway utilisera, les noms des fichiers JavaScript qui seront utilisés comme fonctions de gestionnaire Lambda, ainsi que les paramètres de contrôle d'accès IAM. Nous pouvons également inclure des éléments décrivant les tables DynamoDB et attribuer différents droits d'accès à la base de données à chacune de nos fonctions Lambda. Voici un exemple de ce qui se trouve dans le fichiertemplate.yaml:
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello-world/
Handler: app.lambdaHandler
Runtime: nodejs14.x
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
Ici, nous avons une ressource nommée HelloWorldFunction de type AWS::Serverless::Function. Cette ressource possède un ensemble de propriétés, dont une nommée CodeUri. Cette propriété CodeUri spécifie le répertoire dans lequel trouver la source de cette fonction sans serveur et est définie sur hello-world/. La propriété Handler nous dit de regarder dans un fichier nommé app.js pour une fonction exportée nommée lambdaHandler, qui sera exécutée lorsque ce Lambda sera appelé. La propriété Runtime spécifie l'environnement dans lequel exécuter cette fonction Lambda, qui est définie sur nodejs14.x. Nous avons également une section Events, qui répertorie HelloWorld comme un événement de type Api. Cette section décrit la configuration de la passerelle API, qui a une propriété Path sur /hello et une propriété Method sur get. Cela signifie que nous avons configuré une opération GET au point de terminaison /hello, qui appellera notre fonction Lambda.
- Le dossier
hello-worldcontient le code source de notre fonction Lambda. Il contient également un dossiertestsqui contient des tests unitaires pour notre fonction. - Le dossier
eventscontient un fichierevent.jsonqui est utilisé pour tester notre fonction Lambda en local. Ce fichier contient les données d'événement JSON qui seraient envoyées à notre fonction dans un environnement de production.
C'est ainsi que la CLI SAM organise notre projet et nous fournit un point de départ pour commencer à développer des fonctions Lambda
Déploiement d'une application SAM
Nous pouvons déployer notre application SAM sur AWS en utilisant la commande sam deploy de l'interface de ligne de commande. La première fois que nous exécutons cette commande, nous devrons répondre à quelques questions concernant notre configuration, qui seront stockées pour une utilisation ultérieure. Voici un exemple de commande avec les options spécifiées :
sam deploy --guided
Setting default arguments for 'sam deploy'
=========================================
Stack Name [sam-app]: api-app
AWS Region [us-east-1]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [Y/n]: Y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: Y
HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: Y
Save arguments to configuration file [Y/n]: Y
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
Dans cet exemple, nous avons spécifié le nom de la pile et la région AWS. Les options sont stockées dans un fichier nommé samconfig.toml, afin que nous n'ayons pas à les spécifier à nouveau la prochaine fois que nous exécuterons la commande sam deploy.
Une fois la commande terminée, nous verrons l'URL complète qui appellera notre fonction Lambda. Nous pouvons copier et coller cette valeur dans un navigateur pour tester la version déployée de notre fonction. Voici un exemple de réponse :
https://d6vnhxnc83.execute-api.us-east-1.amazonaws.com/Prod/hello/
{
message: "hello world"
}
En quelques étapes simples, nous avons initialisé et déployé une application sans serveur AWS en utilisant l'interface de ligne de commande SAM, et nous pouvons maintenant tester la version déployée de notre fonction Lambda presque immédiatement.
Construire une API
Pour prendre en charge la fonctionnalité dont nos applications ont besoin, nous aurons besoin de trois tables de base de données DynamoDB : ProductTable, UserTable et UserCartTable.
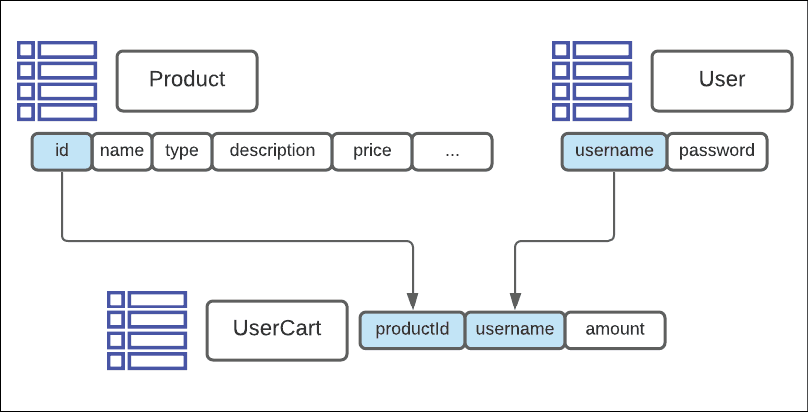
Nous pouvons définir la table ProductTable dans notre fichier template.yaml comme suit :
Resources:
ProductTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: ProductTable
AttributeDefinitions:
- AttributeName: "id"
AttributeType: "S"
KeySchema:
- AttributeName: "id"
KeyType: "HASH"
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
HelloWorldFunction:
# Existing Lambda attributes
Nous pouvons également définir la table UserTable dans notre fichier template.yaml en ajoutant ce qui suit à la définition de la table ProductTable :
UserTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: UserTable
AttributeDefinitions:
- AttributeName: "username"
AttributeType: "S"
KeySchema:
- AttributeName: "username"
KeyType: "HASH"
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
Enfin, nous pouvons définir la table UserCartTable dans notre fichier template.yaml comme suit :
UserCartTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: UserCartTable
AttributeDefinitions:
- AttributeName: "username"
AttributeType: "S"
- AttributeName: "productId"
AttributeType: "S"
KeySchema:
- AttributeName: "username"
KeyType: "HASH"
- AttributeName: "productId"
KeyType: "RANGE"
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
Notez que la table UserCartTable a une clé primaire composée de deux champs, username et productId. Ces deux champs doivent être définis à la fois dans la propriété AttributeDefinitions et dans les propriétés KeySchema.
Une fois que nous avons défini nos tables de base de données dans notre fichier template.yaml, nous pouvons exécuter la commande sam deploy pour créer les tables DynamoDB sur notre compte AWS.
NoSQL
Utilisation de NoSQL Workbench pour DynamoDB
Lorsque vous travaillez avec les tables DynamoDB, Amazon propose un utilitaire d'interface graphique appelé NoSQL Workbench pour DynamoDB. Cet outil permet d'interroger les données dans une table et de générer du code pour lire et écrire des données. Voici comment installer et configurer NoSQL Workbench pour DynamoDB.
Installation
Pour installer NoSQL Workbench, vous devez d'abord trouver le lien de téléchargement approprié pour votre système d'exploitation dans la documentation d'AWS : https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/workbench.settingup.html.
Configuration
Une fois installé, vous devrez ajouter une connexion à distance à votre instance DynamoDB en spécifiant un ID de clé d'accès et une clé d'accès secrète. Nous supposerons que vous avez déjà configuré une connexion et que la région est correctement définie. Voici comment accéder à NoSQL Workbench :
- Ouvrez NoSQL Workbench pour DynamoDB.
- Sélectionnez "New Connection" dans la barre latérale.
- Dans la section "Connection Type", sélectionnez "AWS Profile" ou "AWS Access Key".
- Si vous avez sélectionné "AWS Profile", sélectionnez le profil AWS approprié dans le menu déroulant. Si vous avez sélectionné "AWS Access Key", entrez l'ID de clé d'accès et la clé d'accès secrète appropriés.
- Dans la section "Connection Settings", sélectionnez la région appropriée.
- Cliquez sur "Connect".
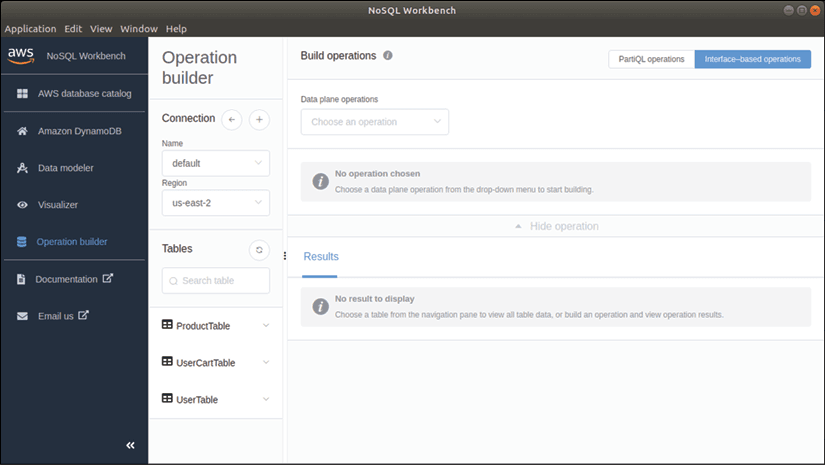
Une fois connecté, vous devriez voir une liste des tables DynamoDB disponibles dans votre compte AWS. Vous pouvez maintenant interroger les données dans une table et générer du code pour lire et écrire des données.
Nous sommes actuellement en mode générateur d'opérations, affiché sur le panneau de gauche, avec les trois tables affichées dans la liste des tables. Pour construire une opération PUT, ou putItem, sur la table ProductTable avec les attributs spécifiés, sélectionnons l'opération PutItem dans le panneau Build operations et choisissons ProductTable. Comme ProductTable a une clé primaire nommée id, le champ Clé de partition doit être spécifié.
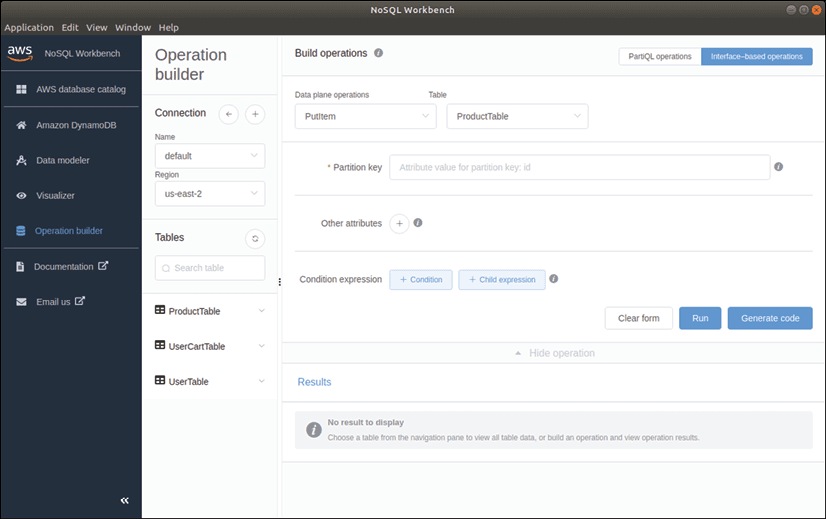
Nous pouvons ajouter d'autres attributs à cette opération PUT en cliquant sur le bouton + à côté de "Autres attributs" et en spécifiant un nom d'attribut, un type d'attribut et une valeur d'attribut.
L'écran comporte un bouton Exécuter dans le coin inférieur droit pour exécuter cette opération et insérer des données dans la table, mais pour générer du code, cliquons sur le bouton Générer du code, qui produira des exemples de code Python, JavaScript et Java dans trois onglets en bas de l'écran.
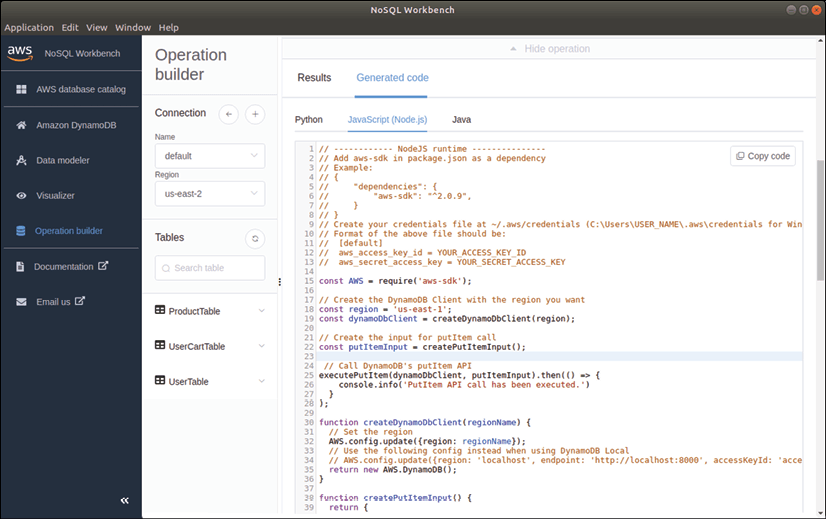
En sélectionnant l'onglet JavaScript, le code généré a trois objectifs principaux :
- Créer une connexion à la base de données.
- Construire une instruction putItem.
- Exécuter cette instruction.
Concentrons-nous sur le deuxième objectif :
function createPutItemInput(
productId: string,
productName: string,
productType: string,
price: number
) {
return {
"TableName": "ProductTable",
"Item": {
"id": {
"S": `${productId}`
},
"name": {
"S": `${productName}`
},
"type": {
"S": `${productType}`
},
"price": {
"N": `${price}`
}
}
}
}
La fonction createPutItemInput renvoie un objet avec une propriété TableName, qui est la table dans laquelle les données seront insérées, et une propriété Item, qui contient des propriétés enfants pour chacun des champs de la table que nous essayons d'insérer.
Une fois que l'objet peut être utilisé pour insérer des valeurs dans la table, nous pouvons porter notre attention sur le code généré qui exécute l'instruction d'insertion :
const region = 'us-east-2';
const dynamoDbClient = createDynamoDbClient(region);
function createDynamoDbClient(regionName) {
// Set the region
AWS.config.update({region: regionName});
return new AWS.DynamoDB();
}
// Create the input for putItem call
const putItemInput =
createPutItemInput("1", "Holy Panda", "Tactile", 1.90);
async function executePutItem(dynamoDbClient, putItemInput) {
// Call DynamoDB's putItem API
try {
const putItemOutput =
await dynamoDbClient.putItem(putItemInput).promise();
console.info('Successfully put item.');
// Handle putItemOutput
} catch (err) {
handlePutItemError(err);
}
Nous avons créé une constante nommée dynamoDbClient, qui est le résultat de l'appel de la fonction createDynamoDbClient avec une région en argument. La fonction createDynamoDbClient appelle la fonction AWS.config.update, puis renvoie une nouvelle instance de la classe AWS.
Point de terminaison de l'API
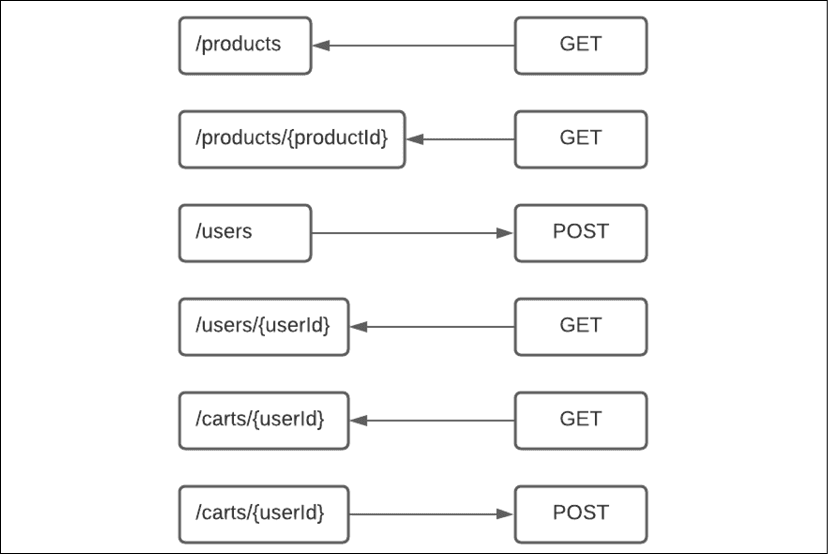
Voici les différents endpoints pour notre API :
- GET /products : récupère tous les produits disponibles à la vente.
- GET /products/{productId} : récupère un produit spécifique.
- POST /users : utilisé lorsqu'un utilisateur s'enregistre auprès de l'application.
- GET /users/{userId} : récupère les données d'un utilisateur particulier.
- GET /carts/{userId} : récupère le contenu du panier de l'utilisateur. Un appel POST permettra de mettre à jour le contenu du panier.
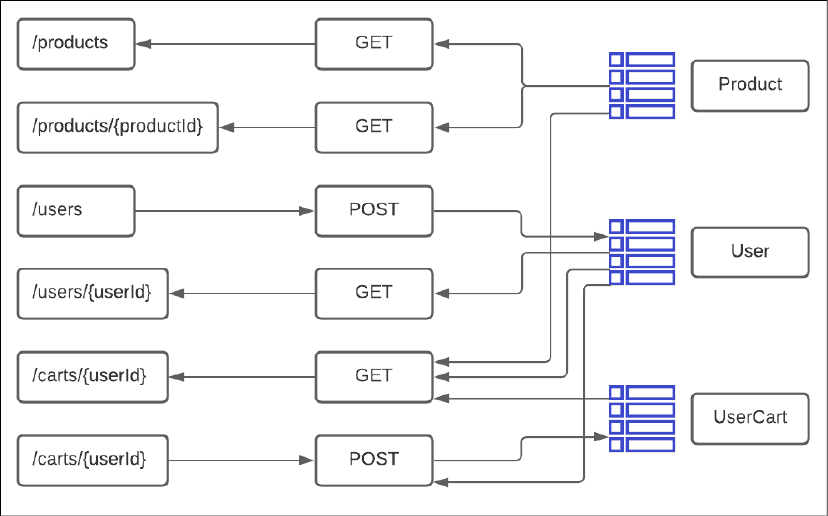
Le schéma suivant illustre le mapping des tables de base de données utilisées par chaque appel d'API :
Une fonction Lambda
Nous allons commencer par le point de terminaison /users de notre API POST. Pour cela, nous devons définir une fonction Lambda dans notre fichier template.yaml comme suit :
UserApiFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: api-handlers/
Handler: users.postHandler
Runtime: nodejs14.x
Events:
UserPostEvent:
Type: Api
Properties:
Path: /users
Method: post
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref UserTable
Nous avons défini une section avec le nom UserApiFunction et le type AWS::Serverless::Function. Nous avons configuré quelques propriétés pour cette fonction sans serveur, y compris le chemin de notre fichier de gestionnaire, le nom de la fonction que nous allons utiliser, le type de runtime (nodejs14.x), et les événements que nous souhaitons surveiller. Nous avons également spécifié une stratégie d'accès DynamoDBCrudPolicy qui accorde à cette fonction Lambda des droits CRUD sur la table spécifiée.
import {
APIGatewayProxyEvent,
Context
} from 'aws-lambda';
import { dynamoDbClient } from './db-functions';
export const postHandler = async (
event: APIGatewayProxyEvent, context: Context
) => {
let response = {};
try {
let bodyJson = JSON.parse(<string>event.body);
let username: string = bodyJson.username;
let password: string = bodyJson.password;
await dynamoDbClient.putItem({
"TableName": "UserTable",
"Item": {
"username": {
"S": username
},
"password": {
"S": password
}
},
"ConditionExpression": "attribute_not_exists(#3f9c0)",
"ExpressionAttributeNames": {
"#3f9c0": "username"
}
}).promise();
response = {
'statusCode': 200,
'body': `User created`
}
} catch (err) {
console.log(err);
// return err;
response = {
'statusCode': err.statusCode,
'body': `${err.message} : an item with this id already exists`
}
}
return response;
};
Dans notre fichier api-handlers/users.js, nous avons exporté une fonction nommée postHandler, qui prend deux paramètres : event de type APIGatewayProxyEvent et context de type Context. Nous avons utilisé la bibliothèque aws-lambda pour importer ces types dans notre code.
Notre fonction Lambda commence en créant une variable bodyJson qui est le résultat de JSON.parse(event.body) pour extraire les valeurs de username et password de la requête POST.
Notre fonction Lambda appelle ensuite une fonction putItem sur notre connexion dynamoDbClient pour stocker les informations dans la UserTable. Nous avons inclus une propriété ConditionExpression pour s'assurer qu'une entrée avec le même nom d'utilisateur n'existe pas déjà dans la table. Nous avons également utilisé l'interface graphique NoSQL Workbench pour générer le code dont nous avons besoin pour cette expression conditionnelle.
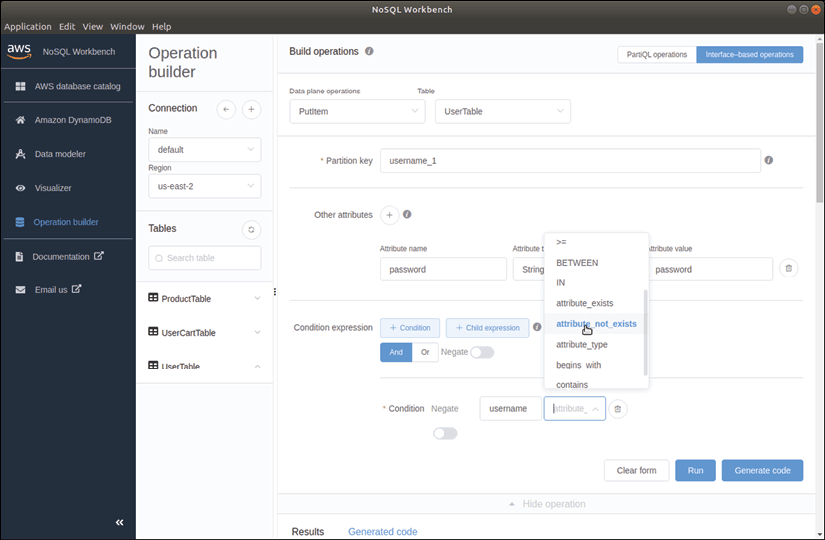
Notre fonction Lambda renvoie un objet avec un statusCode 200 et un body "User Created" si l'opération putItem réussit. Si elle enfreint la condition attribute_not_exists, notre clause catch sera déclenchée et répondra avec un ensemble statusCode pour le code d'état d'erreur et un message.
Compiler la lambda
Pour compiler notre code TypeScript en JavaScript pour nos fonctions lambda, nous devons créer un environnement TypeScript et Node dans le sous-répertoire api-handlers. Pour ce faire, nous pouvons exécuter les commandes suivantes dans le terminal :
cd api-handlers
npm init
tsc --init
npm install aws-sdk
npm install aws-lambda
npm install @types/aws-lambda --save-dev
La première commande nous permet de naviguer dans le répertoire api-handlers, la seconde initialise un nouveau projet Node.js et crée un fichier package.json. La troisième commande crée un fichier tsconfig.json qui permet de configurer le compilateur TypeScript et la dernière commande installe les packages aws-sdk et aws-lambda, ainsi que les types pour aws-lambda.
Il est important de noter que le runtime Node.js que nous utiliserons dans AWS est la version 14, qui prend en charge des versions JavaScript plus récentes que les navigateurs. Pour cette raison, nous pouvons modifier la propriété target dans notre fichier tsconfig.json à target ES2019, qui générera du JavaScript ES2019 à utiliser dans nos Lambdas. Cela simplifiera le JavaScript généré pour nos fonctions Lambda.
Exécuter Lambdas localement
Lorsque nous développons des fonctions Lambda pour AWS, nous devons les déployer sur le cloud avant de pouvoir les tester. Cependant, cela peut prendre du temps et peut être coûteux. Pour éviter cela, nous pouvons utiliser l'interface de ligne de commande SAM (Serverless Application Model) pour exécuter nos fonctions Lambda localement sur notre machine.
La commande:
sam local start-api
Permet d'exécuter les fonctions Lambda localement sur notre machine sans avoir besoin de les déployer sur AWS. Une fois que nous avons exécuté cette commande, nous pouvons voir quelles fonctions API sont disponibles, leurs points de terminaison, et les méthodes HTTP qu'elles supportent.
Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET]
Mounting UserApiFunction at http://127.0.0.1:3000/users [POST]
You can now browse to the above endpoints to invoke your functions.
2021-02-13 17:10:29 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)
Dans l'exemple donné, nous avons deux fonctions Lambda exécutées sur le port 3000, avec un gestionnaire GET au point de terminaison /hello et un gestionnaire POST au point de terminaison /users.
Pour tester notre fonction Lambda, nous pouvons utiliser un outil tel que Postman pour générer un événement POST. Pour ce faire, nous fournissons l'URL de notre point de terminaison /users et spécifions le type de contenu à application/json. Nous devons également inclure une charge utile JSON dans le corps de la demande. Après avoir envoyé la requête, notre point de terminaison /users devrait répondre avec un message 200 OK et afficher le message "User created" dans la réponse.
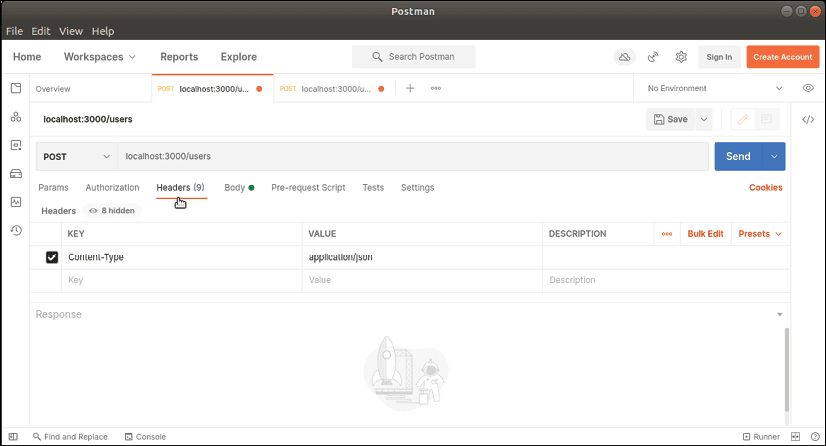
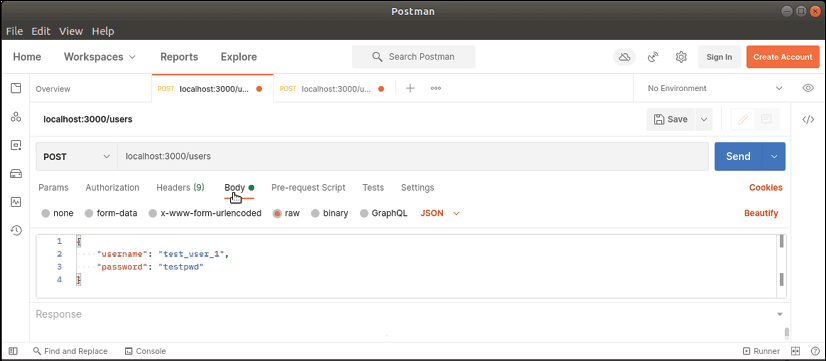
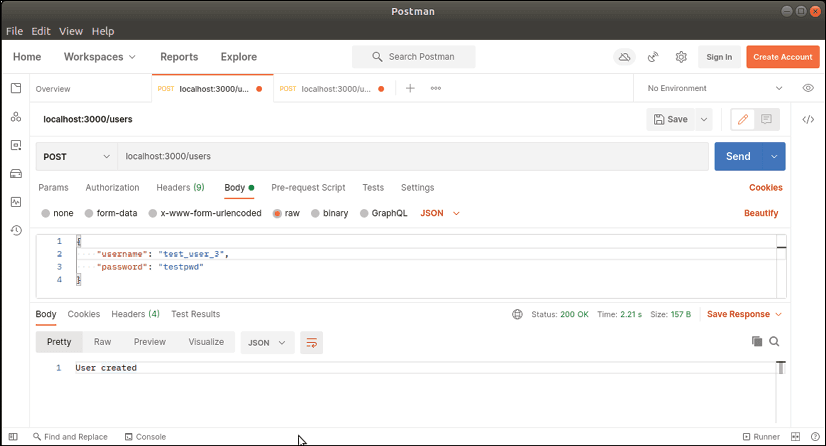
En utilisant l'interface de ligne de commande SAM pour exécuter nos fonctions Lambda localement, nous pouvons économiser du temps et de l'argent en évitant de déployer sur AWS avant de pouvoir tester. Cela peut également aider à accélérer le processus de développement en permettant aux développeurs de tester rapidement et efficacement leurs fonctions Lambda.
Paramètres de chemin lambda
Les paramètres de chemin Lambda permettent de gérer les requêtes avec des paramètres spécifiques dans l'URL.
UserGetApiFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: api-handlers/
Handler: users.getHandler
Runtime: nodejs14.x
Events:
HelloWorld:
Type: Api
Properties:
Path: /users/{userId}
Method: get
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref UserTable
Pour supporter cette syntaxe, nous avons modifié la définition de notre fonction GET Lambda dans notre fichier template.yaml. Nous avons spécifié que la fonction de gestionnaire s'appelle getHandler, et que la propriété Path utilise la syntaxe de substitution pour indiquer que cette fonction API gère tout ce qui correspond à une requête GET au chemin /users/{userId}.
Avant d'écrire le gestionnaire, nous avons créé une fonction utilitaire appelée userExists pour vérifier si l'utilisateur existe dans notre base de données DynamoDB.
export async function userExists(
username: string
): Promise<boolean> {
const scanOutput = await dynamoDbClient.scan({
"TableName": "UserTable",
"ConsistentRead": false,
"FilterExpression": "#87ea0 = :87ea0",
"ExpressionAttributeValues": {
":87ea0": {
"S": `${username}`
}
},
"ExpressionAttributeNames": {
"#87ea0": "username"
}
}).promise();
if (scanOutput.Items && scanOutput.Items?.length > 0) {
return true;
} else {
return false;
}
}
Cette fonction effectue une recherche dans la table UserTable pour trouver les enregistrements avec un champ username égal à la valeur fournie.
<pre>
<code id="htmlViewer" style="color:rgb(220, 220, 220); font-weight:400;background-color:rgb(30, 30, 30);background:rgb(30, 30, 30);display:block;padding: .5em;"><span style="color:rgb(86, 156, 214); font-weight:400;">export</span> <span style="color:rgb(86, 156, 214); font-weight:400;">const</span> <span class="hljs-title function_">getHandler</span> = <span style="color:rgb(86, 156, 214); font-weight:400;">async</span> (<span style="color:rgb(220, 220, 220); font-weight:400;">
event: APIGatewayProxyEvent, context: Context
</span>) => {
<span style="color:rgb(86, 156, 214); font-weight:400;">let</span> response = {};
<span style="color:rgb(86, 156, 214); font-weight:400;">try</span> {
<span style="color:rgb(86, 156, 214); font-weight:400;">let</span> userId = (<<span style="color:rgb(78, 201, 176); font-weight:400;">any</span>>event.<span style="color:rgb(220, 220, 220); font-weight:400;">pathParameters</span>).<span style="color:rgb(220, 220, 220); font-weight:400;">userId</span>;
<span style="color:rgb(86, 156, 214); font-weight:400;">let</span> isUser = <span style="color:rgb(86, 156, 214); font-weight:400;">await</span> <span class="hljs-title function_">userExists</span>(userId);
<span style="color:rgb(86, 156, 214); font-weight:400;">if</span> (isUser) {
response = {
<span style="color:rgb(214, 157, 133); font-weight:400;">'statusCode'</span>: <span style="color:rgb(184, 215, 163); font-weight:400;">200</span>,
<span style="color:rgb(214, 157, 133); font-weight:400;">'body'</span>: <span style="color:rgb(214, 157, 133); font-weight:400;">`User exists`</span>
}
} <span style="color:rgb(86, 156, 214); font-weight:400;">else</span> {
response = {
<span style="color:rgb(214, 157, 133); font-weight:400;">'statusCode'</span>: <span style="color:rgb(184, 215, 163); font-weight:400;">404</span>,
<span style="color:rgb(214, 157, 133); font-weight:400;">'body'</span>: <span style="color:rgb(214, 157, 133); font-weight:400;">`Not found`</span>
}
}
} <span style="color:rgb(86, 156, 214); font-weight:400;">catch</span> (err) {
<span class="hljs-variable language_">console</span>.<span class="hljs-title function_">log</span>(err);
<span style="color:rgb(87, 166, 74); font-weight:400;">// return err;</span>
response = {
<span style="color:rgb(214, 157, 133); font-weight:400;">'statusCode'</span>: err.<span style="color:rgb(220, 220, 220); font-weight:400;">statusCode</span>,
<span style="color:rgb(214, 157, 133); font-weight:400;">'body'</span>:
<span style="color:rgb(214, 157, 133); font-weight:400;">`<span style="color:rgb(220, 220, 220); font-weight:400;">${err.message}</span> : an item with this id already exists`</span>
}
}
<span style="color:rgb(86, 156, 214); font-weight:400;">return</span> response;
};</code></pre>
Dans notre fonction Lambda, nous avons invoqué la fonction userExists pour savoir si le nom d'utilisateur existe dans notre base de données, puis nous avons répondu avec une réponse 200 OK si l'utilisateur est trouvé, et une réponse 404 Not found sinon.
Nous pouvons utiliser Postman pour tester notre fonction Lambda, en envoyant une requête GET avec un paramètre userId spécifique dans l'URL.
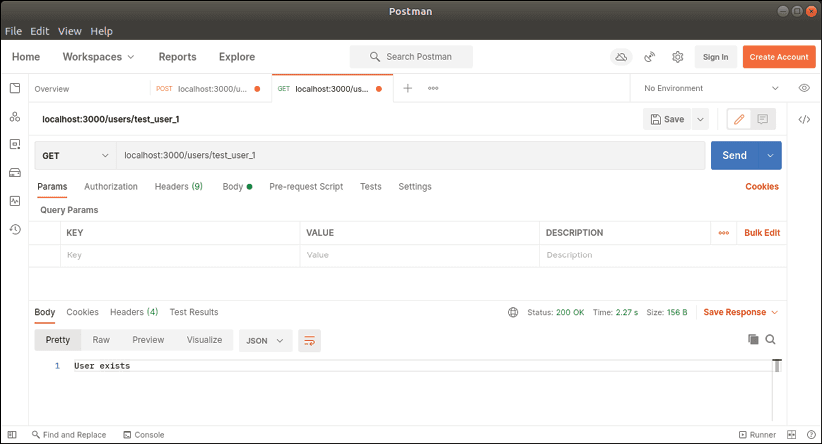
Traitement des enregistrements de la base de données
Notre fonction Lambda gère une requête GET sur le point de terminaison /products.
export const getHandler = async (
event: APIGatewayProxyEvent,
context: Context
) => {
let response = {};
try {
let scanResults =
await executeScan(
dynamoDbClient,
getProductScanParameters()
);
let outputArray = [];
if (scanResults?.Items) {
for (let item of scanResults.Items) {
outputArray.push(getProduct(item));
}
}
response = {
'statusCode': 200,
'body': JSON.stringify(outputArray)
}
} catch (err) {
console.log(err);
return err;
}
return response;
};
Cette fonction Lambda utilise la méthode executeScan pour effectuer une requête sur notre table DynamoDB et renvoyer tous les enregistrements.
Si la requête sur la base de données renvoie des enregistrements, nous parcourons chaque enregistrement et appelons la fonction getProduct avec cet enregistrement de base de données pour le convertir en un objet IProduct. La fonction getProduct prend un objet de type AttributeMap renvoyé par DynamoDB et le convertit en un objet de type IProduct. La fonction retourne l'objet IProduct.
export function getProduct(item: DynamoDB.AttributeMap): IProduct {
let product: IProduct = {
id: parseInt(<string>item["id"].S),
name: <string>item["name"].S,
type: <string>item["type"].S,
image: <string>item["image"].S,
longDescription: <string>item["longDescription"].S,
specs: {
actuationForce: <string>item["actuationForce"].N,
actuationPoint: <string>item["actuationPoint"].N,
bottomOut: <string>item["bottomOut"].N,
bottomOutTravel: <string>item["bottomOutTravel"].N,
price:
item["price"].N ?
(parseInt(item["price"].N) / 100)
.toFixed(2) : "",
}
}
return product;
}
Notre fonction Lambda renvoie une réponse 200 OK avec une collection d'objets IProduct sous forme de chaîne JSON. Nous pouvons tester cette fonction en envoyant une requête GET sur notre point de terminaison /products. La réponse renvoyée doit contenir tous les produits stockés dans notre table DynamoDB.
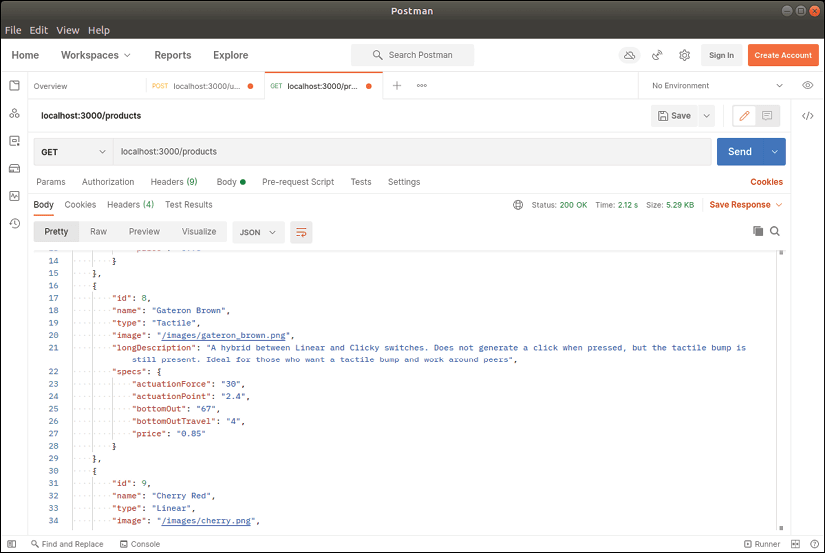
Conclusion
Nous avons exploré l'architecture d'une fonction AWS Lambda et appris à utiliser l'interface de ligne de commande SAM pour générer, déployer et exécuter des fonctions Lambda localement. Nous avons également discuté de la base de données NoSQL DynamoDB et travaillé sur des exemples d'utilisation de NoSQL Workbench pour générer du code pour interagir avec nos données.
Nous avons créé plusieurs fonctions Lambda basées sur TypeScript, qui ont utilisé soit les données envoyées dans le cadre d'une opération POST, soit des paramètres de chemin pour guider leur comportement. Nous avons également couvert la syntaxe de substitution dans la définition de notre fonction API, qui nous permet d'utiliser des paramètres de chemin pour gérer les requêtes avec des paramètres spécifiques dans l'URL.
Enfin, nous avons appris à tester nos fonctions Lambda à l'aide d'outils tels que Postman, en envoyant des requêtes HTTP à nos points de terminaison API pour vérifier que nos fonctions renvoient les réponses attendues.





