 Français
FrançaisLes auto encodeurs
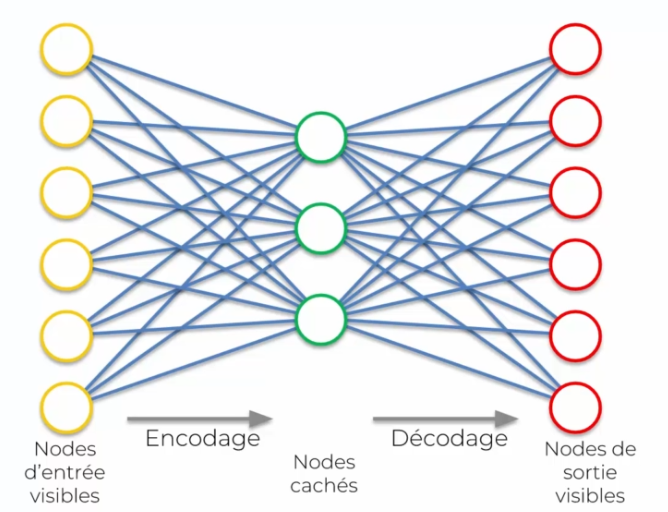
Les auto-encodeurs sont une sorte d'algorithme qui utilise des réseaux de neurones pour compresser des données d'entrée dans une représentation plus petite, puis les décompresser pour les récupérer. Le but est de faire en sorte que la sortie soit le plus proche possible de l'entrée originale. Cela permet de détecter des caractéristiques ou des "features" spécifiques.
Le processus se déroule en deux étapes : d'abord, l'entrée est encodée dans une couche cachée, puis la couche cachée est décodée pour obtenir la sortie. Chaque neurone dans le réseau se spécialise pour trouver des caractéristiques spécifiques dans les données.
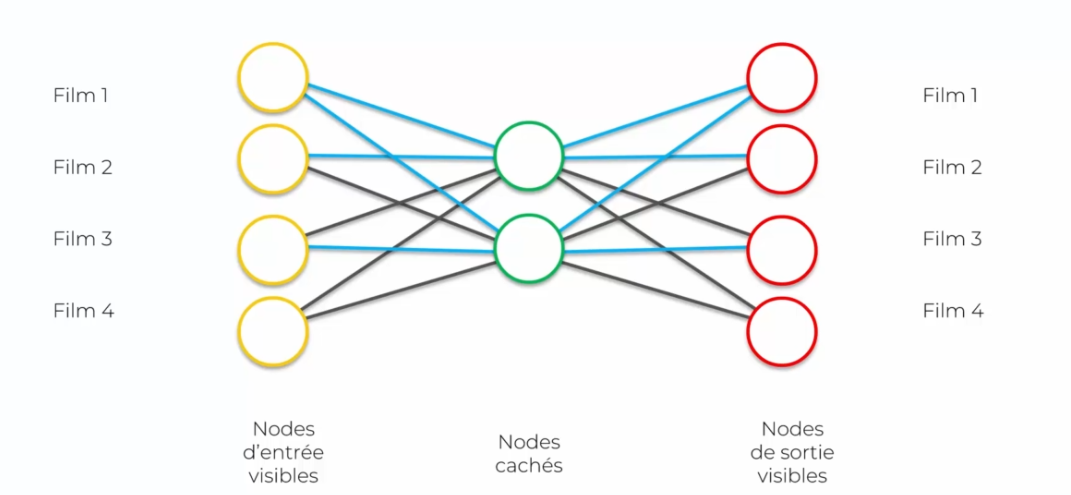
Les auto-encodeurs peuvent être utilisés pour encoder des données précises, comme un système de recommandation pour les films ou la musique. Par exemple, si vous entrez 6 types de musique différents, l'auto-encodeur les encodera dans une représentation plus petite. Lorsque vous voulez récupérer ces données, l'auto-encodeur les décodera pour vous les donner en sortie.
Le but de cet exemple est de montrer comment l'encodage des films en entrée peut être restitué intact à la sortie, sans perte d'informations. Dans cet exemple, un utilisateur a noté les films qu'il a regardés.
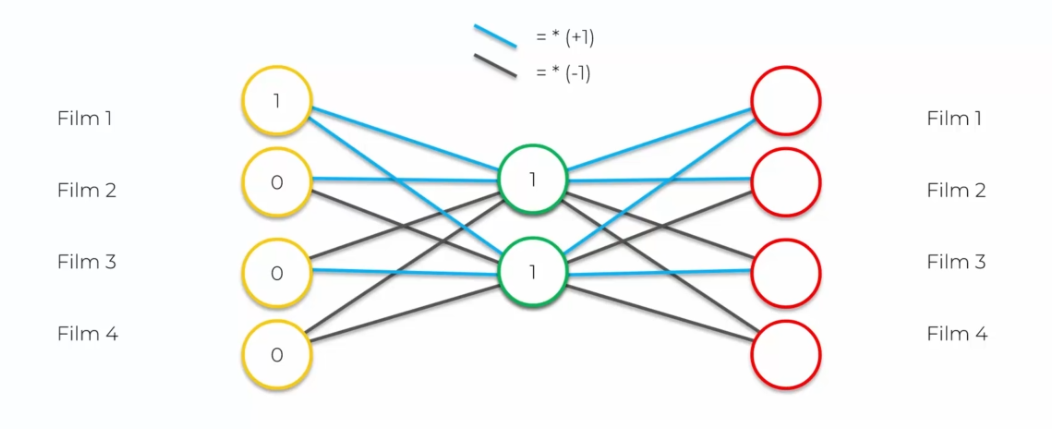
Les synapses bleues sont égales à 1, on multiplie donc par 1, tandis que les synapses noires sont égales à -1, on multiplie donc par -1. En utilisant ces règles, nous pouvons tracer des liens pour chaque entrée. Dans notre exemple, les entrées sont les films notés, où 1 représente un film apprécié et 0 représente un film non apprécié.
En appliquant les règles pour les synapses, nous pouvons dessiner des liens pour chaque film noté. Dans notre exemple, nous avons :
Film 1 = 1 Film 2 = 0 Film 3 = 0 Film 4 = 0
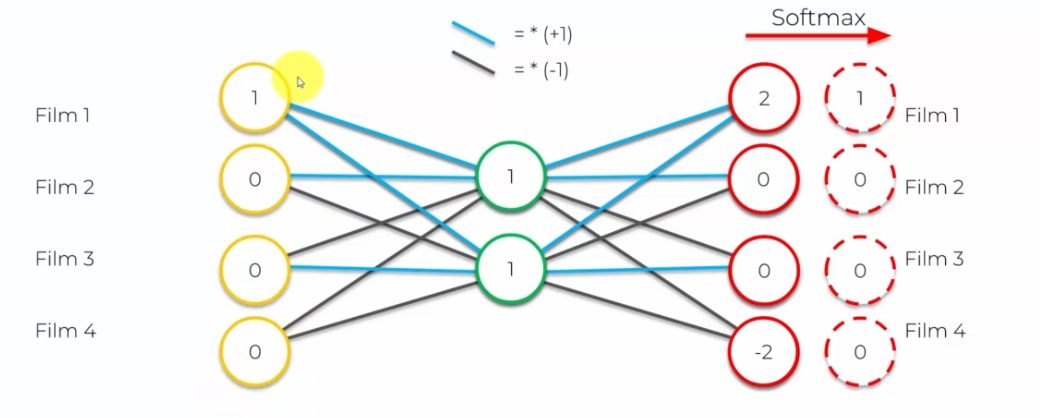
L'encodage de ces films est ensuite passé à travers le réseau de neurones, qui compressera les données en une représentation plus petite, puis les décompressera pour les récupérer. Le but est de récupérer les entrées d'origine sans perte d'informations.
Le premier neurone caché :
- Film 1: 1 (note) * 1 (neurone caché) = 1
- Film 2: (0 (note) * 1 (neurone caché)) + 1 (valeur précédente) = 1
- Film 3: (0 (note) * 1 (neurone caché)) + 1 (valeur précédente) = 1
- Film 4: (0 (note) * 1 (neurone caché)) + 1 (valeur précédente) = 1
On obtient alors 1 et pareil pour le réseau caché sortant
Ensuite on calcule les sorties :
- Film 1: 2 synapses bleus donc : 1 *1 + 1 * 1 = 2
- Film 2: 1 sypnase bleu et 1 synapse noir donc: 1*1 + 1 * -1 = 0
- Film 3: 1 sypnase bleu et 1 synapse noir donc: 1*1 + 1 * -1 = 0
- Film 4: 2 synapses noirs donc : 1 *-1 + 1 * -1 = -2
Enfin, on applique une fonction appelée softmax pour normaliser les valeurs de sortie. Cette fonction transforme les valeurs nulles ou inférieures à 1 en 0, et les valeurs égales ou supérieures à 1 en 1. Après l'application de softmax, on obtient les mêmes valeurs en sortie qu'en entrée.
L'entrainement
L'entrainement d'un auto-encodeur pour la recommandation de films peut être décrite en plusieurs étapes :
-
Etape 1 : Le processus commence avec un tableau qui contient toutes les notes données par les utilisateurs à différents films. Chaque entrée contient une note (de 1 à 5) pour un film donné par un utilisateur spécifique. Si un utilisateur n'a pas évalué un film, la valeur de cette entrée est 0.
-
Etape 2 : Le premier utilisateur entre dans le réseau. Le vecteur d'entrée x contient toutes les notes pour tous les films notés par cet utilisateur.
-
Etape 3 : Le vecteur d'entrée x est encodé en un vecteur z de dimension inférieure en utilisant une fonction de mappage f, comme la fonction sigmoïde. Cela permet de compresser les données.
-
Etape 4 : Le vecteur z est ensuite décodé en un vecteur Y de même dimension que X. L'objectif est de répliquer le vecteur X en sortie, en utilisant le processus de décodage.
-
Etape 5 : L'erreur de reconstruction d(x,y) = ||x-y|| est calculée, ce qui permet de mesurer la différence entre l'entrée et la sortie.
-
Etape 6 : La rétropropagation de l'erreur se fait de droite à gauche pour mettre à jour les poids dans le réseau. Le taux d'apprentissage détermine l'ampleur des mises à jour de poids.
-
Etape 7 : Les étapes de 1 à 6 sont répétées pour chaque utilisateur. Les poids sont mis à jour après chaque observation (apprentissage en ligne) ou après chaque groupe d'observations (apprentissage par batch).
-
Etape 8 : Une fois que tout le jeu d'entraînement a été passé dans le réseau, cela crée une époque. Il est recommandé de répéter le processus pour plusieurs époques pour améliorer la précision de la recommandation.
Les auto-encodeurs pour la recommandation de films utilisent un processus d'encodage et de décodage pour comprimer les données et répliquer les vecteurs d'entrée en sortie. L'apprentissage se fait par rétropropagation de l'erreur et les poids sont mis à jour pour chaque utilisateur. Les résultats sont améliorés en effectuant plusieurs époques de formation.
Couche cachée trop grande
Si l'on augmente le nombre de neurones dans la couche cachée par rapport à la couche d'entrée, cela permettrait au modèle de capturer des caractéristiques plus complexes et plus abstraites des données d'entrée. Cela pourrait aider à améliorer la précision de la recommandation, car le modèle aurait une capacité de représentation plus élevée et serait capable de capturer des nuances plus subtiles des préférences de l'utilisateur.
Cependant, l'ajout de plus de neurones peut également augmenter le risque de surapprentissage (overfitting), où le modèle s'adapte trop bien aux données d'entraînement et ne généralise pas bien aux données de test. Pour éviter cela, il est important d'utiliser des techniques de régularisation, telles que la suppression de certaines synapses ou l'ajout de bruit, ainsi que de valider régulièrement les performances du modèle sur des données de test.
Pour remédier à cela, on utilise des auto-encodeurs. Voici quelques types d'auto-encodeurs :
-
Auto-encodeurs épars : Ces auto-encodeurs utilisent une technique appelée Dropout pour empêcher le surapprentissage. Cette technique consiste à désactiver aléatoirement certains neurones pendant l'apprentissage pour éviter que le modèle ne s'habitue trop aux données d'entrée.
-
Auto-encodeurs débruiteurs : Ces auto-encodeurs modifient légèrement les données d'entrée pour éviter le surapprentissage. Cela se fait en ajoutant du bruit à l'entrée, comme un flou, pour que le modèle ne puisse pas simplement copier les données en entrée en sortie.
-
Auto-encodeurs contractifs : Ces auto-encodeurs ajoutent une pénalité à la fonction de coût qui interdit au réseau de copier simplement les données en entrée en sortie. Si le réseau copie, il sera plus sévèrement pénalisé.
-
Auto-encodeurs empilés : Ces auto-encodeurs ajoutent une nouvelle couche cachée au lieu de nouveaux neurones dans la même couche. Cela crée un double encodage et permet d'avoir un double filtre pour détecter des caractéristiques.
-
Auto-encodeurs profonds : Ces auto-encodeurs empilent des machines de Boltzmann restreintes, qu'on entraîne couche par couche, puis qu'on réajuste avec la rétropropagation. Cela permet d'obtenir une structure plus complexe et plus profonde pour extraire des informations plus riches des données d'entrée.
En résumé, les auto-encodeurs sont une famille de réseaux de neurones utilisés pour éviter le surapprentissage et pour extraire des caractéristiques pertinentes des données d'entrée. Ils peuvent utiliser diverses techniques, comme le Dropout, le débruitage, la pénalité de la fonction de coût, l'empilement de couches cachées et la construction de réseaux profonds, pour améliorer la qualité de la représentation des données et augmenter la précision des prédictions.





