 Français
FrançaisIntroduction
Dans cette section, nous allons :
- Expliquer les variables d'environnement prédéfinies
- Améliorer les performances en utilisant des caches
- Déployer des applications par environnements
- Générer un déploiement manuel
Ces sujets sont les principaux thèmes de cette partie.
Variable prédefinie
Git Branch: CI/CDVersion
GitLab CI/CD a des variables d'environnement prédéfinies par défaut. Pourquoi devrions-nous les connaître ? Eh bien, il se peut que nous ayons besoin de les modifier ou de les afficher, comme le SHA pour l'afficher dans l'HTML. Voici un exemple : si nous voulons remplacer la version dans le fichier index.js de notre projet Gatsby :
<main style={pageStyles}>
<title>Home Page</title>
<h1 style={headingStyles}>
Congratulations
<br />
<span style={headingAccentStyles}>— you just made a Gatsby site! </span>
<span role="img" aria-label="Party popper emojis">
🎉🎉🎉
</span>
</h1>
<p style={paragraphStyles}>
Edit <code style={codeStyles}>src/pages/index.js</code> to see this page
update in real-time.{" "}
<span role="img" aria-label="Sunglasses smiley emoji">
😎
</span>
</p>
<ul style={listStyles}>
<li style={docLinkStyle}>
<a
style={linkStyle}
href={`${docLink.url}?utm_source=starter&utm_medium=start-page&utm_campaign=minimal-starter`}
>
{docLink.text}
</a>
</li>
{links.map(link => (
<li key={link.url} style={{ ...listItemStyles, color: link.color }}>
<span>
<a
style={linkStyle}
href={`${link.url}?utm_source=starter&utm_medium=start-page&utm_campaign=minimal-starter`}
>
{link.text}
</a>
{link.badge && (
<span style={badgeStyle} aria-label="New Badge">
NEW!
</span>
)}
<p style={descriptionStyle}>{link.description}</p>
</span>
</li>
))}
</ul>
<img
alt="Gatsby G Logo"
src="data:image/svg+xml,%3Csvg width='24' height='24' fill='none' xmlns='http://www.w3.org/2000/svg'%3E%3Cpath d='M12 2a10 10 0 110 20 10 10 0 010-20zm0 2c-3.73 0-6.86 2.55-7.75 6L14 19.75c3.45-.89 6-4.02 6-7.75h-5.25v1.5h3.45a6.37 6.37 0 01-3.89 4.44L6.06 9.69C7 7.31 9.3 5.63 12 5.63c2.13 0 4 1.04 5.18 2.65l1.23-1.06A7.959 7.959 0 0012 4zm-8 8a8 8 0 008 8c.04 0 .09 0-8-8z' fill='%23639'/%3E%3C/svg%3E"
/>
<div>Version: %%version%%</div>
</main>
Nous pouvons facilement remplacer %%version%% par le numéro de commit en utilisant la variable d'environnement pré-définie $CI_COMMIT_SHA :
build website:
stage: build
script:
- echo $CI_COMMIT_SHORT_SHA
- cd ./my-gatsby-site
- npm install
- npm run build
- sed -i "s/%%version%%/$CI_COMMIT_SHORT_SHA/" ./my-gatsby-site/public/index.html
artifacts:
paths:
- ./my-gatsby-site/public
Nous pouvons créer un test de déploiement qui vérifiera la présence de notre variable. Voici un exemple de script qui utilise la variable d'environnement pré-définie $CI_ENVIRONMENT_SLUG pour déterminer l'URL de déploiement et la variable personnalisée $MY_VARIABLE pour vérifier la présence de notre variable :
test deployment:
image: alpine
stage: deployment tests
script:
- apk add --no-cache curl
- curl -s "https://curious-shock.surge.sh" | grep -q "Hi people"
- curl -s "https://curious-shock.surge.sh" | grep -q "$CI_COMMIT_SHORT_SHA"
Nous avons donc une solution afin de s'assurer que tout fonctionne comme espéré.
Utilisation de caches
Git Branch: CI/CDCache
Télécharger des dépendances peut prendre un temps considérable. Si on compare avec Jenkins, Gitlab supprime les données après chaque exécution, ce qui rend l'exécution plus rapide.
Pourquoi Gitlab supprime-t-il ces données ? Cela vient de l'architecture. L'objectif est d'isoler les jobs et de ne pas sauvegarder des dépendances externes dans les dépôts. On utilise des caches pour accélérer l'exécution des pipelines.
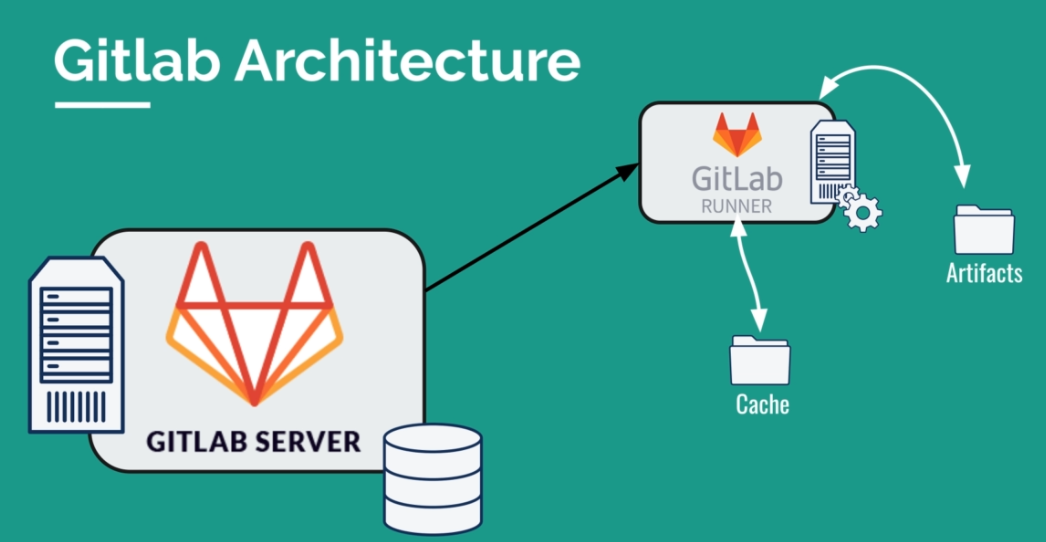
Le plan d'attaque consiste à :
- Définir un objet "cache" dans le fichier YAML
- Définir cet objet de manière globale pour chaque job utilisant node comme image
- Utiliser une clé unique pour identifier cet objet, basée sur la variable prédéfinie du commit "CI_COMMIT_REF_SLUG"
- Spécifier les chemins à sauvegarder dans l'objet cache. Dans notre cas, nous voulons sauvegarder "node_modules". Notez que nous pouvons enregistrer plusieurs dossiers ou fichiers sur demande.
Le fait de supprimer les données après chaque exécution dans Gitlab est dû à l'architecture. Pour accélérer l'exécution des pipelines, nous utilisons des caches pour sauvegarder les dépendances partagées entre les jobs. Pour cela, nous devons définir un objet "cache" dans le fichier YAML, le définir de manière globale pour chaque job utilisant node comme image, utiliser une clé unique pour identifier cet objet basée sur la variable prédéfinie du commit "CI_COMMIT_REF_SLUG", et spécifier les chemins à sauvegarder dans l'objet cache, tels que "node_modules".
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- node_modules/
Lorsque vous rencontrez l'erreur "FATAL: file does not exist" sur Gitlab, cela signifie que Gitlab vérifie si le cache existe ou non. Vous pouvez voir dans les logs que le fichier de cache est créé et ajouté à un fichier "cache.zip".
Ensuite, pour chacun des jobs utilisant node, le cache est chargé, ce qui améliore les performances.
Cependant, quelle est la différence entre le cache et les artifacts ?
Ils ont une configuration similaire, mais ne fonctionnent pas de la même manière :
| Artifacts | Cache |
|---|---|
| Souvent utilisé pour stocker le résultat d'un build | N'est pas utilisé pour stocker les résultats d'un build |
| Peut être utilisé pour transférer certaines données d'un job à l'autre | Il doit être utilisé uniquement comme un stockage temporaire pour les dépendances |
Deployer par environnement
Git Branch: CI/CDEnvs
Actuellement, nous déployons des applications directement en production, mais en réalité, l'objectif est de tester l'application avant son déploiement en production. Pour cela, nous allons créer un environnement de "staging".
stages:
- build
- test
- deploy staging
- deploy production
- production tests
Nous allons déployer dans un premier temps en staging, avant de déployer en production. Nous pouvons renommer nos différents stages :
- "deploy" devient "deploy production"
- "deployment tests" devient "production tests"
Maintenant, nous allons créer un environnement de staging. L'objectif est de créer une nouvelle URL qui servira de test.
deploy staging:
stage: deploy staging
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://foregoing-quiet-staging.surge.sh
L'environnement de staging est similaire à l'environnement de production, mais il déploie sur une autre URL avant de déployer en production. L'objectif est de créer un contrôle sur le livrable et la procédure de déploiement. Cela permet également un suivi des déploiements, afin de savoir ce qui a été déployé par environnement et quand.
Cependant, il est important de noter que Gitlab n'a pas de notion d'environnement renseigné. Nous devons donc l'informer de l'environnement de staging.
deploy staging:
stage: deploy staging
environment:
name: staging
url: https://foregoing-quiet-staging.surge.sh
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://foregoing-quiet-staging.surge.sh
deploy production:
stage: deploy production
environment:
name: production
url: https://foregoing-quiet.surge.sh
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://foregoing-quiet.surge.sh
Maintenant que Gitlab est au courant des environnements, il est possible de voir les environnements sur Gitlab, le commit déployé, de relancer le build d'un environnement, et bien plus encore. Vous pouvez explorer les différentes fonctionnalités et jouer avec celles-ci pour mieux comprendre comment fonctionne Gitlab avec les environnements.

Une amélioration possible serait de définir des variables pour éviter de dupliquer du code. Ces variables peuvent être globales ou locales à un job.
Pour améliorer notre code, commençons par créer nos variables :
variables:
STAGING_DOMAIN: foregoing-quiet-staging.surge.sh
PRODUCTION_DOMAIN: foregoing-quiet.surge.sh
Nous pouvons ensuite très facilement utiliser les variables à la place des différents URLs :
deploy production:
stage: deploy production
environment:
name: production
url: https://$PRODUCTION_DOMAIN
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://$PRODUCTION_DOMAIN
Jusqu'à présent, le système déploie sur deux environnements, mais nous voulons restreindre le déploiement vers la production à un déploiement manuel. En d'autres termes, une fois que les tests en staging sont effectués par le business, nous voulons que le déploiement vers la production ne soit effectué que manuellement. Voici le fonctionnement souhaité :
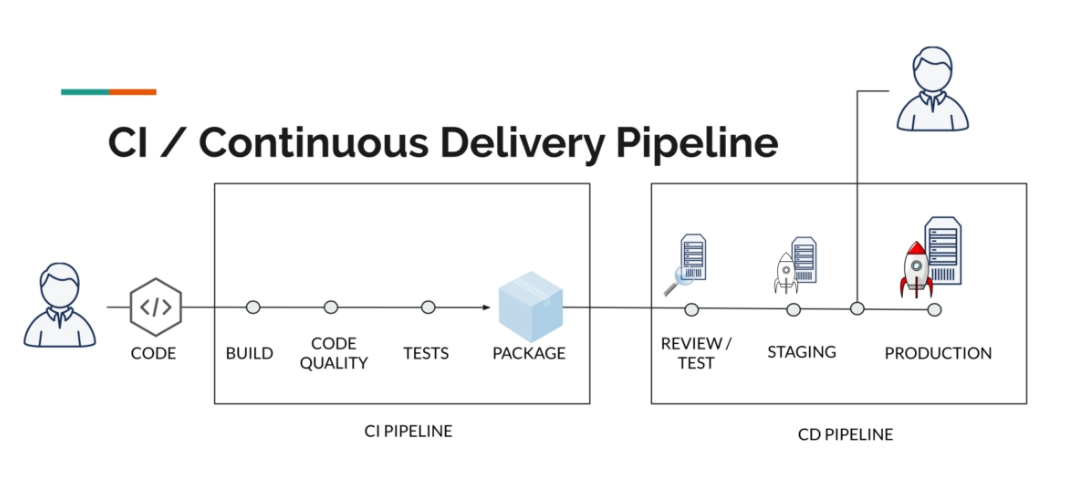
Pour cela, nous devons ajouter la propriété "when" ayant pour valeur "manual" pour informer Gitlab que ce job doit être lancé manuellement :
deploy production:
stage: deploy production
environment:
name: production
url: https://$PRODUCTION_DOMAIN
when: manual
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://$PRODUCTION_DOMAIN
Maintenant nous devrions obtenir ce résultat :
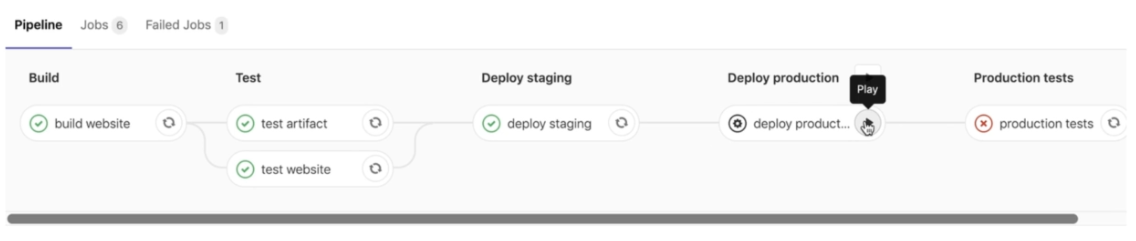
Cependant, une erreur se produit à la dernière étape. Cela est dû au fait que notre job de déploiement en production n'a pas été exécuté. Pour résoudre ce problème, nous devons définir "allow_failure" sur "false" pour que la tâche ne se lance qu'une fois le déploiement lancé. Vous pouvez alors constater que la pipeline obtient le statut "Blocked".
deploy production:
stage: deploy production
environment:
name: production
url: https://$PRODUCTION_DOMAIN
when: manual
allow_failure: false
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://$PRODUCTION_DOMAIN
Nous venons de créer notre pipeline, qui est presque parfaite pour un workflow de production. Cependant, il y a encore un hic ! À chaque branche poussée, un build est créé, ce qui n'est pas vraiment logique. Nous devons créer un déploiement vers staging uniquement lorsque nous poussons sur la branche "master". Pour cela, la propriété "only", qui prend un tableau comme valeur, permet de spécifier quand un job doit s'exécuter :
deploy staging:
stage: deploy staging
environment:
name: staging
url: https://$STAGING_DOMAIN
only:
- master
script:
- npm install --global surge
- cd ./my-gatsby-site
- surge --project public/ --domain https://$STAGING_DOMAIN
Et voilà ! Nous avons configuré notre pipeline pour chaque environnement avec des conditions "ready to prod".
Les environnements dynamiques
Git Branch: CI/CDDynamicEnv
Il serait intéressant de mettre en place des déploiements dynamiques pour chaque merge request, de sorte que nous puissions déployer une version vers un environnement. Cela permet de revoir les changements effectués, de réaliser des tests supplémentaires et de créer un environnement de "Review" utilisable par des non-techniciens. En d'autres termes, il faut créer un environnement par branche pour valider plus rapidement la "feature".
stages:
- build
- test
- deploy review
- deploy staging
- deploy production
- production tests
deploy review:
stage: deploy review
only:
- merge_requests
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://foregoing-quiet-$CI_ENVIRONMENT_SLUG.surge.sh
script:
- npm install --global surge
- surge --project ./public --domain foregoing-quiet-$CI_ENVIRONMENT_SLUG.surge.sh
Nous aurons donc un environnement par branche ! À chaque push, nous pourrons montrer nos différents changements et avancées. Nous avons des environnements dynamiques, mais il n'y a aucun besoin de les garder une fois que la branche a été fusionnée. Pour cela, nous devons créer un job :
stop review:
stage: deploy review
only:
- merge_requests
variables:
GIT_STRATEGY: none
script:
- npm install --global surge
- surge teardown instazone-$CI_ENVIRONMENT_SLUG.surge.sh
when: manual
environment:
name: review/$CI_COMMIT_REF_NAME
action: stop
Ce job s'exécutera lorsque la branche sera fusionnée. Il demandera au CLI de "surge" de détruire l'instance à l'aide de la commande "teardown". Pour éviter une erreur (GIT_STRATEGY), il est nécessaire d'informer Gitlab de ne pas cloner cette branche spécifique qui n'existera plus. Cette action manuelle signifie que le job ne s'exécutera que sur demande et de manière conditionnelle. Ensuite, nous devons fermer l'environnement dans Gitlab. Pour ce faire, il faut lier ce job à celui de la review en utilisant l'événement "on_stop" qui se déclenche lorsque la review est terminée.
deploy review:
stage: deploy review
only:
- merge_requests
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://instazone-$CI_ENVIRONMENT_SLUG.surge.sh
on_stop: stop review
script:
- npm install --global surge
- surge --project ./public --domain instazone-$CI_ENVIRONMENT_SLUG.surge.sh
before_script et after_script
Nous passerons rapidement sur cette configuration, qui permet de réaliser des actions avant et après l'exécution d'un job. Voici un exemple :
before_script:
- npm install --global surge
script:
- surge --project ./public --domain instazone-$CI_ENVIRONMENT_SLUG.surge.sh
after_script:
- echo "Finito"




