 Français
FrançaisIntroduction :
Lors du développement d'un logiciel, il est essentiel de mettre en place un processus de CI/CD pour assurer la qualité du code et faciliter son déploiement en production. Gitlab CI est un outil populaire pour automatiser ce processus, et les pipelines sont une fonctionnalité clé de Gitlab CI.
Les pipelines dans Gitlab CI :
- Les pipelines dans Gitlab CI permettent de définir un ensemble d'actions à exécuter pour valider, construire, tester et déployer un logiciel.
- Les pipelines sont composés de stages, qui représentent les différentes phases du processus de développement et de déploiement.
- Chaque stage est composé de jobs, qui sont des actions à exécuter pour valider une étape du pipeline.
Exemple de pipeline :
- La pipeline peut commencer par une étape de validation, qui vérifie si le code source est correctement formaté et ne contient pas d'erreurs de syntaxe.
- Si la validation réussit, une étape de construction peut être exécutée pour générer l'application à partir du code source.
- Une fois que l'application est construite, une étape de test peut être exécutée pour vérifier son fonctionnement.
- Si les tests réussissent, une étape de déploiement peut être exécutée pour déployer l'application en production.
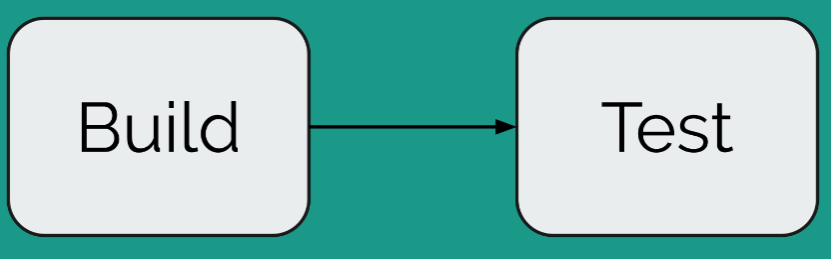
Dans notre cas, notre pipeline consiste en deux étapes : Build et Test. La première étape consiste à lancer le build de notre application et la deuxième étape consiste à lancer les tests fonctionnels ou unitaires de l'application.
Git branch: first-project
Pour commencer, connectez-vous à GitLab et créez un nouveau projet vide nommé "Car assembly line". Les différentes étapes de la formation sont disponibles dans différentes branches, dont le lien se trouve dans la sidebar à droite.
L'objectif de ce chapitre est de créer deux jobs pour notre pipeline sur la branche "first-project". Les deux jobs à créer sont les suivants :
- Un job pour le build de l'application
- Un job pour l'exécution des tests fonctionnels ou unitaires de l'application.
Pour créer un job dans notre pipeline, voici les étapes à suivre :
- Définissez le nom du job que vous souhaitez créer.
- Créez un dossier "build" pour stocker le fichier du job.
- Créez un fichier pour le job.
- Écrivez les différentes étapes du job dans ce fichier.
Une fois que vous avez créé et commité le fichier, GitLab lancera le processus de la pipeline. Pour consulter les résultats de votre pipeline, allez dans la sidebar "CI/CD". Vous y trouverez les résultats de votre job.
Maintenant que le premier job est créé, il est temps de passer à la création du prochain job. Cependant, il est important de comprendre que chaque job est indépendant les uns des autres, ce qui signifie que chaque job ne connaît pas le résultat des autres et que chaque exécution détruit les fichiers et dossiers créés pendant son exécution.
Pour éviter cela, nous pouvons utiliser des "artifacts". Les artifacts permettent de stocker des fichiers générés pendant l'exécution d'un job et de les rendre disponibles pour les jobs suivants.
Ainsi, il sera plus facile de créer le fichier pour le prochain job en utilisant les artifacts générés par le premier job.

Les artifacts sont des fonctionnalités qui permettent de stocker le résultat des différents jobs de la pipeline. Ainsi, les fichiers générés pendant l'exécution d'un job seront conservés et pourront être utilisés par les jobs suivants. Cette fonctionnalité facilite la création des jobs suivants en utilisant les résultats des jobs précédents.
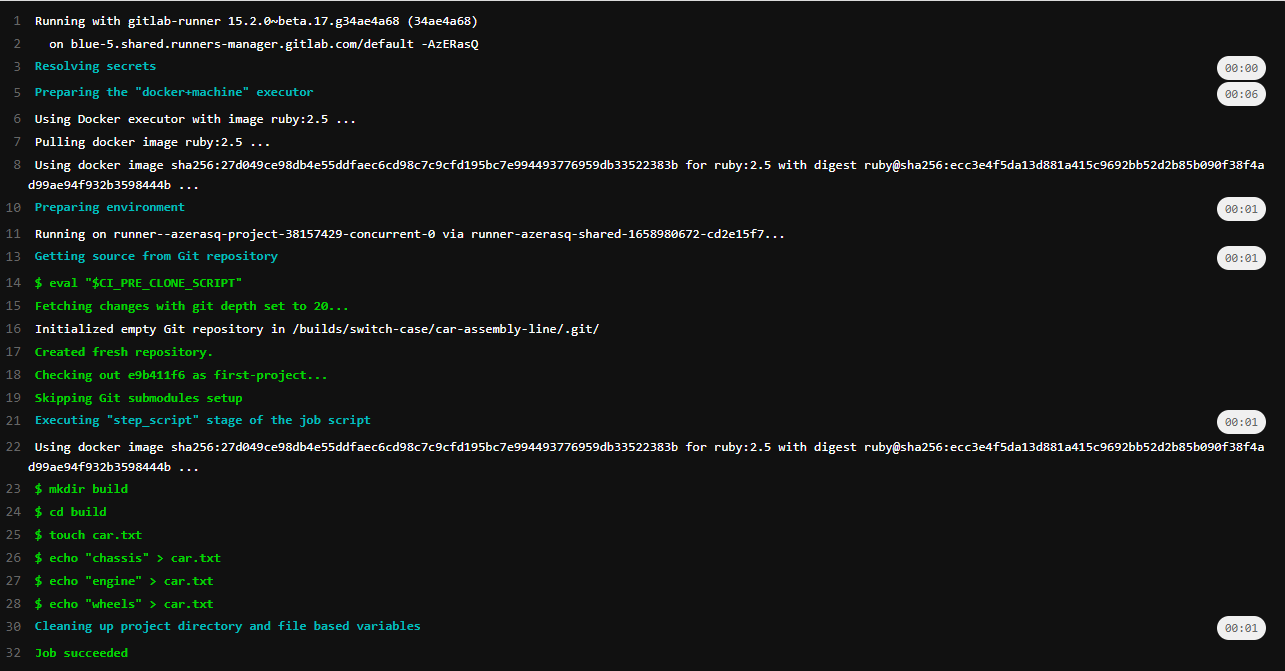
build the car:
script:
- mkdir build
- cd build
- touch car.txt
- echo "chassis" >> car.txt
- echo "engine" >> car.txt
- echo "wheels" >> car.txt
artifacts:
paths:
- build/
test the car:
script:
- ls
- test -f build/car.txt
- cd build
- cat car.txt
- grep "chassis" car.txt
- grep "engine" car.txt
- grep "wheels" car.txt
Pour utiliser les artifacts, vous devez d'abord les définir en spécifiant le chemin où ils se trouvent.
Ensuite, vous pouvez créer le job de testing qui permettra de naviguer jusqu'au fichier et de vérifier que chaque ligne est bien présente dans le fichier.
Cependant, un autre problème se pose : il est important de préciser un ordre pour l'exécution des jobs, car tester le build sans résultat mènera à un échec. Pour résoudre ce problème, nous utilisons la notion de "stages". Chaque job doit être identifié par un ID, dit "stage", qui permettra de définir un ordre dans le tableau "stages". Voici un exemple :
stages:
- build
- test
build the car:
stage: build
script:
- mkdir build
- cd build
- touch car.txt
- echo "chassis" >> car.txt
- echo "engine" >> car.txt
- echo "wheels" >> car.txt
artifacts:
paths:
- build/
test the car:
stage: test
script:
- ls
- test -f build/car.txt
- cd build
- cat car.txt
- grep "chassis" car.txt
- grep "engine" car.txt
- grep "wheels" car.txt
Pour définir l'ordre d'exécution des jobs, vous devez spécifier l'ordre dans le tableau "stages". Chaque job comprend un identifiant "stage" qui lui est associé.
Félicitations, vous venez de créer votre première pipeline ! Vous pouvez "puller" la branche pour tester tout le code.
Maintenant, il est important de comprendre les runners de GitLab. Les runners sont des agents qui permettent d'exécuter les jobs de la pipeline sur une machine distante. Les runners peuvent être partagés entre différents projets ou réservés à un seul projet. Les runners peuvent également être hébergés sur votre propre infrastructure ou sur l'infrastructure de GitLab.
Les runners
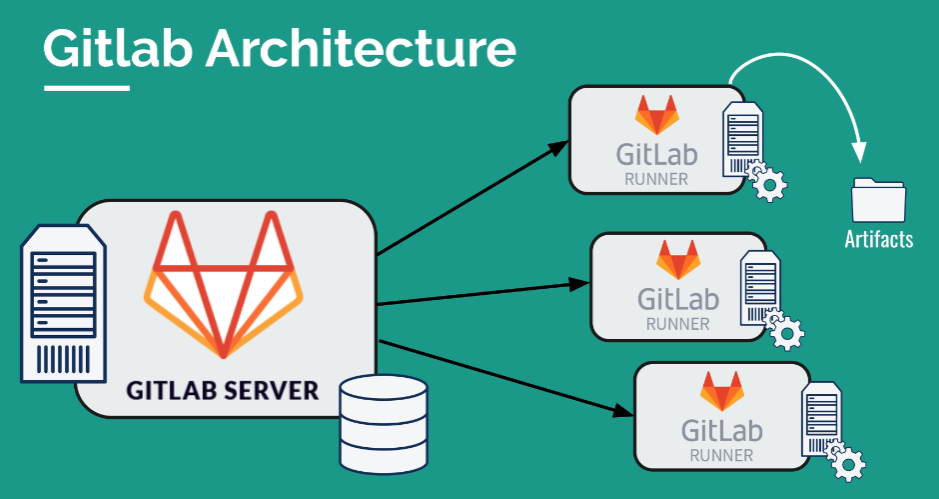
Le serveur de GitLab est un élément clé de son architecture. Chacune de nos actions est enregistrée dans une base de données et chaque pipeline est lancé par un service appelé "GitLab Runner". GitLab Runner permet de lancer les pipelines, y compris la sauvegarde des artifacts. Nous pouvons lancer un grand nombre de runners pour assurer la scalabilité, mais aussi pour répondre à des demandes spécifiques des pipelines qui ne sont pas nécessaires pour les autres.
Le "coordinator" est le composant responsable de l'accueil des fichiers générés par les pipelines.
Pour partager des runners, vous pouvez accéder à la page "Settings" -> "CI/CD" -> "Runners" -> "expands". Sur cette page, vous pouvez configurer vos runners en ajoutant de nouveaux runners, en créant des spécifications et en désactivant la possibilité de partager les runners.
CI/CD
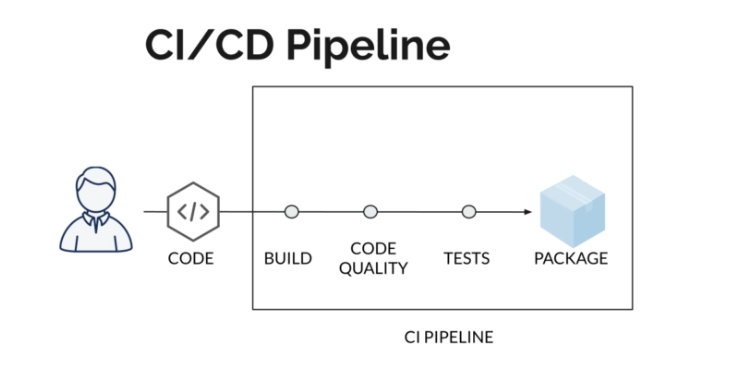
Historiquement, lorsqu'on déployait une nouvelle version d'un projet, la plupart des tâches étaient effectuées manuellement. Aujourd'hui, les temps ont changé.
La Continuous Integration (CI) signifie que chaque fois que vous modifiez votre code, cette modification doit être intégrée au serveur CI. Pendant cette intégration, vous devez vous assurer que le projet continue à compiler et répond aux critères suivants :
- Tests fonctionnels
- Vérification des normes de sécurité (dépendances, etc.)
- Guidelines
- Conformité du code
Ainsi, CI permet d'automatiser le processus d'intégration, visant à assurer la stabilité du projet et à livrer de nouvelles fonctionnalités rapidement. Cela permet également de réagir rapidement aux problèmes qui pourraient survenir à l'avenir.
La Continuous Deployment (CD) garantit que chaque changement est déployé tout en délivrant de la valeur le plus rapidement possible et en réduisant le risque de nouveaux déploiements. Voici à quoi ressemble notre système :
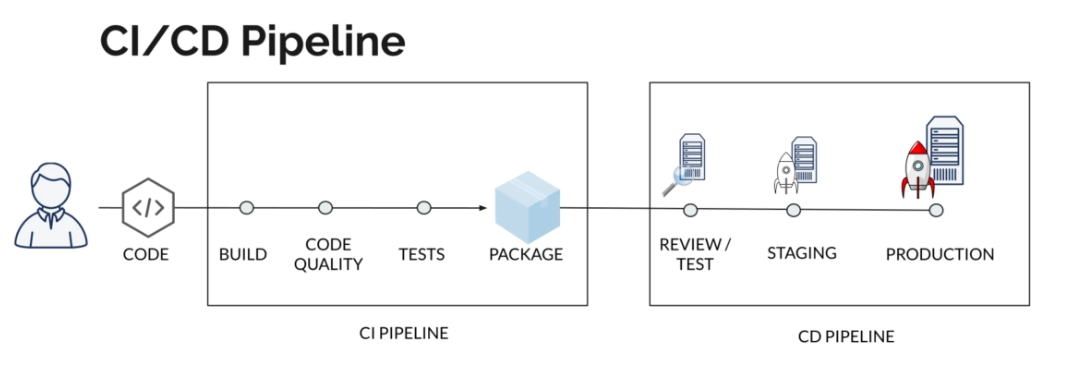
CI/CD Workflow
Git branch: CI/CD Workflow
Dans cet exercice, nous allons :
- Builder un projet en utilisant NPM
- Compiler cette image dans une image Docker
- Créer une pipeline GitLab CI/CD
- Créer des jobs en parallèle et en arrière-plan
- Déployer le projet avec surge.sh
- Utiliser des variables d'environnement pour gérer les données sensibles.
Nous allons créer un nouveau projet basé sur Gatsby. Veuillez suivre les instructions du lien ci-dessus pour installer localement Gatsby dans votre référentiel. Une fois que la génération du projet est terminée, vous pouvez lancer le serveur local et voir :
À ce stade, nous souhaitons créer un pipeline pour builder le projet directement à travers GitLab CI. Nous allons donc créer un fichier ".gitlab-ci.yml". Pour builder l'application, nous pouvons utiliser la commande "npm run build" qui se trouve dans la documentation de l'application "node.js" dans le fichier package.json.
Cependant, il est important d'installer les bibliothèques nécessaires avant de pouvoir les utiliser. Notre premier test aura donc cette forme :
build website:
script:
- npm install
- npm run build
Le fichier ".gitlab-ci.yml" que nous avons créé précédemment n'est pas suffisant. Par défaut, nous utilisons l'image "ruby:2.5", ce qui n'est pas adapté pour notre projet. Nous devons donc changer cette image pour une image Docker qui contient déjà Node.
Il est recommandé de fixer la version de l'image afin d'éviter tout problème de compatibilité avec l'image utilisée. Nous allons donc créer une image Docker spécifique pour notre projet.
build website:
image: node:16
script:
- cd my-gatsby-site
- npm install
- npm run build
Le résultat est sans appel, notre projet est compilé avec succès ! 🎉 Cependant, cela a pris plus de temps que de le compiler avec Jenkins. Cela est dû au fait que GitLab CI ne conserve rien en mémoire après chaque job.
Nous devons donc utiliser les "artifacts" pour conserver notre version compilée. En effet, il serait dommage de perdre notre version build.
build website:
image: node:16
script:
- cd my-gatsby-site
- npm install
- npm run build
artifacts:
paths:
- ./public
Maintenant que le build est terminé, GitLab CI doit garantir que les tests et les autres critères vérifiables sont réussis. Pour qu'un job échoue, le statut doit être différent de 0. C'est exactement ce que retournera la commande "npm run test" si les tests unitaires ne fonctionnent pas, ou n'importe quelle commande UNIX qui ne fonctionne pas ou ne trouve pas de résultat.
Dans notre cas, nous allons vérifier la présence d'une chaîne de caractères dans notre fichier "index.html". Cela est juste un exemple.
stages:
- build
- test
build website:
stage: build
image: node:16
script:
- cd my-gatsby-site
- npm install
- npm run build
artifacts:
paths:
- ./public
test artifacts:
stage: test
script:
- grep -q "Gatsby" ./public/index.html
Nous avons ajouté les stages pour que notre test ait lieu après le build. Nous avons également spécifié une image Docker pour nos tests afin de ne pas utiliser l'image Ruby que nous avons utilisée précédemment.
Nous pouvons également créer des builds en parallèle. Dans cet exemple, nous allons lancer le serveur de rendu proposé par Gatsby en utilisant la commande "npm run serve" pour avoir une meilleure idée du rendu final. Si vous souhaitez tester que les tests peuvent échouer, vous pouvez modifier les chaînes de caractères.
stages:
- build
- test
build website:
stage: build
image: node
script:
- npm install
- npm install -g gatsby-cli
- gatsby build
artifacts:
paths:
- ./public
test artifact:
image: alpine
stage: test
script:
- grep -q "Gatsby" ./public/index.html
test website:
image: node
stage: test
script:
- npm install
- npm install -g gatsby-cli
- gatsby serve
- curl "http://localhost:9000" | grep -q "Gatsby"
Si vous avez suivi la formation, tout ceci ne devrait pas vous paraître sorcier. Nous allons maintenant lancer le site et vérifier qu'il contient bien la chaîne de caractères souhaitée.
Nous pouvons voir notre build en parallèle directement dans GitLab, grâce aux étapes que nous avons ajoutées dans notre fichier ".gitlab-ci.yml".
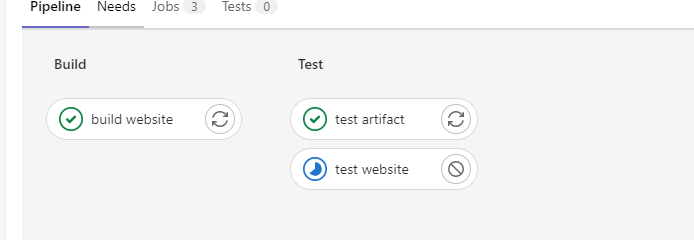
Nous sommes maintenant capables de lancer plusieurs tests en même temps, ce qui nous permet de diviser la complexité et d'optimiser le temps nécessaire pour exécuter certains jobs.
Cependant, nous avons constaté que notre script actuel ne fonctionne pas. En effet, notre serveur est lancé mais nous ne le fermons pas. Cela peut entraîner un temps d'attente d'environ une heure avant que GitLab ne le ferme et ne fasse échouer le job.
Si nous voulons fermer le serveur, nous devons d'abord lancer le serveur, attendre qu'il se lance, puis créer notre test.
test website:
image: node
stage: test
script:
- cd ./my-gatsby-site
- npm install
- npm run serve &
- sleep 3
- curl "http://localhost:9000" | tac | tac | grep -q "Gatsby"
Dans ce cas, le symbole "&" nous permet de passer à la commande suivante sans attendre la fin de l'exécution de la commande en cours. Ce n'est pas la meilleure façon de faire, mais cela nous donne un exemple concret de la façon de passer à une étape suivante et de laisser un job s'exécuter en arrière-plan.
Nous allons maintenant déployer notre application en utilisant Surge, qui est une plateforme cloud pour le déploiement d'applications serverless. C'est facile à configurer et à utiliser, et c'est idéal pour les sites statiques.
Je vous invite à suivre le guide d'installation comme précédemment et à poursuivre la formation après. Une fois que vous l'avez installé, vous pouvez lancer le mini-serveur avec la commande correspondante.
surge
Félicitations ! N'oubliez pas vos identifiants, nous allons en avoir besoin. En appuyant sur la touche "Entrée", vous devriez voir que votre mini-serveur est disponible. C'est un bon début, mais maintenant nous devons transmettre des données sensibles à notre script de déploiement.
La solution consiste à utiliser des variables d'environnement ! Avec Surge, nous pouvons récupérer un jeton (token) :
surge token
Cela nous donnera un jeton que nous pouvons directement ajouter à GitLab :
Settings -> CI/CD -> Variables -> Expand -> Ajouter une variable -> key: SURGE_LOGIN -> value: votre adresse email Ajouter une variable -> SURGE_TOKEN -> votre jeton -> Masquer la variable
Et voilà, nous avons réussi ! Maintenant, nous allons automatiser notre déploiement. Nous allons avoir plusieurs images qui utilisent l'image de Node. Nous pouvons rendre cette image par défaut pour tous les jobs en la mettant en haut du fichier. Ne vous inquiétez pas, les images différentes à utiliser doivent être spécifiées dans chacun des jobs.
stages:
- build
- test
- deploy
deploy to surge:
stage: deploy
script:
- npm install --global surge
- surge --project ./my-gatsby-site/public --domain curious-shock.surge.sh
Comme nous avons défini nos variables dans GitLab, nous n'avons pas besoin de spécifier nos identifiants, GitLab le fera automatiquement.





